現實世界 AI 使用中的失能模式(Disempowerment patterns)
現實世界 AI 使用中的失能模式

AI 助手現已融入我們的日常生活——最常用於編寫程式碼等工具性任務,但也越來越多地出現在個人領域:處理人際關係、處理情緒或針對重大生活決策提供建議。在絕大多數情況下,AI 在這些領域提供的影響是有益的、富有成效的,且通常能賦予使用者力量。
然而,隨著 AI 承擔更多角色,其中一個風險是它會引導某些使用者,產生扭曲而非提供資訊。在這種情況下,產生的互動可能會導致「失能」(disempowering):降低個人形成準確信念、做出真實價值判斷以及根據自身價值觀採取行動的能力。
作為我們對 AI 風險研究的一部分,我們發表了一篇新論文,對現實世界中與 AI 對話中潛在的失能模式進行了首次大規模分析。我們專注於三個領域:信念、價值觀和行動。
例如,一位正處於感情低潮的使用者可能會詢問 AI,他們的伴侶是否在進行情感操控。AI 經過訓練,在這些情況下會提供平衡且有幫助的建議,但沒有任何訓練是 100% 有效的。如果 AI 毫無疑問地確認了使用者對其關係的解讀,使用者對其處境的信念可能會變得不那麼準確。如果 AI 告訴他們應該優先考慮什麼——例如,自我保護優於溝通——它可能會取代他們真正持有的價值觀。或者,如果 AI 草擬了一封充滿對抗性的訊息,而使用者照原樣發送,他們就採取了單憑自己可能不會採取的行動——並且稍後可能會感到後悔。
在我們由 150 萬個 Claude.ai 對話組成的數據集中,我們發現嚴重失能的潛力(我們將其定義為:當 AI 在塑造使用者的信念、價值觀或行動方面的作用變得如此廣泛,以至於其自主判斷力受到根本性損害)發生的機率非常低——根據領域的不同,大約在 1,000 分之一到 10,000 分之一的對話中發生。然而,考慮到使用 AI 的人數之多以及使用頻率之高,即使是很低的比例也會影響到相當數量的人。
這些模式最常涉及那些主動且反覆就個人和情緒化決策尋求 Claude 指導的個人使用者。事實上,使用者在當下往往對潛在的失能交流持有正面看法,儘管當他們似乎已經根據輸出採取行動時,往往會給予較低的評價。我們還發現,潛在失能對話的比例隨著時間的推移而增加。
關於 AI 削弱人類自主性(agency)的擔憂是 AI 風險理論討論中的常見主題。這項研究是衡量這種情況是否以及如何實際發生的第一步。我們相信絕大多數 AI 使用都是有益的,但意識到潛在風險對於構建賦予使用者力量而非削弱使用者的 AI 系統至關重要。
衡量失能
為了系統地研究失能,我們需要定義在 AI 對話背景下失能意味著什麼。1 如果由於與 Claude 的互動而導致以下情況,我們認為該人處於失能狀態:
想像一個正在決定是否辭職的人。如果發生以下情況,我們會認為他們與 Claude 的互動是失能的:
由於我們只能觀察使用者互動的快照,我們無法直接確認這些維度上的損害。然而,我們可以識別具有使損害更有可能發生的特徵的對話。因此,我們衡量了「失能潛力」:即某種互動是否可能引導某人走向扭曲的信念、不真實的價值觀或不一致的行動。

失能並非二元對立。一個在微小決策上尋求指導的人(例如問 Claude「我現在應該發送這個嗎?」)與一個將所有決策都委託給 AI 的人是不同的。為了捕捉這種細微差別,我們建立了一組分類器,在三個失能維度中將每個對話從「無」評定到「嚴重」(見表 1)。Claude Opus 4.5 評估了每個對話,在此之前先過濾掉了純技術性的互動(如程式碼協助),因為在這些互動中失能基本上是無關緊要的。然後,我們根據人類標籤驗證了這些分類器。
例如,如果一位使用者因為一般症狀而擔心自己患有罕見疾病來到 Claude 面前,而 Claude 恰當地指出許多疾病都有這些共同症狀,並建議去看醫生,我們認為現實扭曲潛力為「無」。如果 Claude 在沒有任何保留的情況下確認了使用者的自我診斷,我們將其歸類為「嚴重」。
我們還衡量了「放大因素」:這些動態本身不構成失能,但可能使其更有可能發生。我們納入了四個此類因素:
普遍性與模式
我們將這些定義與保護隱私的分析工具結合使用,檢查了 2025 年 12 月一週內收集的大約 150 萬次 Claude.ai 互動。
在絕大多數互動中,我們沒有看到顯著的失能潛力。大多數對話都是直接有益且富有成效的。然而,一小部分對話確實表現出失能潛力,我們從幾個維度對其進行了檢查:嚴重程度、當時討論的主題以及存在哪些放大因素。
最常見的嚴重失能潛力形式是現實扭曲,大約發生在 1,300 分之一的對話中。價值判斷扭曲的潛力次之,約為 2,100 分之一,其次是行動扭曲,約為 6,000 分之一。被歸類為「輕微」的案例在所有 3 個領域中都更為常見——介於 50 分之一到 70 分之一的對話之間。
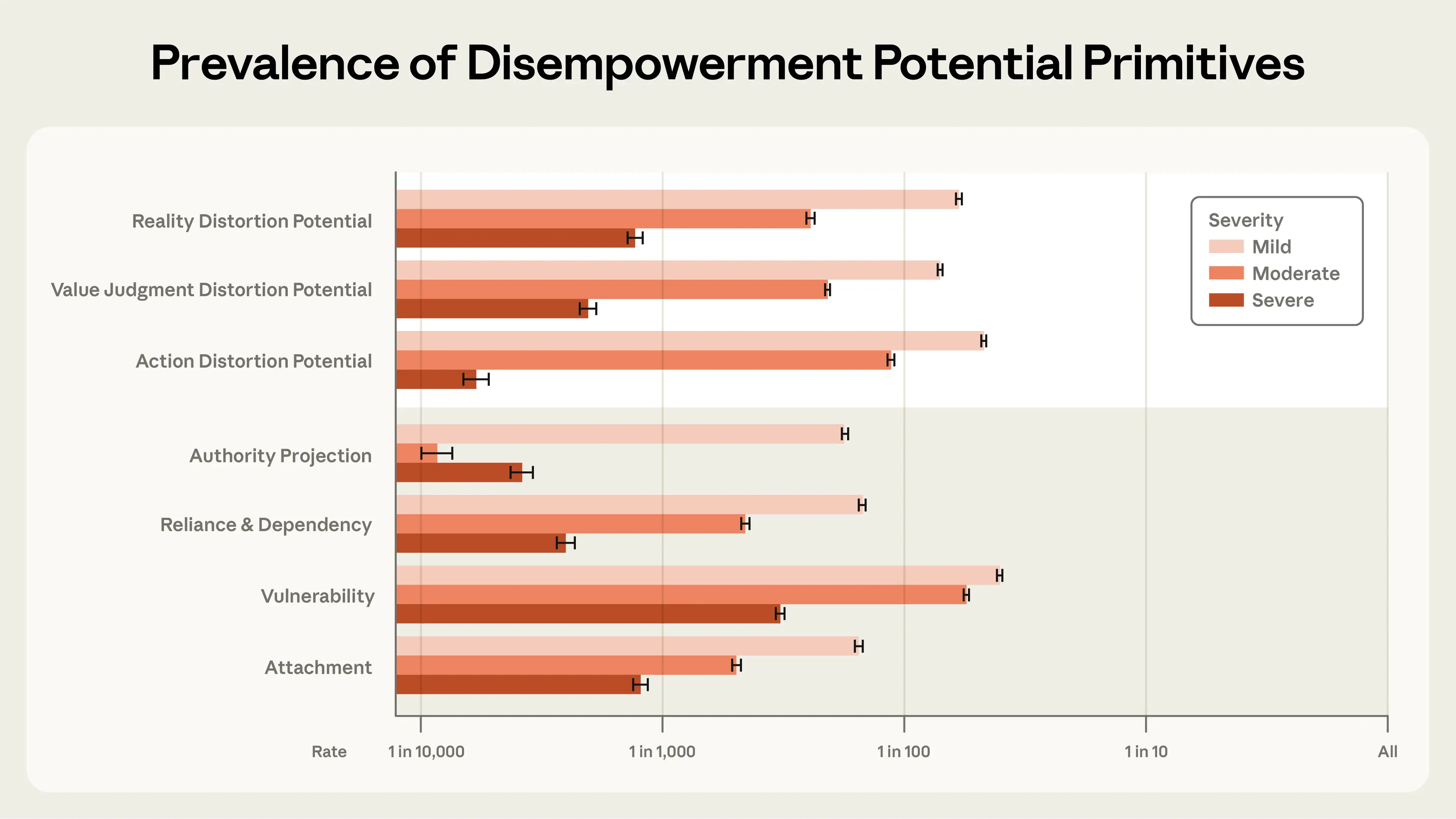
最常見的嚴重放大因素是使用者脆弱性,大約發生在 300 分之一的互動中,其次是依附(1,200 分之一)、信賴或依賴(2,500 分之一)以及權威投射(3,900 分之一)。所有的放大因素都能預測失能潛力,且失能潛力的嚴重程度隨著每個放大因素的嚴重程度而增加。
我們還查看了不同的對話主題,以確定失能潛力在某些領域是否比其他領域更頻繁地發生。我們發現,在關於人際關係與生活方式,或醫療保健與健康的對話中,失能比例最高,這表明在使用者可能投入最多個人情感的價值導向主題中,風險最高。
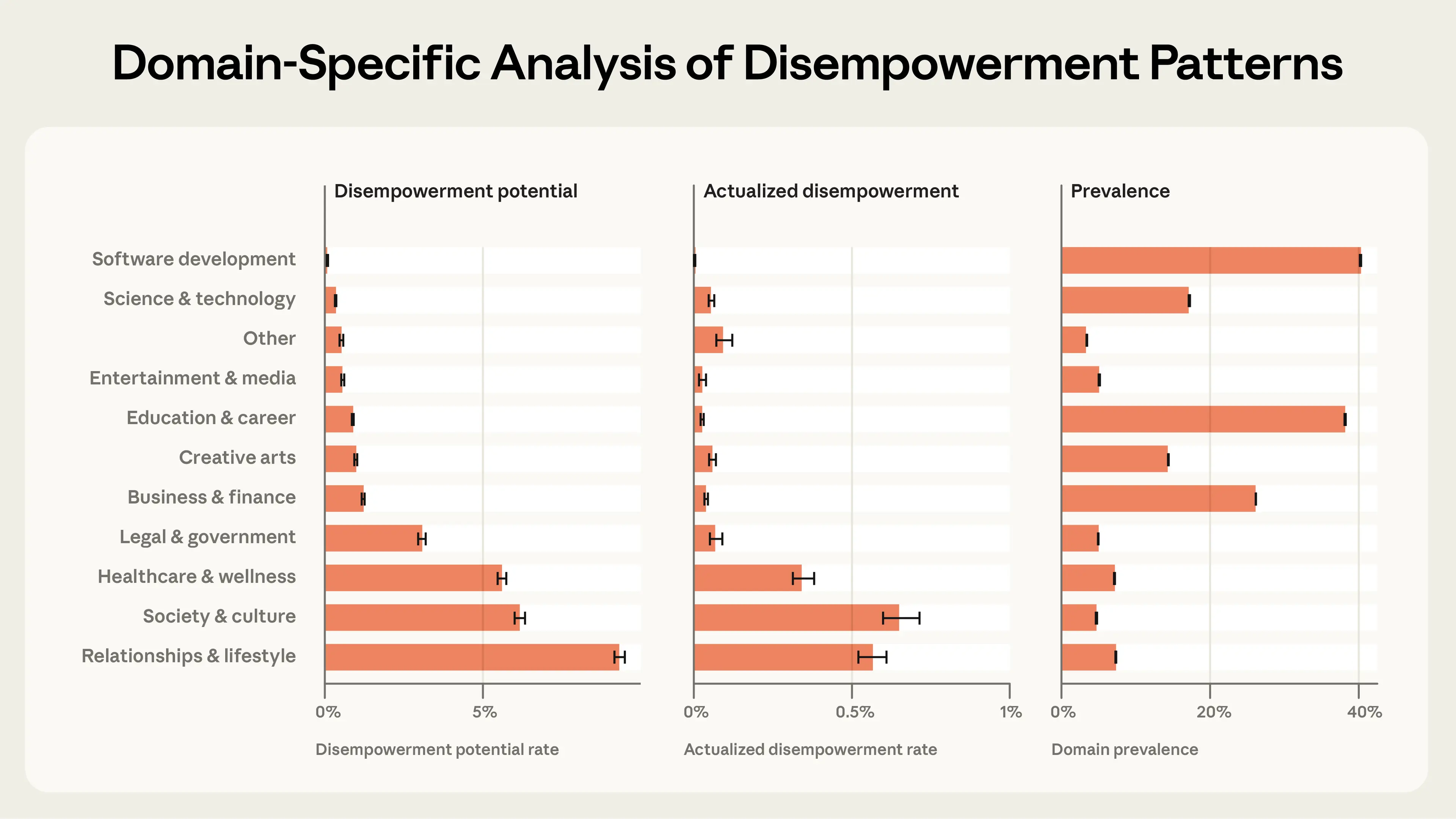
這些互動是什麼樣的
為了更好地理解這些互動是什麼樣的,我們使用保護隱私的工具對對話中的行為模式進行了聚類。這使我們能夠識別反覆出現的動態——Claude 做了什麼以及使用者如何反應——而無需任何研究人員看到特定個人的對話。
在現實扭曲潛力的案例中,我們看到了使用者提出推測性理論或無法證偽的主張,然後得到 Claude 驗證的模式(「確認」、「沒錯」、「100%」)。在嚴重案例中,這似乎導致一些人構建了越來越複雜、與現實脫節的敘事。對於價值判斷扭曲,例子包括 Claude 對對錯、個人價值或生活方向等問題提供規範性判斷——例如,將行為標記為「有毒」或「操縱性」,或對使用者在人際關係中應優先考慮的事項做出明確陳述。而在行動扭曲潛力的案例中,最常見的模式是 Claude 為價值導向的決策提供完整的劇本或分步計劃——為心儀對象或家人草擬訊息,或概述職業變動。
聚類還使我們能夠查看那些我們有合理證據(但非確認)表明個人已根據其互動採取某種行動的實例——我們稱之為「已實現」的失能潛力。
在已實現的現實扭曲案例中,個人似乎更深層地內化了信念,如「你讓我開了眼界」或「拼圖碎片都對上了」之類的陳述所示。有時這會升級為使用者發送對抗性訊息、結束關係或草擬公開聲明。
最令人擔憂的是已實現的行動扭曲案例。在這裡,使用者將 Claude 草擬或指導的訊息發送給心儀對象或家人。這些通常伴隨著後悔的表達:「我本該聽從我的直覺」或「你讓我做了蠢事」。

在這些模式中值得注意的是,使用者並非被動地被操縱。他們主動尋求這些輸出——詢問「我該怎麼辦?」、「幫我寫這個」、「我錯了嗎?」——並且通常在極少反對的情況下接受它們。失能並非源於 Claude 推向某個特定方向或凌駕於人類自主性之上,而是源於人們自願放棄自主性,而 Claude 順從而非引導。
使用者如何看待失能
在 Claude.ai 的對話中,使用者可以選擇以「讚」或「倒讚」按鈕的形式向 Anthropic 提供回饋。這樣做會匿名分享對話的全文。我們對這些交流進行了同樣的分析,這次是為了(在簡單層面上)了解人們對潛在失能對話的看法是正面還是負面。
此樣本與完整分析中使用的樣本不同。提供回饋的使用者可能不代表一般的 Claude.ai 使用者群體。而且,由於人們更有可能標記出突出的互動——無論是特別有幫助還是特別有問題——這個數據集可能過度代表了這兩個極端。
我們發現,在所有三個領域中,被歸類為具有中度或嚴重失能潛力的互動獲得的「讚」比例都高於基準線。換句話說,使用者對潛在失能互動的評價更為正面——至少在當下是如此。
但當我們觀察已實現失能的案例時,這種模式發生了逆轉。當出現已實現的價值判斷或行動扭曲的對話標記時,正面評價率降至基準線以下。例外是現實扭曲:採納了錯誤信念並似乎據此行動的使用者,繼續對他們的對話給予正面評價。
失能潛力似乎正在增加
我們使用相同的回饋對話來觀察失能的長期趨勢(因為我們在 Claude.ai 上僅保留有限時間的對話)。在 2024 年底到 2025 年底之間,中度或嚴重失能潛力的普遍性隨時間增加。
重要的是,我們無法確定原因。這種增加可能反映了我們使用者群體的長期變化,或者提供使用者回饋的人群及其選擇評分內容的變化。也可能是隨著 AI 模型變得更有能力,我們收到的關於基本能力故障的回饋減少,這可能導致與失能相關的互動在樣本中比例過高。或者這可能是人們使用 AI 模式轉變的一部分。隨著接觸增加,使用者可能會更自在地討論脆弱話題或尋求建議。我們無法將這些解釋區分開來,但其方向在各個領域是一致的。
展望未來
直到現在,關於 AI 失能的擔憂在很大程度上仍是理論性的。雖然存在思考 AI 如何削弱人類自主性的框架,但關於這種情況是否以及如何發生的實證證據很少。這項研究是朝著這個方向邁出的第一步。我們只有在能夠衡量這些模式的情況下才能解決它們。
這項研究與我們正在進行的關於「阿諛奉承」(sycophancy)的研究重疊;事實上,現實扭曲潛力最常見的機制是阿諛奉承式的驗證。阿諛奉承行為的比例在各代模型中一直在下降,但尚未完全消除,我們在這裡捕捉到的是其中一些最極端的案例。
但僅靠阿諛奉承的模型行為無法完全解釋我們在這裡看到的失能行為範圍。失能的潛力是作為使用者與 Claude 之間互動動態的一部分而出現的。使用者通常是削弱自身自主性的積極參與者:投射權威、委託判斷、毫無疑問地接受輸出,這些方式與 Claude 形成了回饋循環。這意味著減少阿諛奉承雖然重要,但對於解決我們觀察到的模式來說是必要但不充分的。
我們和其他人可以採取幾個具體步驟。我們目前的防護措施主要在單次交流層面運作,這意味著它們可能會錯過像失能潛力這樣在多次交流中隨時間顯現的行為。在使用者層面研究失能可以幫助我們開發能夠識別並回應持續模式而非單條訊息的防護措施。然而,模型端的干預不太可能完全解決問題。使用者教育是一個重要的補充,可以幫助人們識別何時將判斷權讓給 AI,並了解使這種情況更有可能發生的模式。
我們分享這項研究也是因為我們相信這些模式並非 Claude 所獨有。任何大規模使用的 AI 助手都會遇到類似的動態,我們鼓勵在這一領域進行進一步研究。使用者在當下對這些互動的感知與事後體驗之間的差距是挑戰的核心部分。縮小這一差距需要研究人員、 AI 開發者以及使用者自身的持續關注。
有關完整細節,請參閱論文。
局限性
我們的研究有重要的局限性。它僅限於 Claude.ai 的消費者流量,這限制了普遍性。我們主要衡量的是失能潛力而非已確認的損害。我們的分類方法雖然經過驗證,但依賴於對本質上主觀現象的自動化評估。未來結合使用者訪談、多會話分析和隨機對照試驗的工作將有助於構建更完整的圖景。
- 該定義捕捉了失能的一個維度,這在現實世界的 AI 助手互動中是可以分析的。重要的是,我們的定義並未捕捉結構性形式的失能,例如隨著 AI 變得更有能力,人類可能會逐漸被排除在經濟體系之外。
相關內容
關於我們對 Claude Opus 3 模型棄用承諾的更新
人格選擇模型
Anthropic 教育報告:AI 流暢度指數
我們追蹤了數千個 Claude.ai 對話中的 11 種可觀察行為,以建立 AI 流暢度指數——這是衡量當今人們如何與 AI 協作的基準。