A Dream of Spring for Open-Weight LLMs: 10 Architectures from Jan-Feb 2026
Sebastian Raschka'S Blog
A Round Up And Comparison of 10 Open-Weight LLM Releases in Spring 2026
Sebastian Raschka'S Blog
A Round Up And Comparison of 10 Open-Weight LLM Releases in Spring 2026
AI 生成摘要
這篇文章回顧並比較了2026年春季發布的10款主要開放權重大型語言模型,重點分析它們在架構上的異同,幫助讀者掌握當前模型發展的核心趨勢。
如果你本月在跟進開源權重模型的發佈時感到有些吃力,這篇文章將幫你掌握主要脈絡。
在本文中,我將按時間順序帶你了解十個主要的發佈版本,並重點關注架構的異同:
Arcee AI 的 Trinity Large (2026 年 1 月 27 日)
月之暗面 (Moonshot AI) 的 Kimi K2.5 (2026 年 1 月 27 日)
階躍星辰 (StepFun) Step 3.5 Flash (2026 年 2 月 1 日)
Qwen3-Coder-Next (2026 年 2 月 3 日)
智譜 AI (z.AI) 的 GLM-5 (2026 年 2 月 12 日)
MiniMax M2.5 (2026 年 2 月 12 日)
南北閣 (Nanbeige) 4.1 3B (2026 年 2 月 13 日)
通義千問 Qwen 3.5 (2026 年 2 月 15 日)
螞蟻集團 (Ant Group) 的 靈 (Ling) 2.5 1T & 鈴 (Ring) 2.5 1T (2026 年 2 月 16 日)
Cohere 的 Tiny Aya (2026 年 2 月 17 日)
更新 1:Sarvam 30B 與 105B (2026 年 3 月 6 日)
(註:DeepSeek V4 發佈後將會補上。)
由於涉及內容較多,我將在文中引用我之前的《大型 LLM 架構比較》文章,以獲取某些技術主題(如混合專家模型 MoE、QK-Norm、多頭潛在注意力 MLA 等)的背景資訊,以避免內容冗餘。
1 月 27 日,Arcee AI(一家我此前未曾關注的公司)開始在模型中心發佈其開源權重的 400B Trinity Large LLM 版本,以及兩個較小的變體:
其旗艦大型模型是一個擁有 400B 參數的混合專家模型 (MoE),其中活化參數為 13B。
兩個較小的變體分別是 Trinity Mini(26B 參數,3B 活化)和 Trinity Nano(6B 參數,1B 活化)。
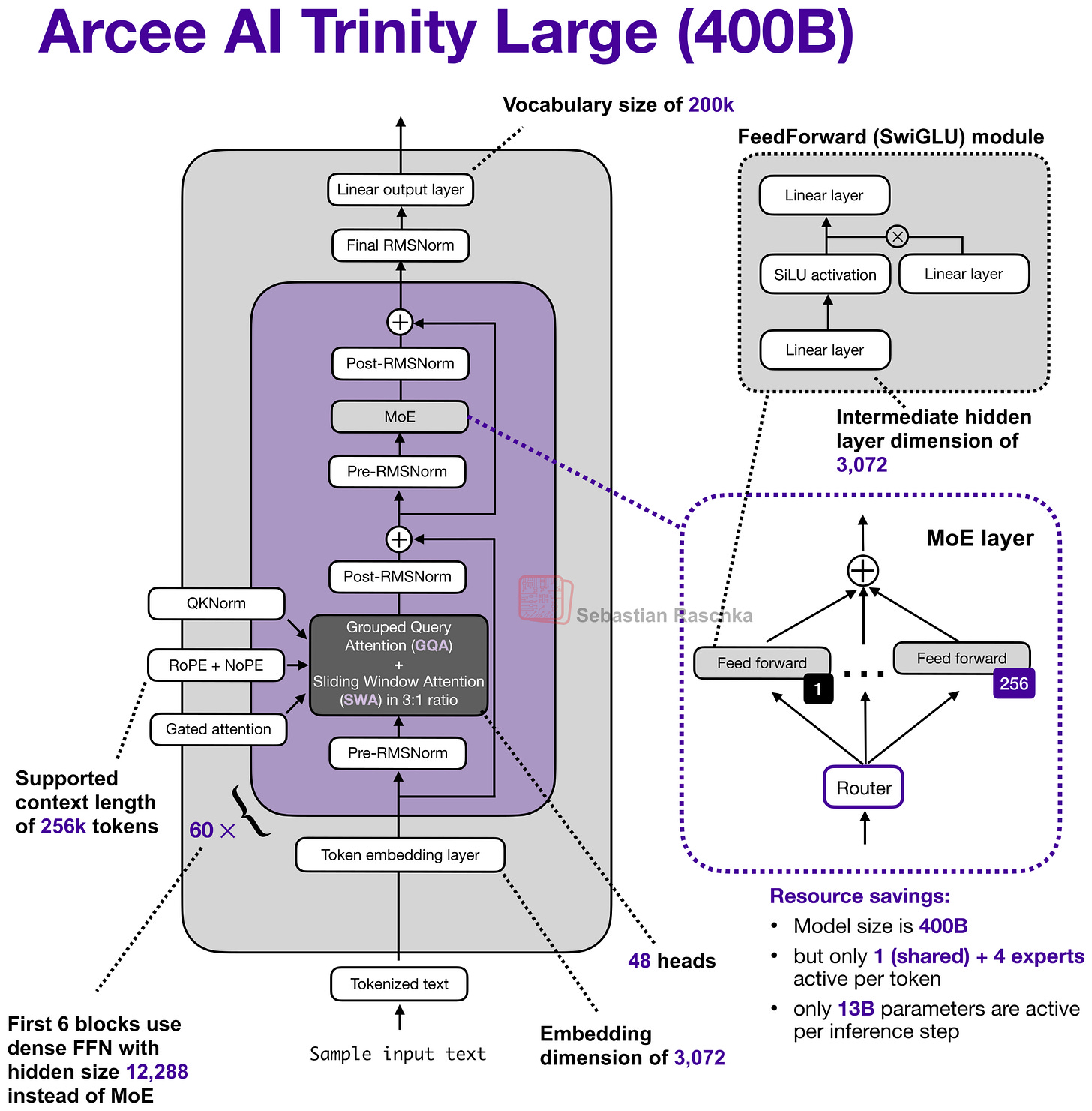
除了模型權重外,Arcee AI 還在 GitHub 上發佈了一份詳盡的技術報告(截至 2 月 18 日也已上傳至 arxiv)。
讓我們近距離觀察這款 400B 旗艦模型。下方的圖 2 將其與智譜 AI 的 GLM-4.5 進行了比較,後者因其 355B 的參數規模而成為最相似的模型。
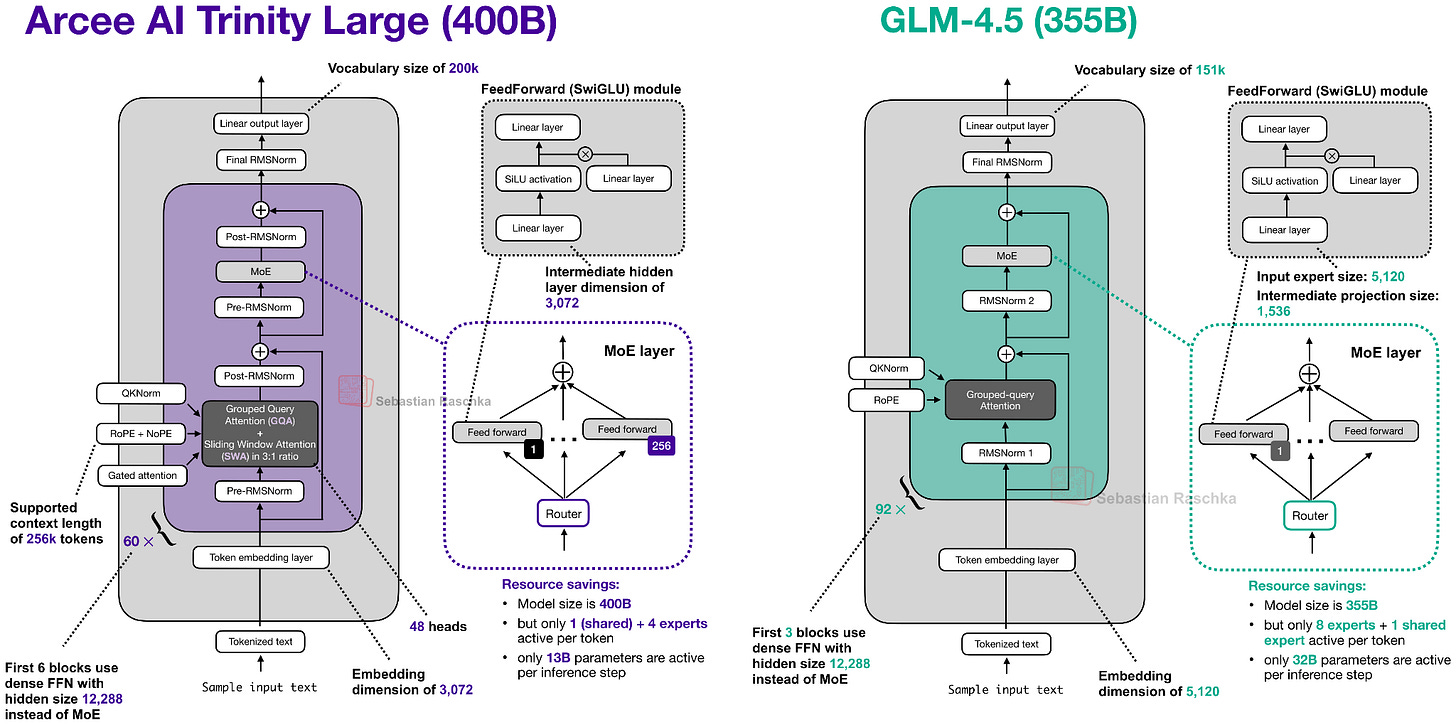
從 Trinity 與 GLM-4.5 的比較中可以看出,Trinity 模型加入了一些有趣的架構組件。
首先是交替的局部:全域(滑動窗口)注意力層 (SWA),類似於 Gemma 3、Olmo 3、小米 MiMo 等。簡而言之,SWA 是一種稀疏(局部)注意力模式,每個 token 僅關注最近 $t$ 個 token 的固定大小窗口(例如 4096),而不是關注整個輸入(輸入可能高達 $n=256,000$ 個 token)。這將每層的常規注意力成本從 $O(n^2)$ 降低到約 $O(n \cdot t)$,這也是它在長文本模型中極具吸引力的原因。
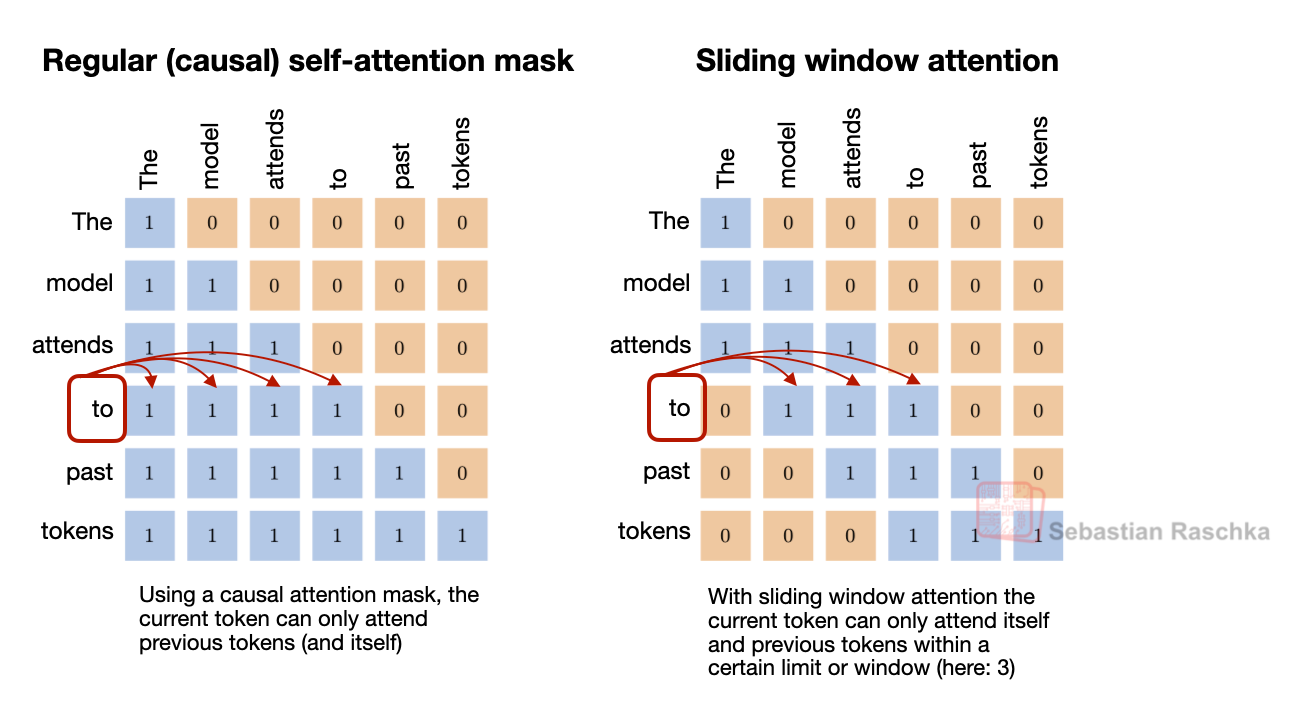
但 Arcee 團隊並未採用 Gemma 3 和小米使用的常見 5:1 局部:全域比例,而是選擇了類似於 Olmo 3 的 3:1 比例,以及相對較大的 4096 滑動窗口大小(也與 Olmo 3 相似)。
該架構還使用了 QK-Norm,這是一種對 Key 和 Query 應用 RMSNorm 以穩定訓練的技術(如下圖 4 所示),並且在全域注意力層中不使用位置嵌入 (NoPE),類似於 SmolLM3。
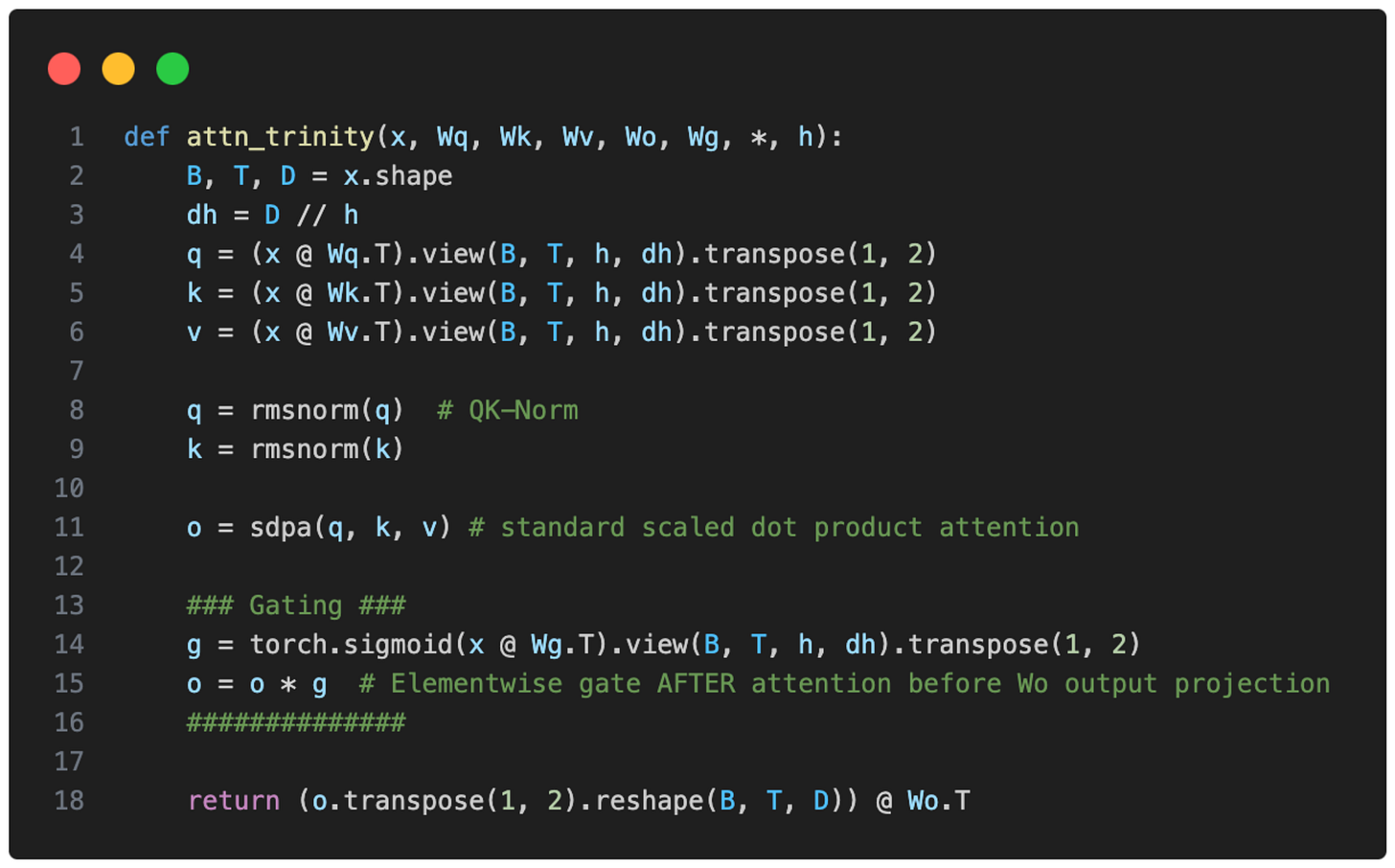
Trinity 還具有一種門控注意力 (Gated Attention) 形式。它不是完整的 Gated DeltaNet,但使用了與 Qwen3-Next 注意力機制中類似的門控。
也就是說,Trinity 團隊修改了標準注意力,在輸出線性投影前的縮放點積中加入了逐元素的門控(如下圖所示),這減少了注意力匯聚 (attention sinks) 並提高了長序列的泛化能力。此外,這也有助於訓練穩定性。
此外,Trinity 技術報告顯示,Trinity Large 和 GLM-4.5 基礎模型的建模性能幾乎完全相同(我推測他們沒有與更新的基礎模型比較,是因為現在許多公司只分享微調後的模型)。
你可能已經注意到在之前的 Trinity Large 架構圖中使用了四個(而不是兩個)RMSNorm 層,乍看之下與 Gemma 3 相似。
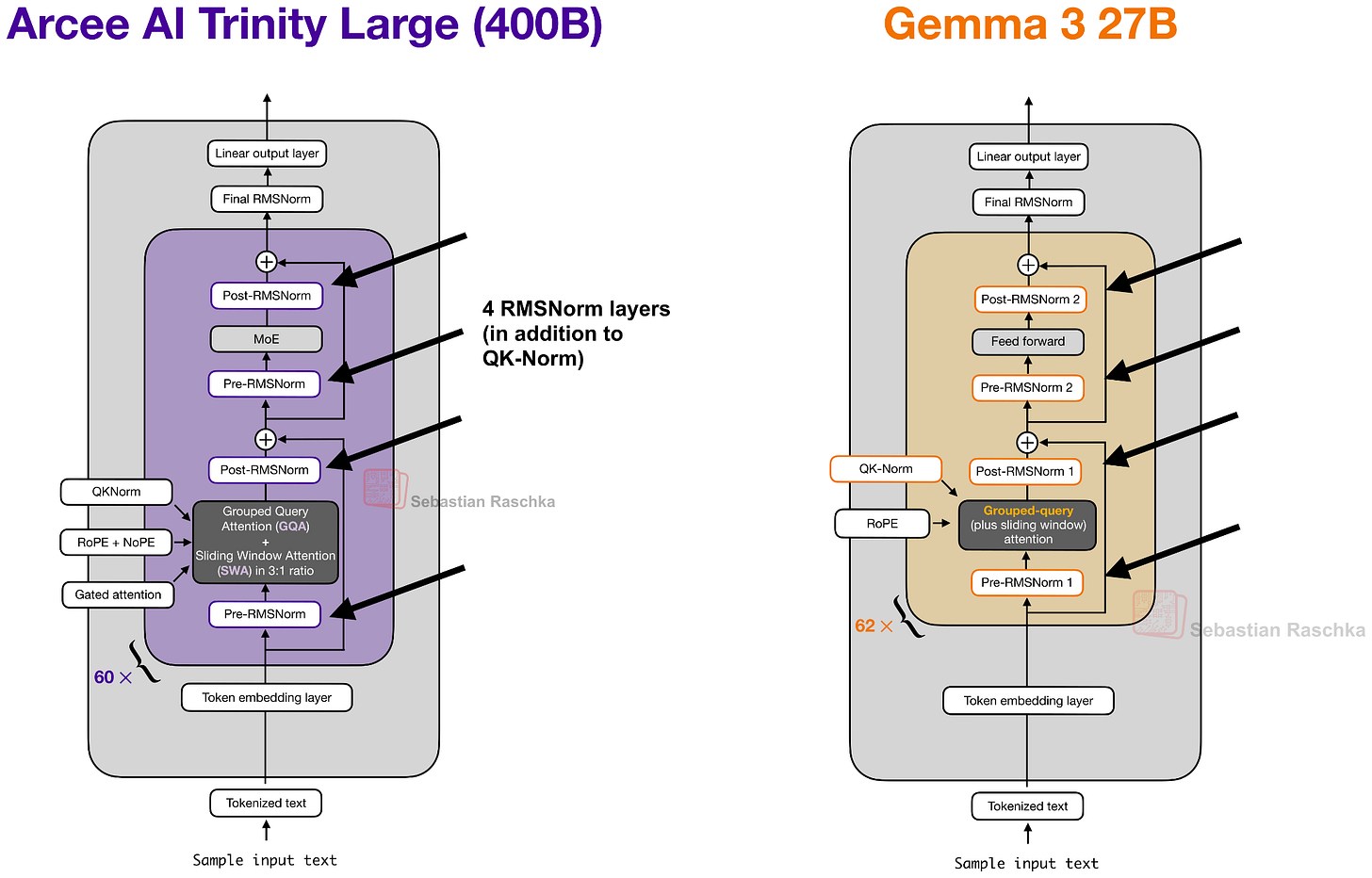
總體而言,RMSNorm 的放置位置看起來像 Gemma 3 的風格,但這裡的轉折在於(每個區塊中)第二個 RMSNorm 的增益是經過深度縮放的,這意味著它被初始化為約 $1 / \sqrt{L}$($L$ 為總層數)。因此,在訓練初期,殘差更新從較小開始,並隨著模型學習到正確的比例而增長。
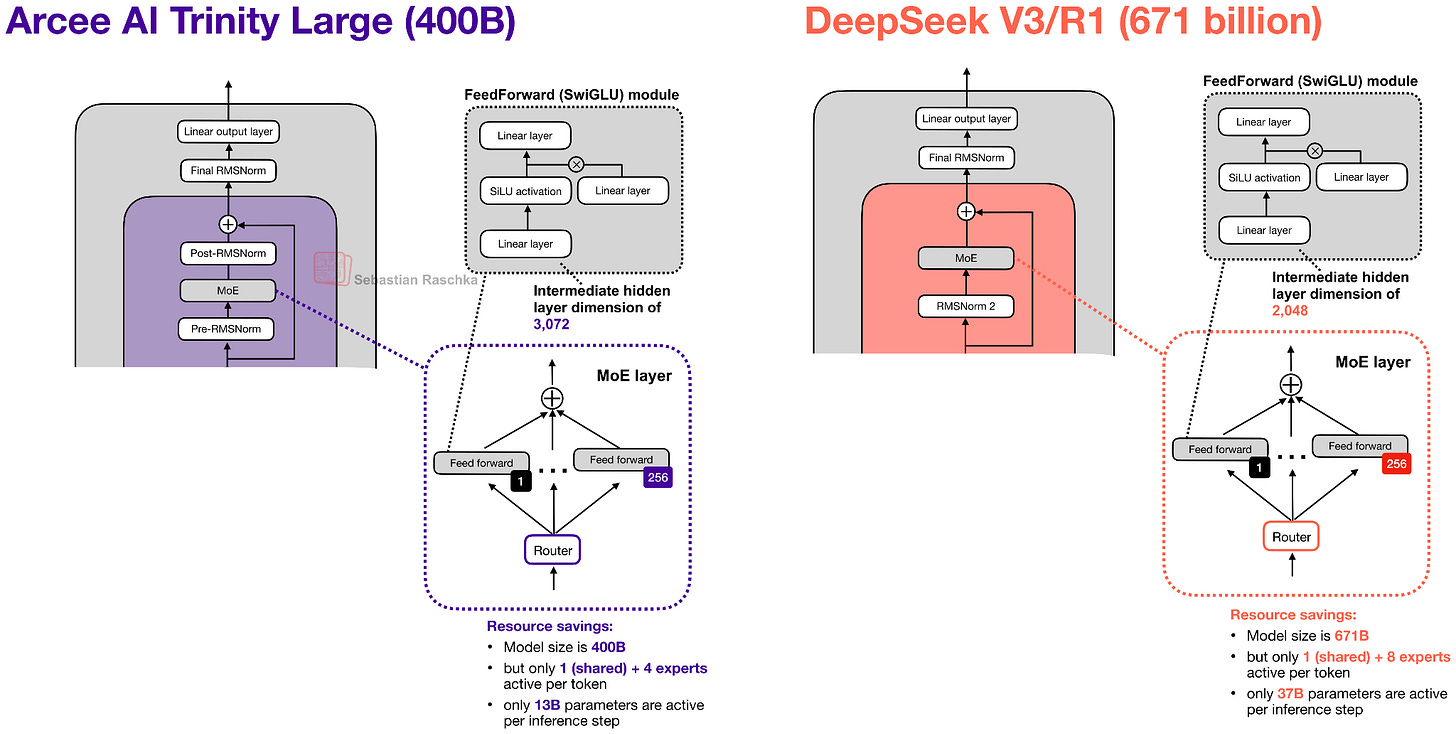
其 MoE 是類似 DeepSeek 的 MoE,擁有大量的小專家,但將其粗粒度化以幫助提高推理吞吐量(這在 Mistral 3 Large 採用 DeepSeek V3 架構時也曾見過)。
最後,訓練改進方面也有一些有趣的細節(一種新的 MoE 負載平衡策略和另一種使用 MuOpt 優化器的方法),但由於本文主要關注架構(且還有許多開源權重 LLM 要介紹),這些細節不在討論範圍內。
雖然 Arcee Trinity 基本上達到了較舊的 GLM-4.5 模型的建模性能,但 Kimi K2.5 是一款在 1 月 27 日發佈時創下開源權重性能新上限的模型。
令人印象深刻的是,根據其詳細技術報告中的基準測試,它在發佈時與領先的專有模型並駕齊驅。
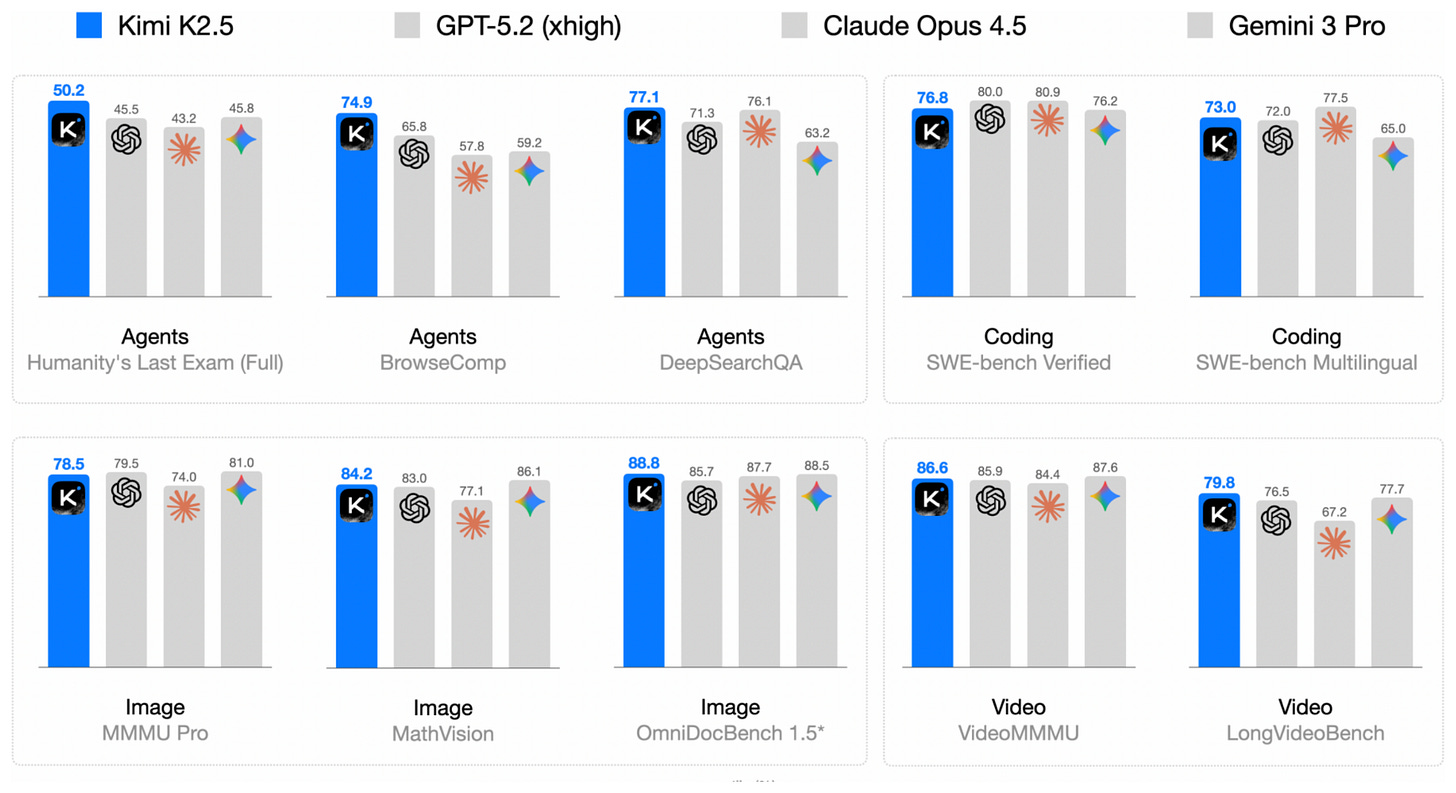
與前述的 Arcee Trinity 或 GLM-4.5 相比,良好的建模性能並不令人意外,因為(與其前身 K2 類似)Kimi K2.5 是一個擁有 1 萬億參數的模型,規模是 Trinity 的 2.5 倍,GLM-4.5 的 2.8 倍。
總體而言,Kimi K2.5 的架構與 Kimi K2 相似,而 K2 又是 DeepSeek V3 架構的放大版。
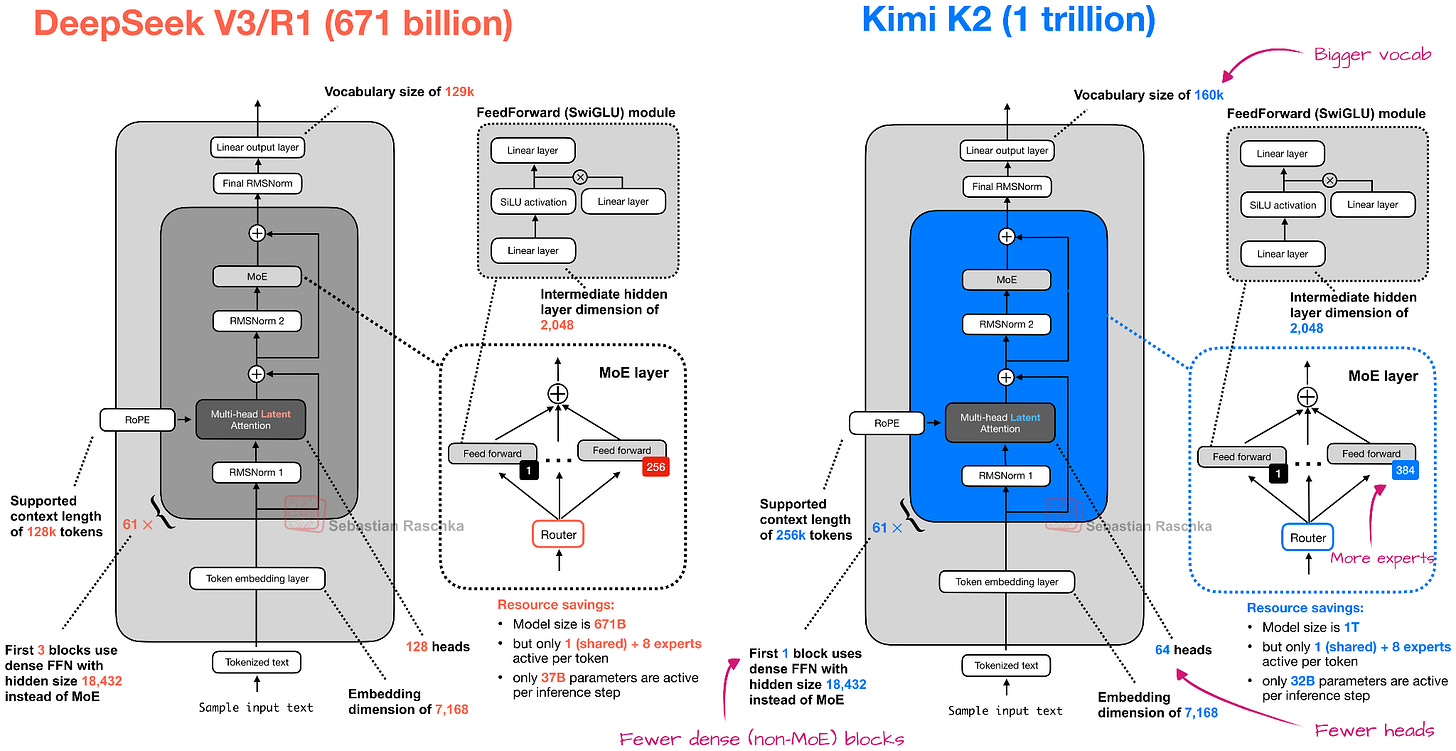
然而,K2 是一個純文本模型,而 Kimi K2.5 現在是一個支持視覺的多模態模型。引用技術報告:
Kimi K2.5 是基於 Kimi K2 構建的原生多模態模型,通過對約 15 萬億個視覺和文本混合 token 進行大規模聯合預訓練而成。
在訓練過程中,他們採用了「早期融合」(early fusion) 方法,將視覺 token 與文本 token 一起儘早傳入,正如我在之前的《理解多模態 LLM》文章中所討論的那樣。
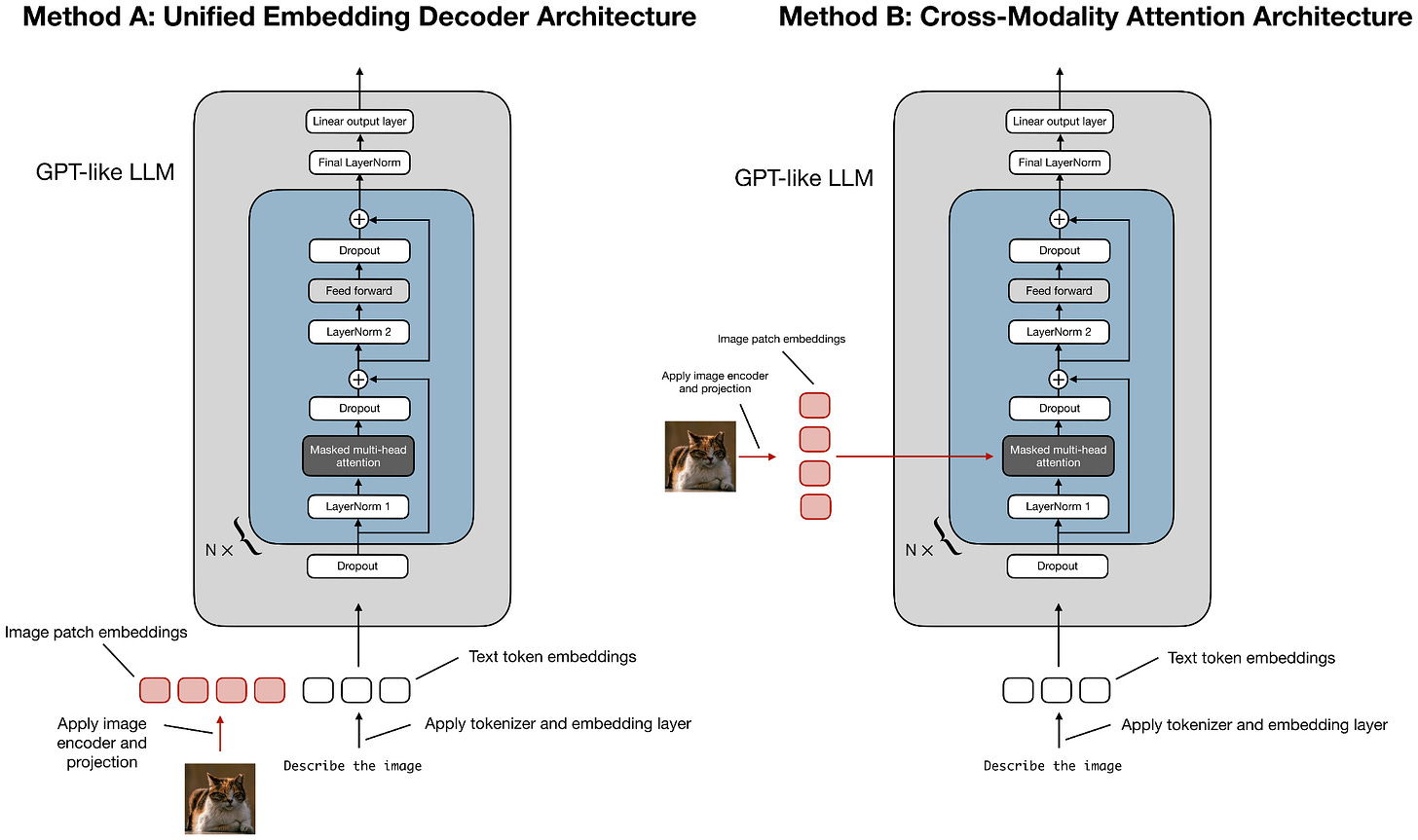
旁註:在多模態論文中,「早期融合」一詞不幸地被過度使用了。它可以指:
模型在預訓練期間何時看到視覺 token。即視覺 token 從預訓練開始(或非常早期)就混合進來,而不是在後期階段。
圖像 token 在模型中如何組合。即它們作為嵌入 token 與文本 token 並排輸入。
在這種情況下,雖然報告中的「早期融合」具體指第 1 點(預訓練期間提供視覺 token),但第 2 點在這裡也同樣成立。
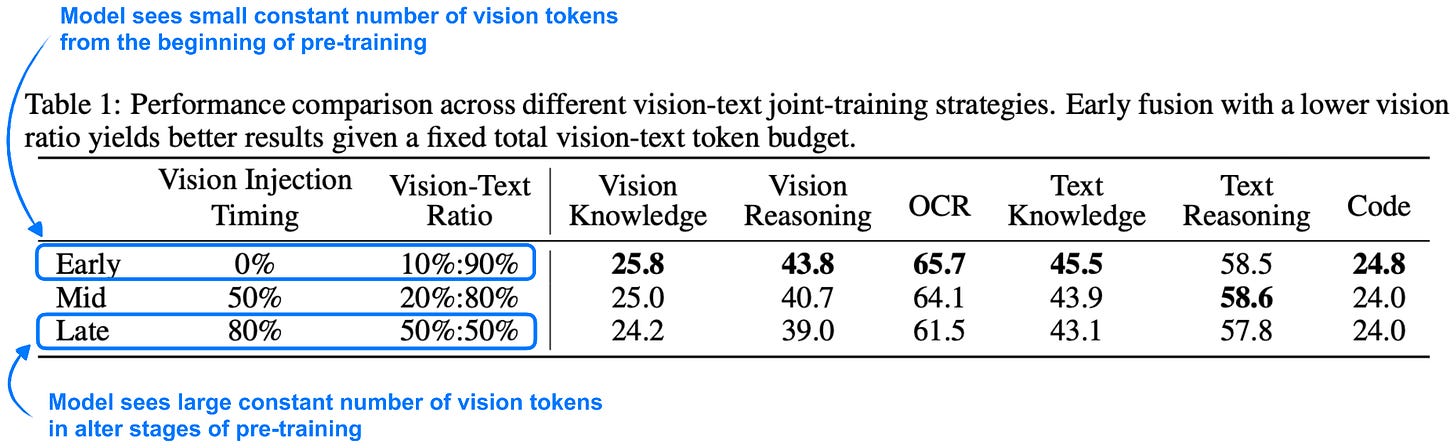
此外,關於第 1 點,研究人員包含了一項有趣的消融研究,顯示模型從預訓練早期看到視覺 token 中獲益,如下方帶註釋的表格所示。
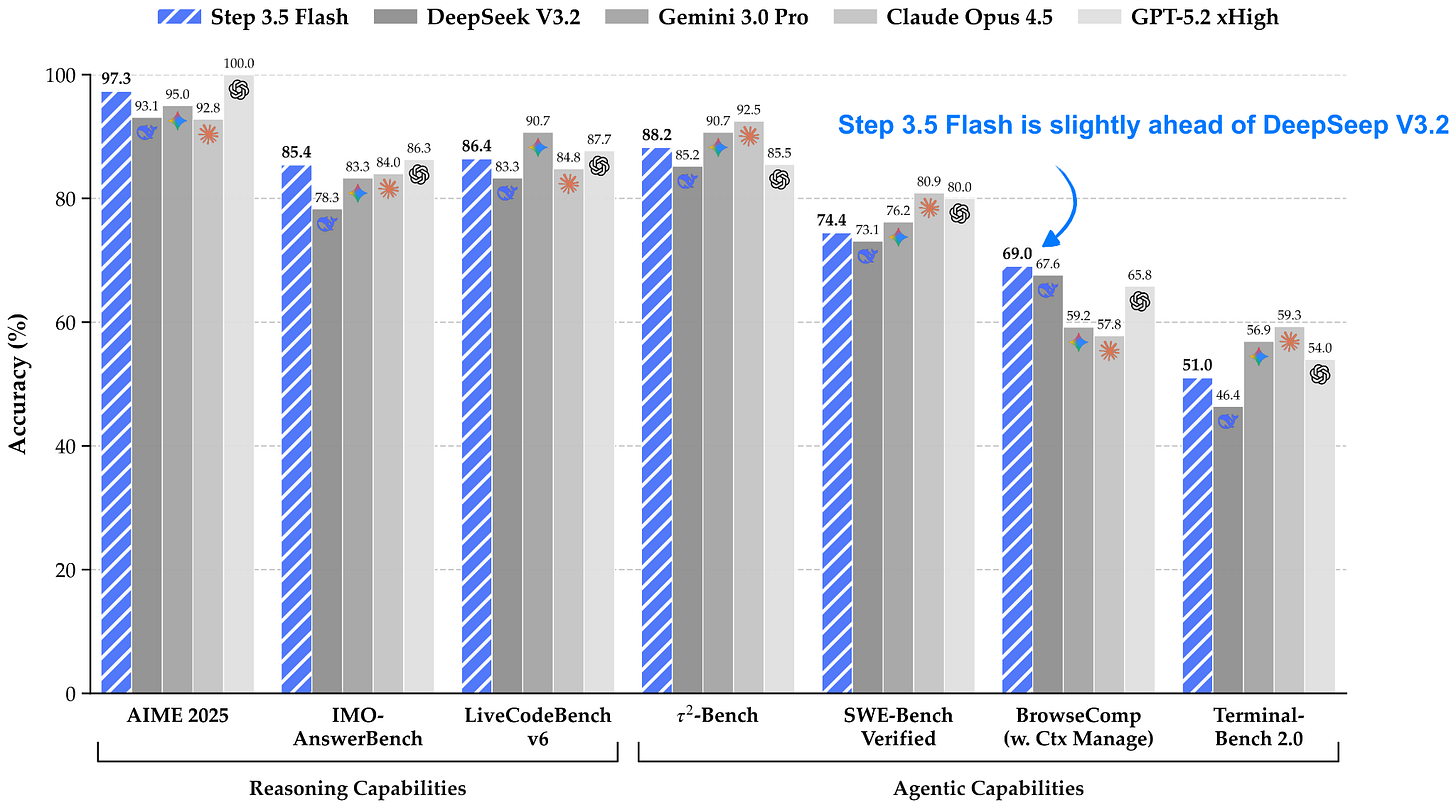
我必須承認,之前我還沒有關注過 Step 模型。這款模型因其有趣的規模、詳細的技術報告以及快速的 token/sec 表現引起了我的注意。
Step 3.5 Flash 是一個 196B 參數的模型,比最近的 DeepSeek V3.2 模型 (671B) 小 3 倍以上,但在建模性能基準測試中略微領先。根據 Step 團隊的說法,Step 3.5 Flash 在 128k 上下文長度下擁有 100 tokens/sec 的吞吐量,而根據 Step 模型中心頁面的數據,DeepSeek V3.2 在 Hopper GPU 上僅有 33 tokens/sec 的吞吐量。
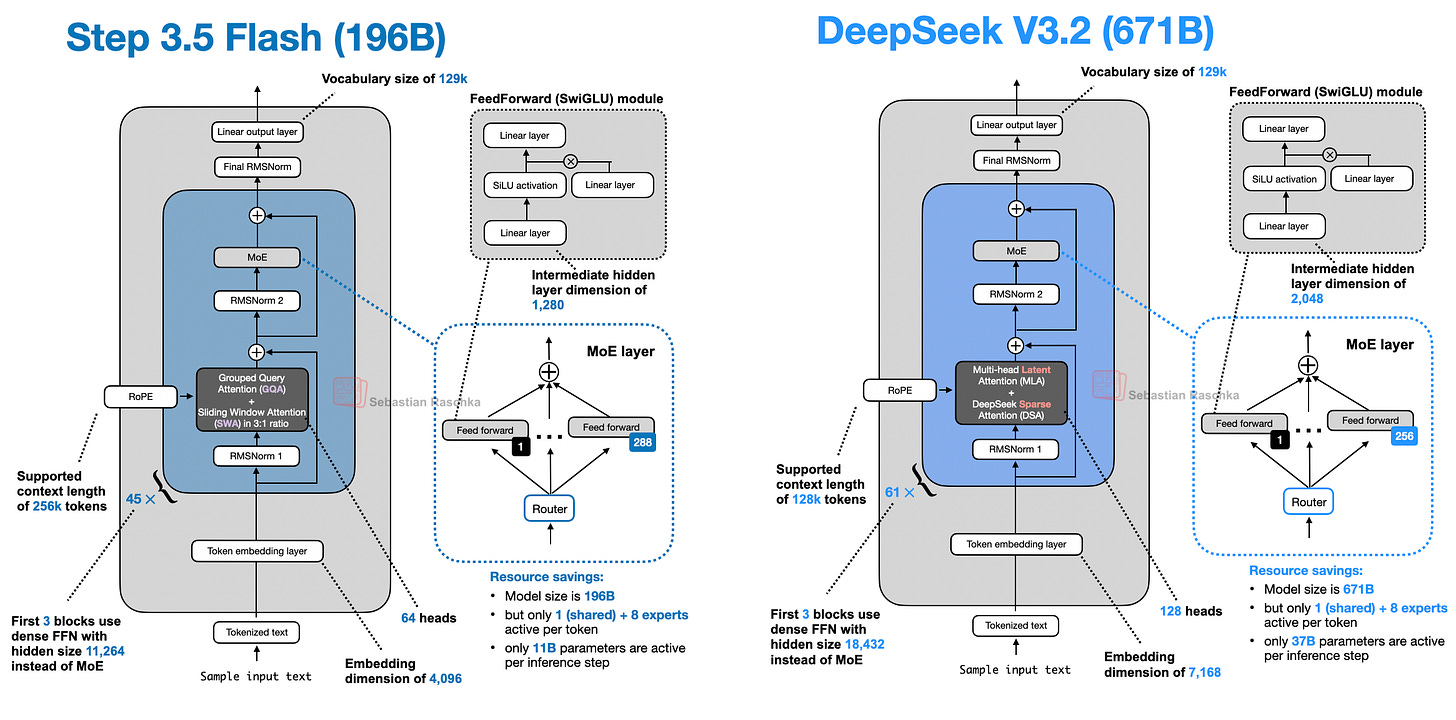
性能較高的一個原因是模型規模較小(196B 參數 MoE,每 token 活化 11B 參數;對比 671B 參數 MoE,每 token 活化 37B 參數),如下圖所示。
另一個原因除了門控注意力(我們之前在 Trinity 的背景下討論過)之外,還有多 Token 預測 (Multi-Token Prediction, MTP)。DeepSeek 是多 token 預測的早期採用者,這項技術訓練 LLM 在每一步預測多個未來的 token,而不是單個。在這裡,在每個位置 $t$,額外的小型頭部(線性層)輸出 $t+1...t+k$ 的 logits,我們對這些偏移量求交叉熵損失之和(在 MTP 論文中,研究人員建議 $k=4$)。
這種額外信號加速了訓練,而推理時仍可保持一次生成一個 token,如下圖所示。
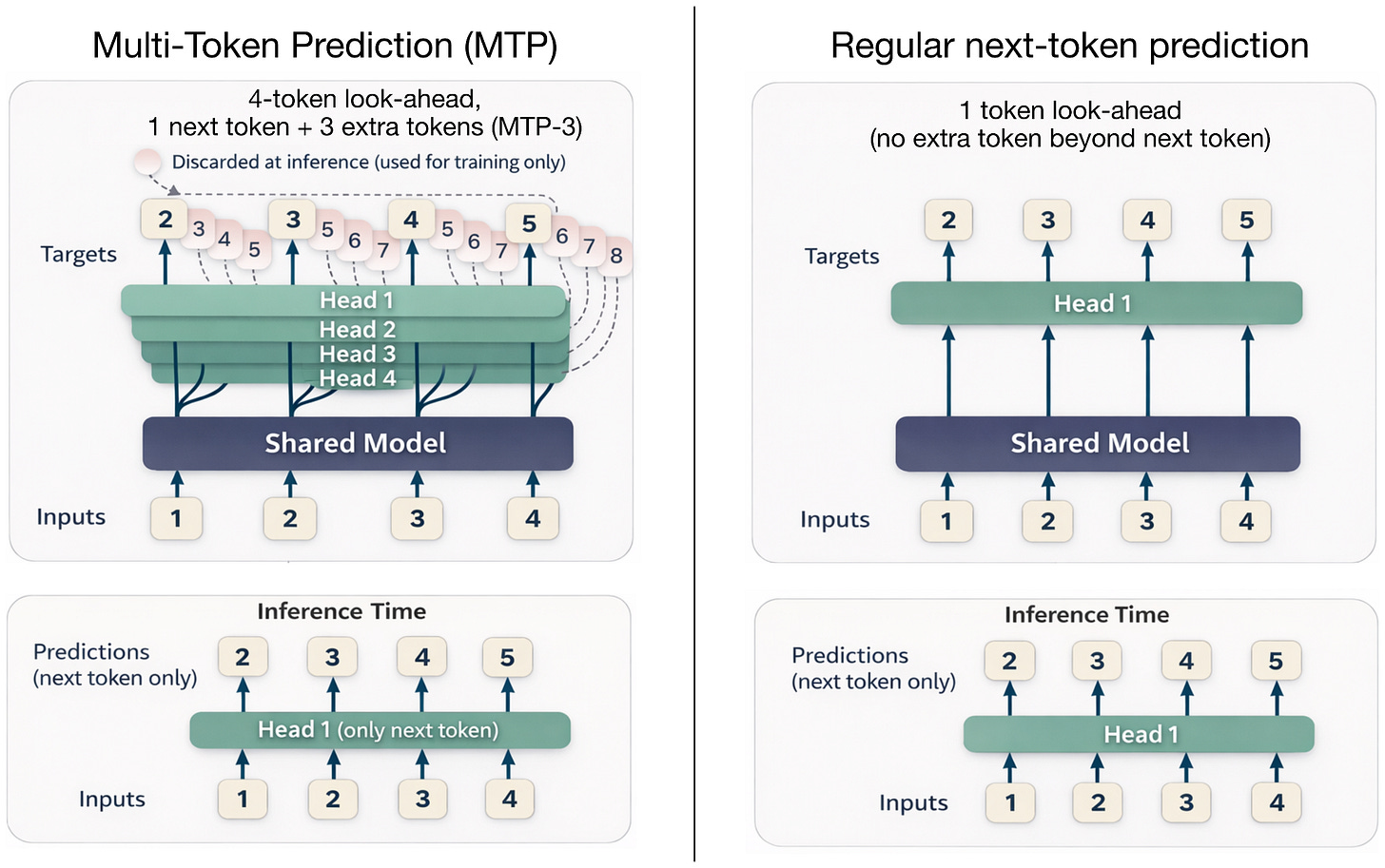
DeepSeek V3 報告在訓練期間使用了 MTP-1,即額外預測 1 個 token(而不是 3 個),然後在推理期間使 MTP 成為可選。
Step 3.5 Flash 在訓練和推理期間都使用了帶有 3 個額外 token 的 MTP (MTP-3)(請注意,MTP 通常不用於推理,這是一個例外)。
請注意,先前討論的 Arcee Trinity 和 Kimi K2.5 不使用 MTP,但其他架構已經使用了類似於 Step 3.5 Flash 的 MTP-3 設置,例如 GLM-4.7 和 MiniMax M2.1。
2026 年 2 月初,Qwen 團隊分享了 80B 的 Qwen3-Coder-Next 模型(3B 活化參數),該模型因在編程任務上超越了 DeepSeek V3.2 (37B 活化) 以及 Kimi K2.5 和 GLM-4.7 (均為 32B 活化) 等大得多的模型而登上頭條。
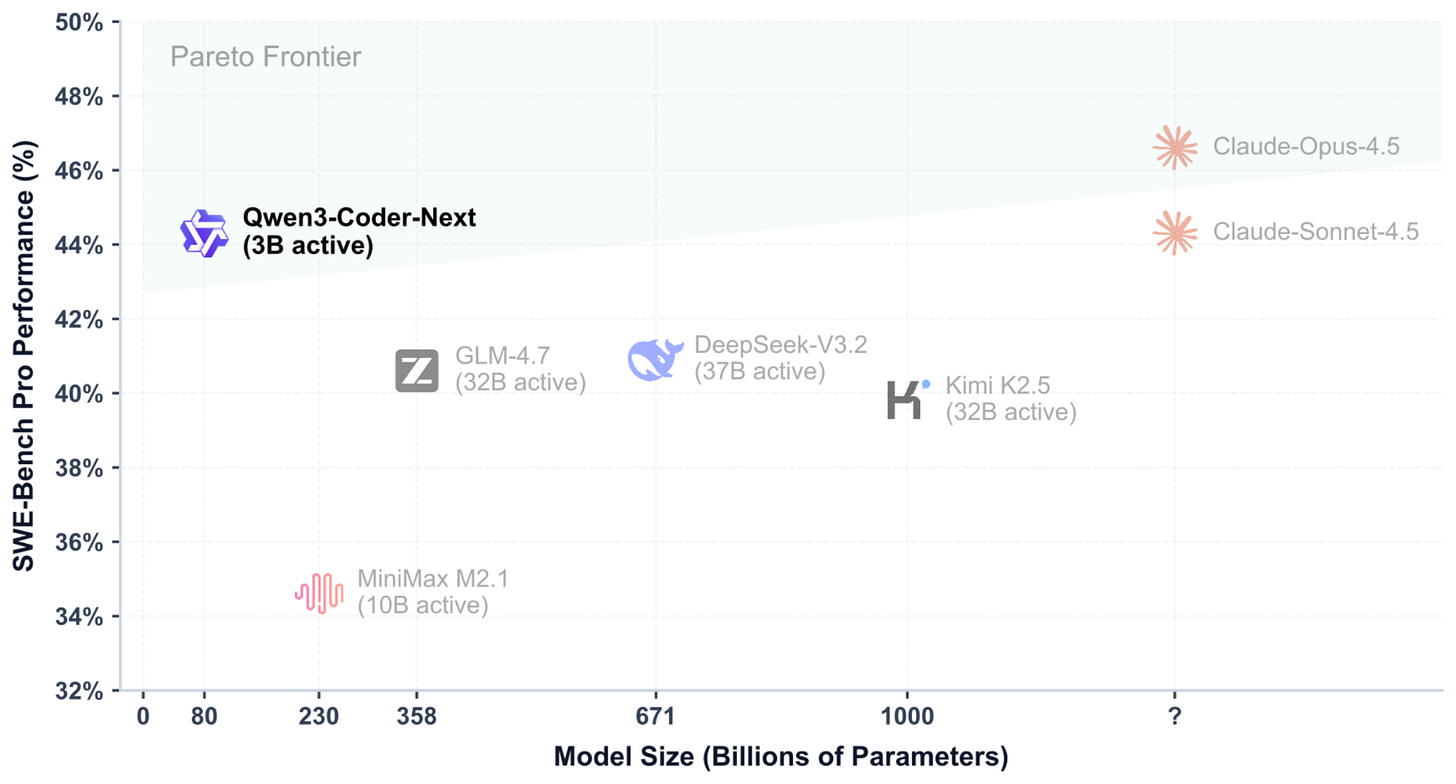
此外,如上面的基準測試圖所示,Qwen3-Coder-Next 的 SWE-Bench Pro 表現與 Claude Sonnet 4.5 大致持平(僅略低於 Claude Opus 4.5),對於一個相對較小的開源權重模型來說,這非常令人印象深刻!
在本地使用 ollama 版本的 Qwen3-Coder-Next,該模型佔用約 48.2 GB 的存儲空間和 51 GB 的 RAM。
請注意,Qwen3-Coder-Next 背後的架構與 Qwen3-Next 80B 完全相同(事實上,預訓練的 Qwen3-Next 80B 被用作進一步中期和後期訓練的基礎模型)。下方的圖 16 顯示了 Qwen3-Next 架構與常規 Qwen3 235B 模型的對比參考。
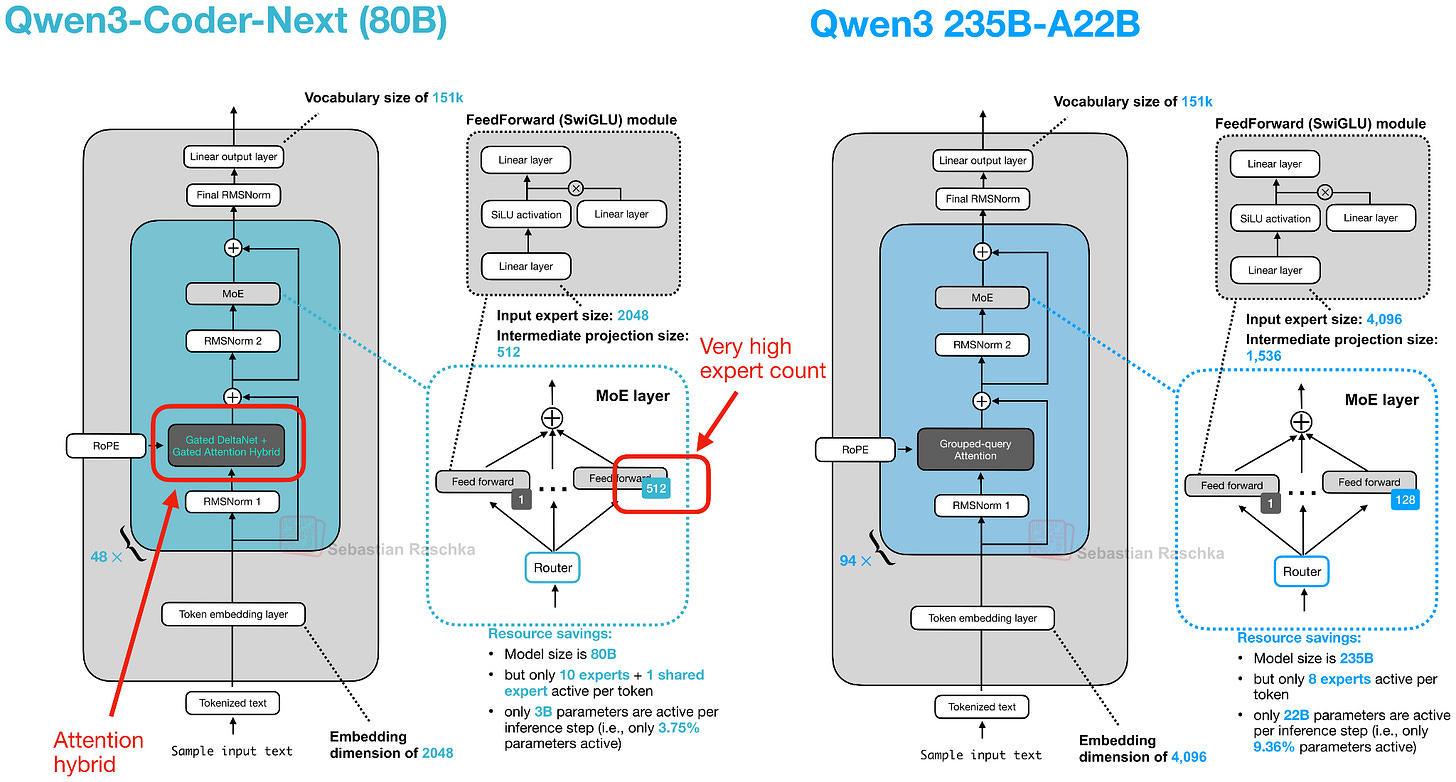
新的 Qwen3 Next 架構脫穎而出,因為儘管規模比之前的 235B-A22B 模型小 3 倍,它卻引入了四倍數量的專家,甚至增加了一個共享專家。這兩項設計選擇(高專家數量和包含共享專家)。
另一個亮點是他們用 Gated DeltaNet + Gated Attention 混合機制取代了常規注意力機制,這有助於在內存使用方面實現原生的 262k token 上下文長度(235B-A22B 模型原生支持 32k,通過 YaRN 縮放支持 131k)。
那麼這種新的注意力混合機制是如何運作的呢?與群組查詢注意力 (GQA) 相比(GQA 仍是標準的縮放點積注意力,通過在查詢頭組之間共享 K/V 來減少 KV 快取大小和內存頻寬,但其解碼成本和快取仍隨序列長度增長),他們的混合機制將 Gated DeltaNet 區塊與 Gated Attention 區塊以 3:1 的比例混合,如圖 17 所示。
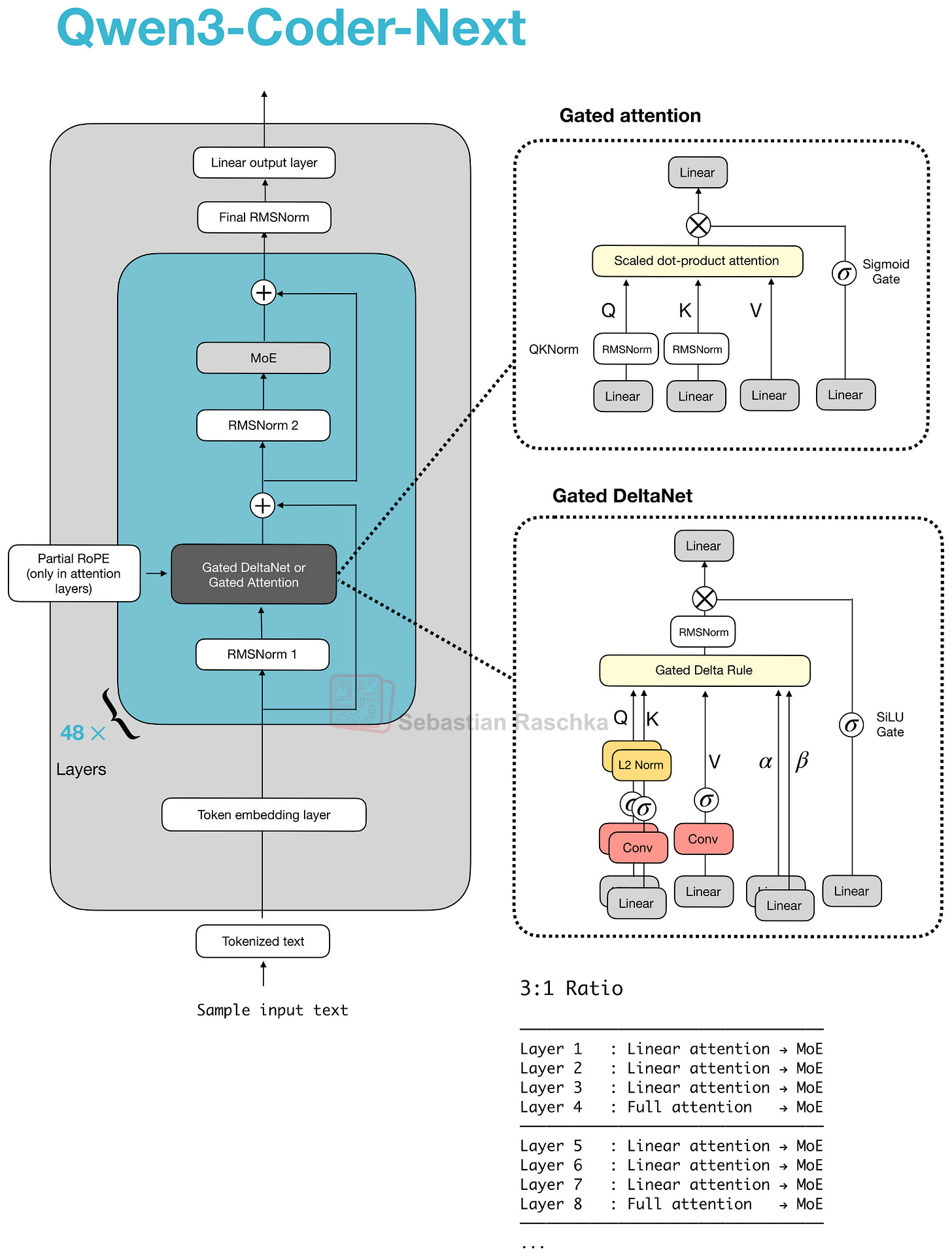
我們可以將門控注意力區塊看作是 GQA 中使用的標準縮放點積注意力,並在其上進行了一些調整。門控注意力與普通 GQA 區塊的主要區別在於:
一個輸出門(由 sigmoid 控制,通常是逐通道的),在將注意力結果加回殘差之前對其進行縮放;
使用零中心 RMSNorm 進行 QKNorm,而不是標準 RMSNorm;
部分 RoPE(僅在部分維度上)。
請注意,這些本質上只是對 GQA 的穩定性改動。
Gated DeltaNet 則是一個更顯著的變化。在 DeltaNet 區塊中,$q, k, v$ 和兩個門 ($\alpha, \beta$) 由帶有歸一化的線性層和輕量級卷積層產生,該層用快速權重 delta 規則更新取代了注意力。
然而,權衡之處在於 DeltaNet 提供的基於內容的檢索精確度低於全注意力,這就是為什麼保留了一個門控注意力層的原因。
考慮到注意力隨平方級別增長,加入 DeltaNet 組件是為了幫助提高內存效率。在「線性時間、無快取」家族中,DeltaNet 區塊本質上是 Mamba 的替代方案。Mamba 通過學習的狀態空間濾波器(本質上是隨時間變化的動態卷積)來保持狀態。DeltaNet 則保持一個微小的、用 $\alpha$ 和 $\beta$ 更新的快速權重內存,並用 $q$ 讀取它,僅使用小型卷積來輔助形成 $q, k, v, \alpha, \beta$。
有關注意力混合和 Qwen3-Next 架構的更多細節,請參閱我之前的文章《超越標準 LLM》。
由於本文主要關注 LLM 架構,訓練細節不在討論範圍內。不過,感興趣的讀者可以在 GitHub 上的詳細技術報告中找到更多資訊。
2 月 12 日發佈的 GLM-5 是一件大事,因為在發佈時,它似乎與主要的旗艦 LLM 產品(包括 GPT-5.2 extra-high、Gemini Pro 3 和 Claude 4.6 Opus)不相上下。(即便如此,基準測試性能並不一定能轉化為現實世界的表現。)
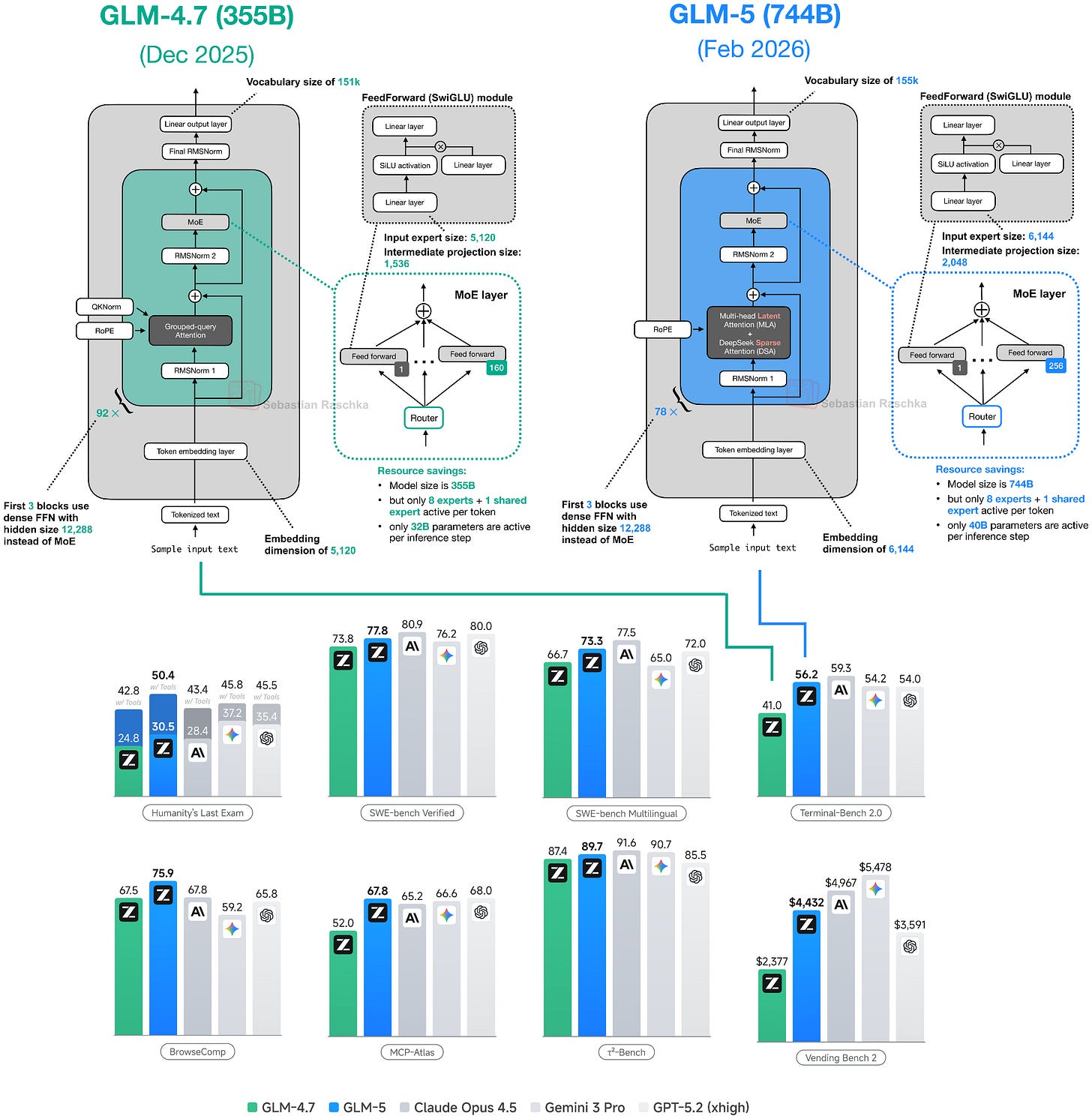
不久前,GLM-4.7(2025 年 12 月)還是最強的開源權重模型之一。根據圖 18 所示的基準測試,GLM-5 展現了重大的建模性能提升。這種飛躍可能部分歸功於訓練流程的改進,但很大程度上歸功於其參數數量翻倍——從 GLM-4.7 的 355B 參數增加到 GLM-5 的 744B 參數。這一規模增長使 GLM-5 在規模上介於 DeepSeek V3.2 (671B) 和 Kimi K2.5 (1T) 之間。
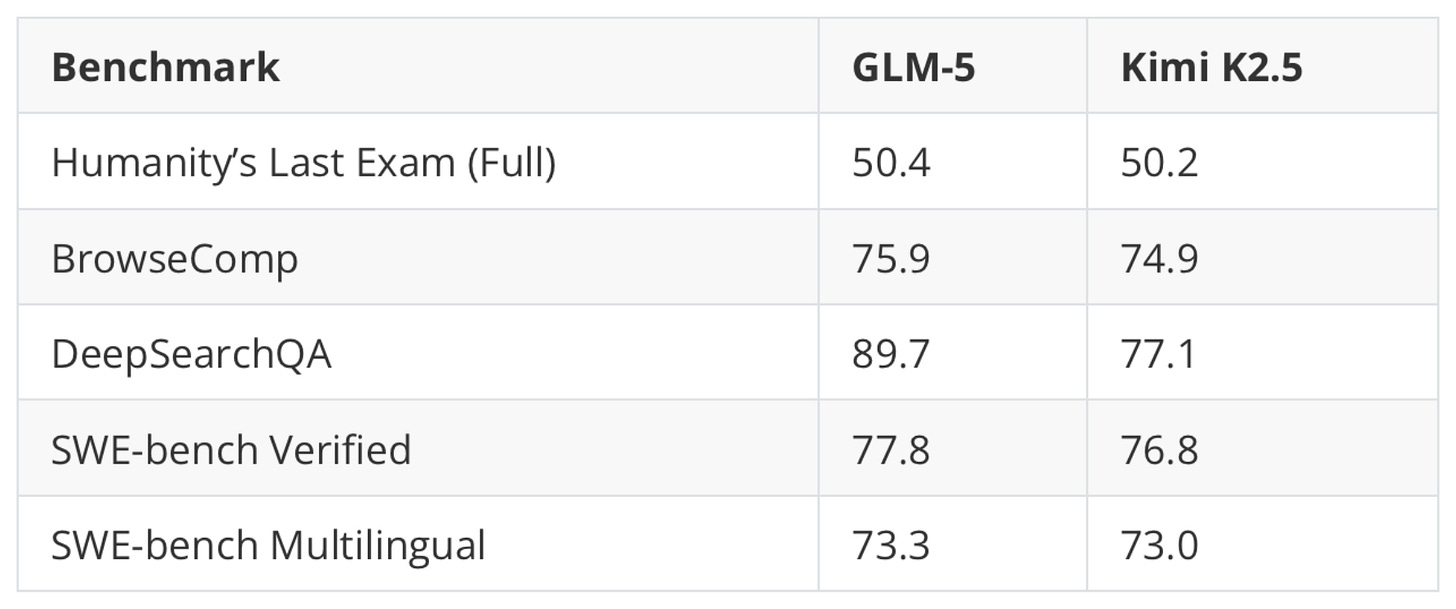
比較先前討論的 Kimi K2.5 (1T) 的基準測試數據,較小的 GLM-5 (744B) 模型似乎略微領先,如下表所示。
與 GLM-4.7 以及目前討論的所有其他模型一樣,GLM-5 也是一個混合專家模型。每 token 的活化參數僅略微增加,從 GLM-4.7 的 32B 增加到 GLM-5 的 40B。
如下圖 20 所示,GLM-5 現在採用了 DeepSeek 的多頭潛在注意力 (MLA) 以及 DeepSeek 稀疏注意力。(我在《從 DeepSeek V3 到 V3.2:架構、稀疏注意力與 RL 更新》中更詳細地描述了 DeepSeek 稀疏注意力。)
這些修改可能是為了降低處理長文本時的推理成本。除此之外,整體架構保持相對相似。
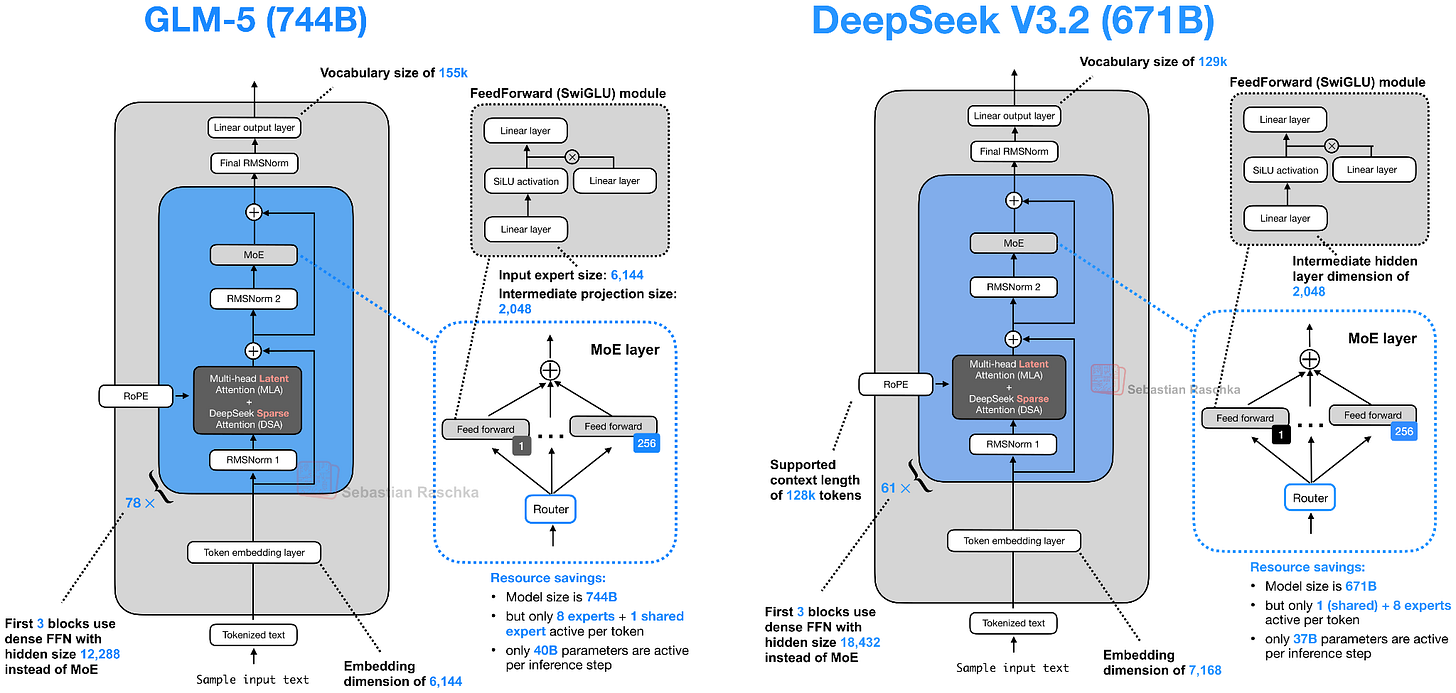
總規模相較於 GLM-4.7 的增加主要來自於擴大專家數量,從 160 個 (GLM-4.7) 增加到 256 個 (GLM-5),並略微增加層維度(同時保持每 token 8 個常規專家 + 1 個共享專家不變)。例如,嵌入維度和專家大小從 5,120 增加到 6,144,中間投影大小從 1,536 增加到 2,048。
有趣的是,Transformer 層數從 GLM-4.7 的 92 層減少到 GLM-5 的 78 層。我推測這一變化也是為了降低推理成本並改善延遲,因為層深度無法像寬度那樣並行化。
此外,我還查看了一個獨立基準測試(幻覺排行榜),GLM-5 確實看起來與 Opus 4.5 和 GPT-5.2 持平(同時使用的 token 更少)。
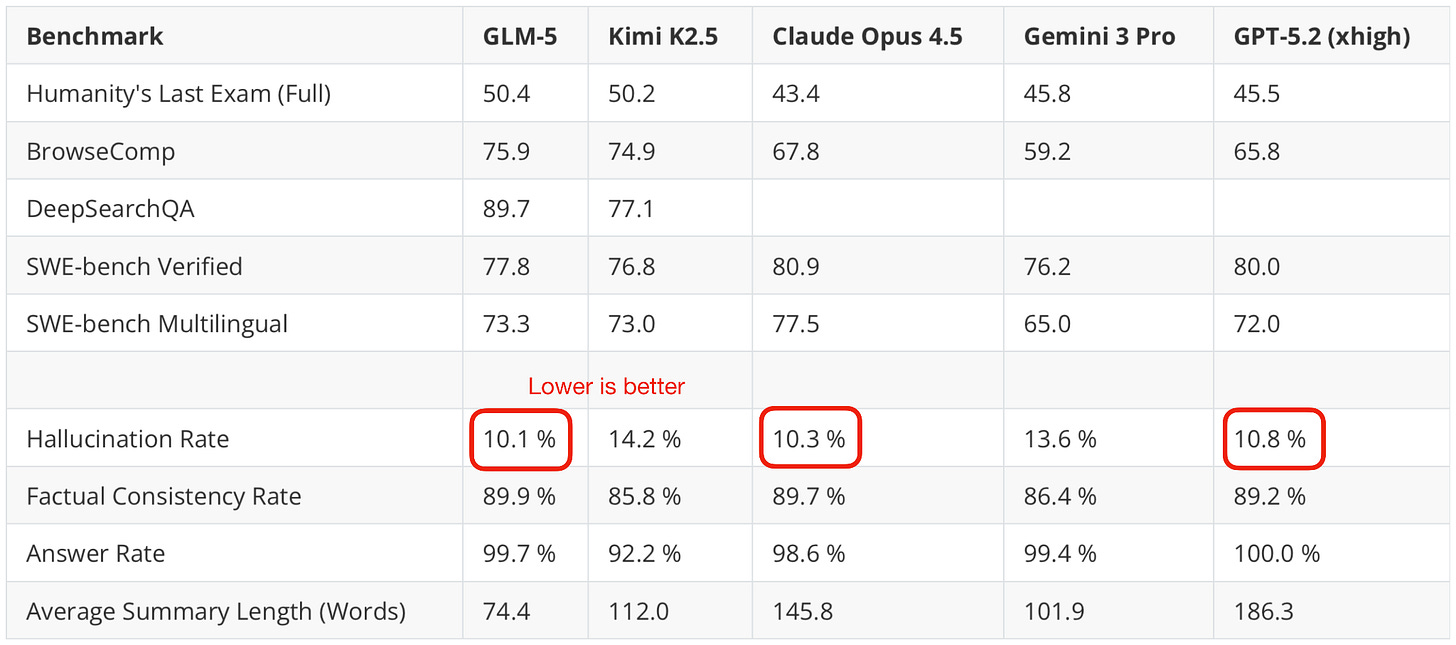
此外,查看匯總了各種基準測試的最新人工智能指數 (Artificial Intelligence Index),GLM-5 確實略微領先於 Kimi K2.5,僅比 GPT-5.2 (xhigh) 和最近的 Claude Sonnet 4.6 低一分。
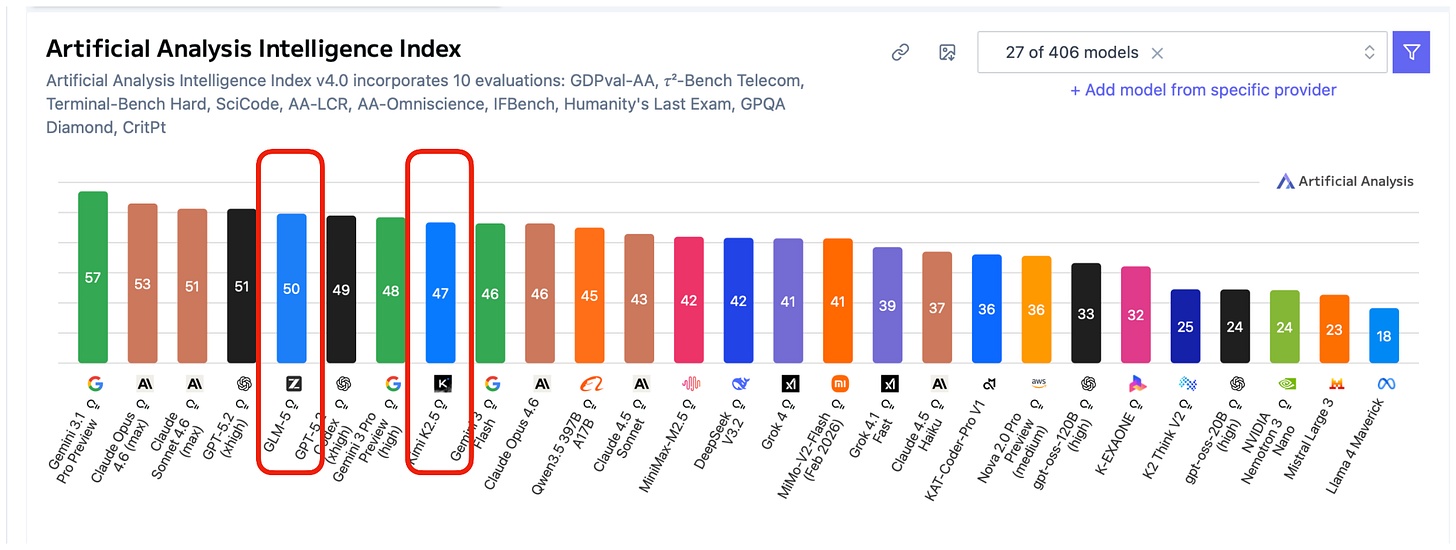
前述的 GLM-5 和 Kimi K2.5 是受歡迎的開源權重模型,但根據 OpenRouter 的統計數據,它們在同樣於 2 月 12 日發佈的 MiniMax M2.5 面前顯得相形見絀。
OpenRouter 是一個平台和 API,允許開發者訪問並路由來自各個供應商的多種不同 LLM。請注意,雖然其使用統計數據是開源權重模型受歡迎程度的一個很好的指標,但它嚴重偏向於開源權重模型(相對於專有模型),因為大多數用戶直接通過官方平台使用專有模型。開源權重模型之間也存在使用偏差,因為許多人也通過官方開發者的 API 使用開源權重模型。無論如何,它仍然是一個可以估算那些對大多數用戶來說太大而無法在本地運行的開源權重模型相對受歡迎程度的有趣地方。
現在回到 MiniMax M2.5。將 SWE-Bench Verified 編程基準測試中的 GLM-5 數據與報告的 MiniMax M2.5 數據相結合,後者似乎是一個略強的模型(至少在編程方面)。
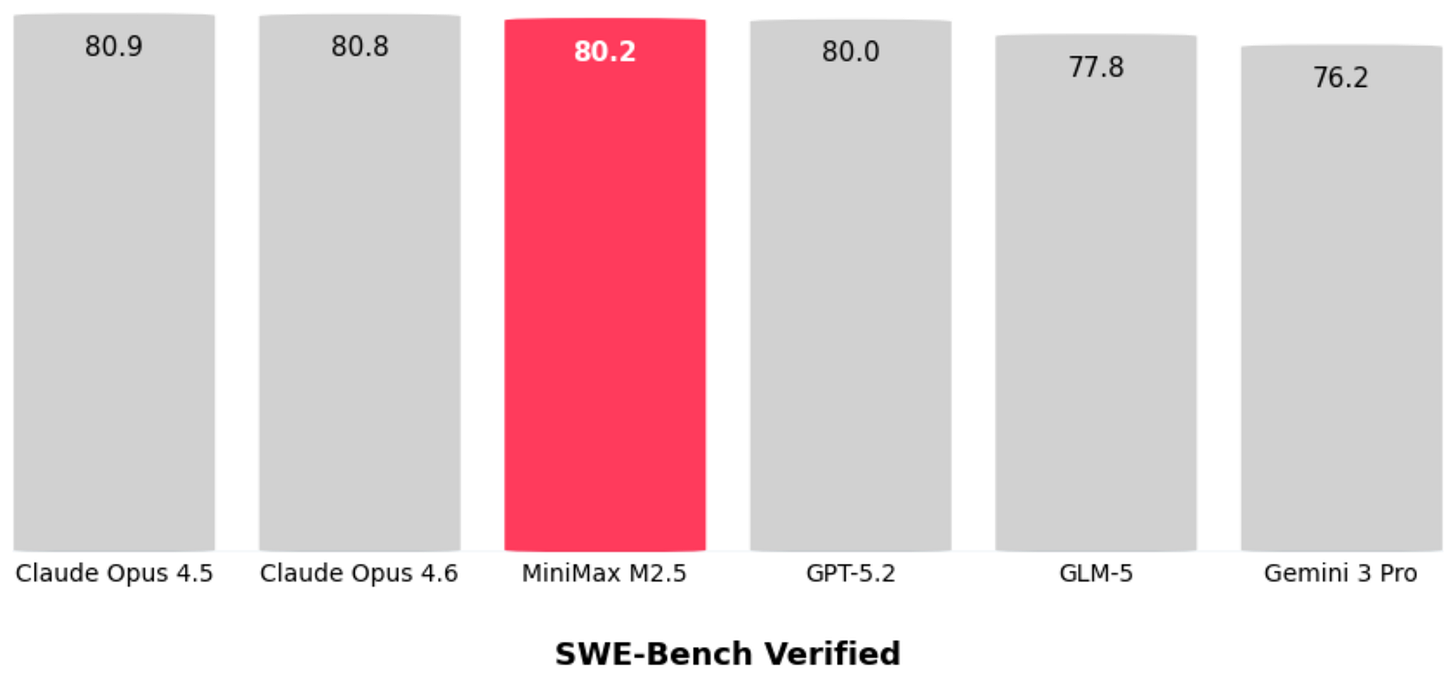
旁註:看到 Opus 4.5 和 Opus 4.6 在 SWE-Bench Verified 上的得分幾乎完全相同,這很有趣。這可能表明 LLM 的進展已經停滯。但我認為事實並非如此,因為 Opus 4.6 的用戶可以確認該模型在實際使用中確實表現更好。因此,這裡更可能的問題是 SWE-Bench Verified 基準測試已經飽和,從現在起它可能不再是一個有意義的報告基準(轉而支持像 SWE-Bench Pro 這樣的其他基準)。所謂飽和,是指它可能包含由於設計問題而無法解決的問題(正如最近的 Reddit 討論串和 OpenAI 的新文章《為什麼 SWE-bench Verified 不再衡量前沿編程能力》中所討論的那樣)。
無論如何,回到 MiniMax M2.5 性能的主題。根據人工智能指數的匯總,查看更廣泛的基準測試選擇,GLM-5 仍然領先。這或許並不意外,因為 GLM-5 的規模仍比 M2.5 大 4 倍,儘管 token/sec 吞吐量非常相似。

我認為 MiniMax M2.5 的受歡迎程度部分歸功於它是一個更小、更便宜的模型,且擁有大致相似的建模性能(即性價比高)。
在架構方面,MiniMax M2.5 是一個 230B 的模型,採用相當經典的設計:僅使用普通的群組查詢注意力 (GQA),沒有滑動窗口注意力或其他效率改進。
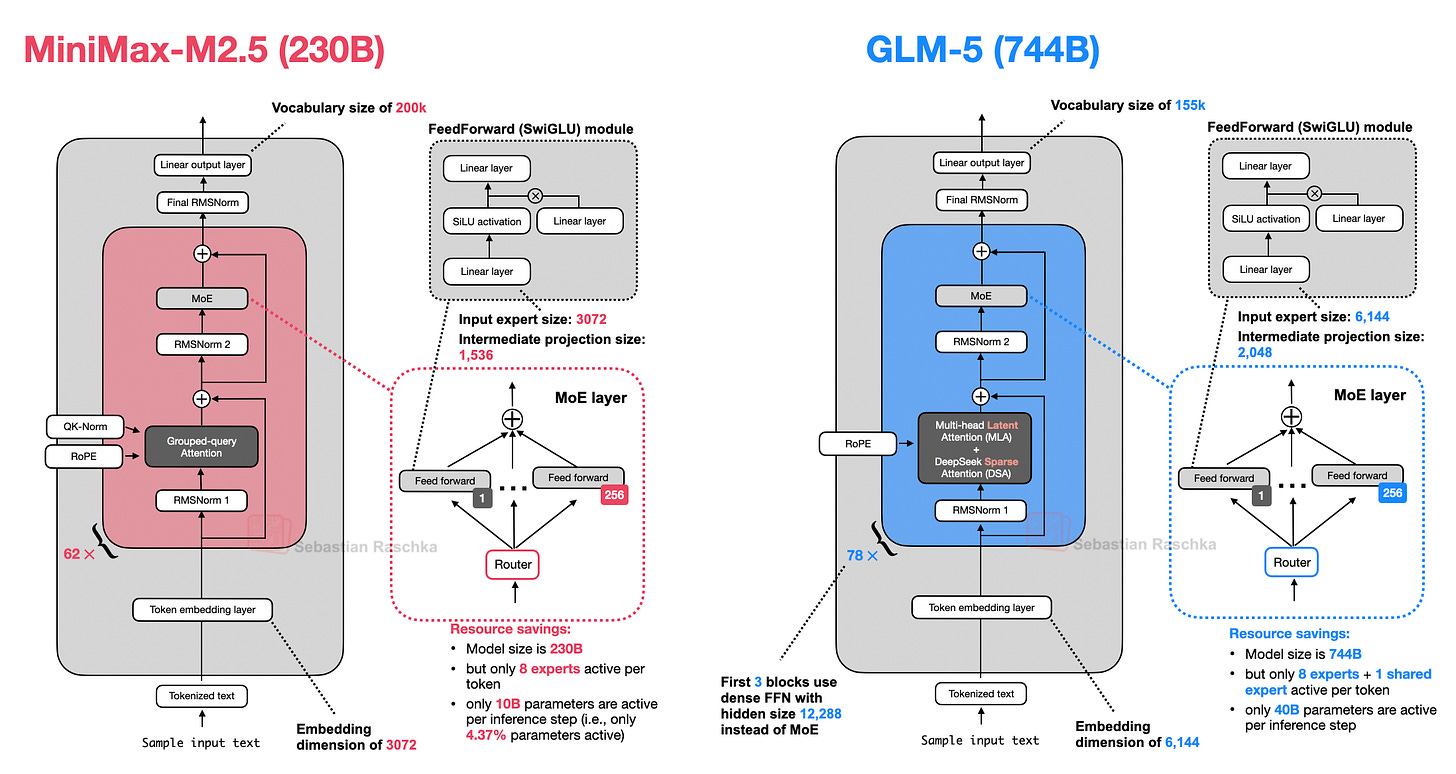
到目前為止,這也是本報告中第一個沒有附帶詳細技術報告的架構,但你可以在模型中心頁面上找到額外資訊。
在本節中,我們將轉換方向,終於要介紹一個可以在筆記本電腦上本地運行的較小模型。但在討論南北閣 4.1 3B 之前,我們先了解一些背景。
Qwen 模型一直非常受歡迎。我經常講一個故事:幾年前當我是 NeurIPS LLM 效率挑戰賽的顧問時,大多數獲勝方案都是基於 Qwen 模型的。
現在,Qwen3 可能是使用最廣泛的開源權重模型系列之一,因為它們涵蓋了從 0.6B 到 235B 的廣泛規模和用例。
特別是較小的模型(80B 及以下,如前述的 Qwen3-Next)非常適合在消費級硬件上本地使用。
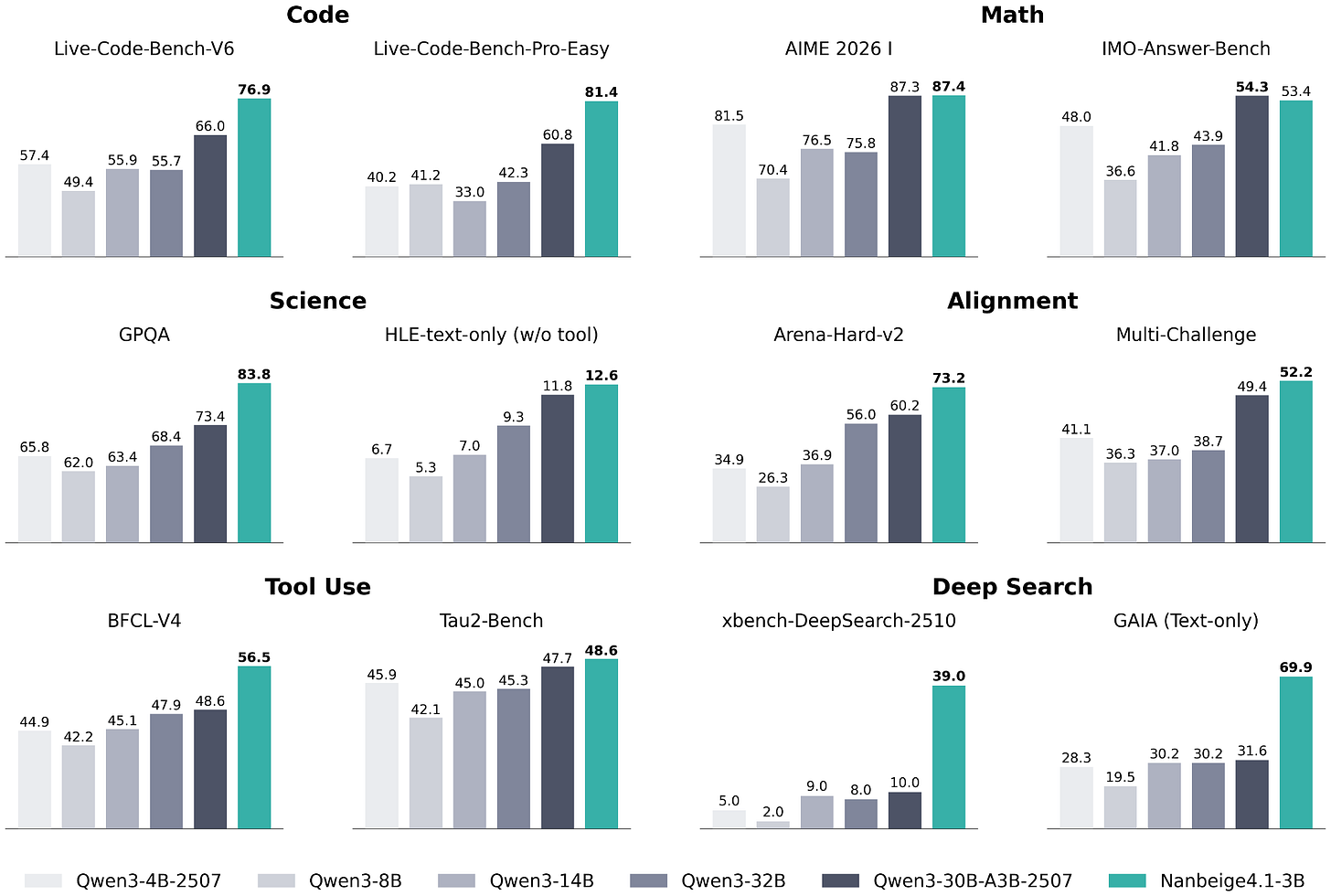
我提到這些的原因是,南北閣 4.1 3B 似乎瞄準了 Qwen3 非常受歡迎的「小型」LLM 設備端使用場景。根據南北閣 4.1 3B 的基準測試,他們的模型遠超 Qwen3(這或許並不意外,因為 Qwen3 已經發佈快一年了)。
在架構方面,南北閣 4.1 3B 與 Qwen3 4B 相似,而後者又與 Llama 3.2 3B 非常相似。我在下方將南北閣 4.1 3B 與 Llama 3.2 3B 並列顯示,因為它們的規模最為接近。
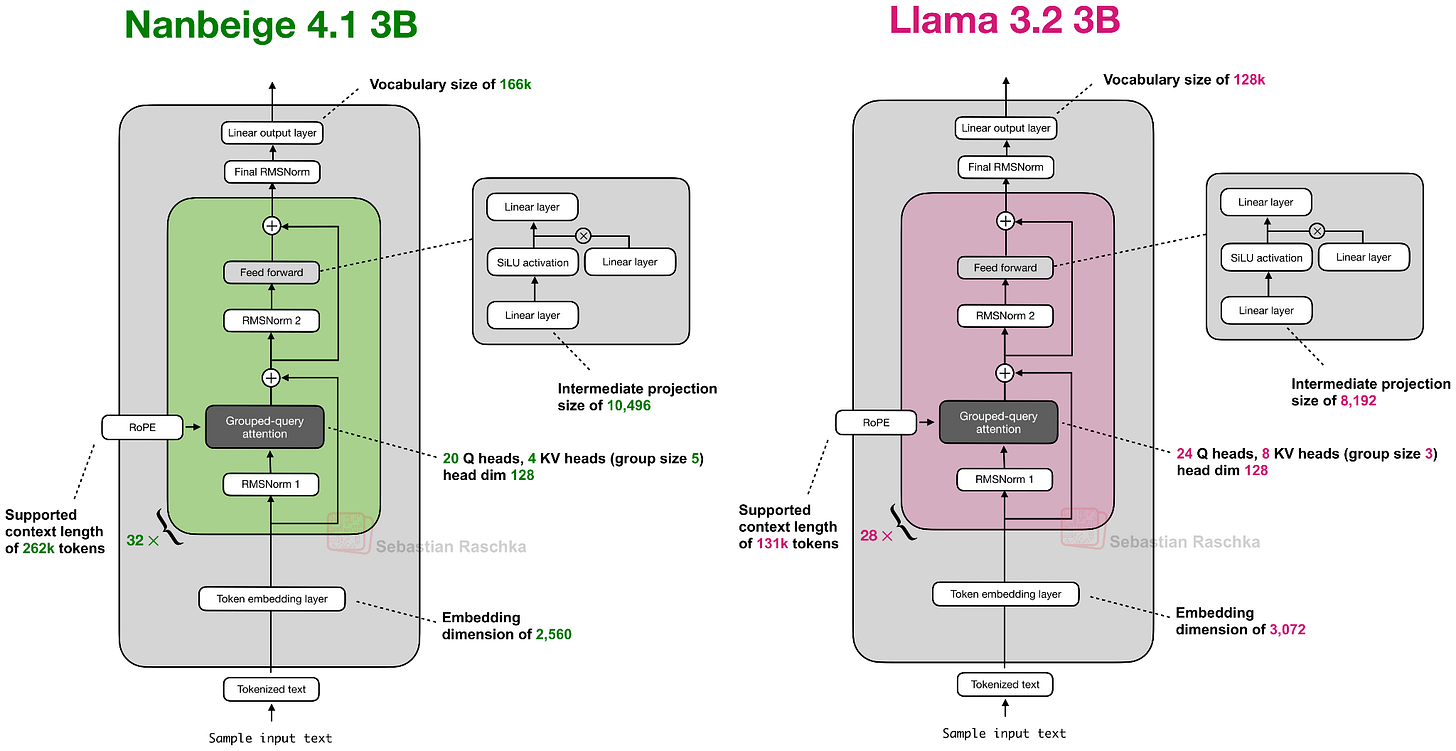
南北閣 4.1 3B 使用了與 Llama 3.2 3B 相同的架構組件,僅有一些細微的縮放差異(略小的嵌入維度和較大的中間投影等)。上圖未顯示的一個區別是,南北閣沒有將輸入嵌入權重與輸出層權重綁定 (weight tying),而 Llama 3.2 3B 則有。(根據我的經驗,權重綁定是減少參數總數的一種好方法,但它幾乎總是會導致訓練性能下降,表現為更高的訓練和驗證損失。)
如前所述,本文主要關注架構比較。在這種情況下,大部分性能提升(與南北閣 4 3B 前身相比)來自於額外的後期訓練,包括監督微調和強化學習,但感興趣的讀者可以在詳細技術報告中找到更多資訊。
雖然上一節簡要提到 Qwen3 是最受歡迎的開源權重模型系列,但由於其發佈已近一年(如果不算針對效率的 Qwen3-Next 變體),它顯得有些老舊。然而,Qwen 團隊剛在 2 月 15 日發佈了新的 Qwen3.5 模型變體。
Qwen3.5 397B-A17B 是一個擁有 397B 參數(每 token 活化 17B)的混合專家模型 (MoE),比最大的 Qwen3 模型(235B 參數)更進一步。(雖然還有 1 萬億參數的 Qwen3-Max 模型,但它從未作為開源權重模型發佈。)
必看的基準測試概覽顯示,Qwen3.5 在各方面都超越了之前的 Qwen3-Max 模型,並更加強調 Agent 終端編程應用(今年的主旋律)。在純 Agent 編程性能(例如 SWE-Bench Verified)方面,Qwen3.5 似乎與 GLM-5 和 MiniMax M2.5 大致持平。
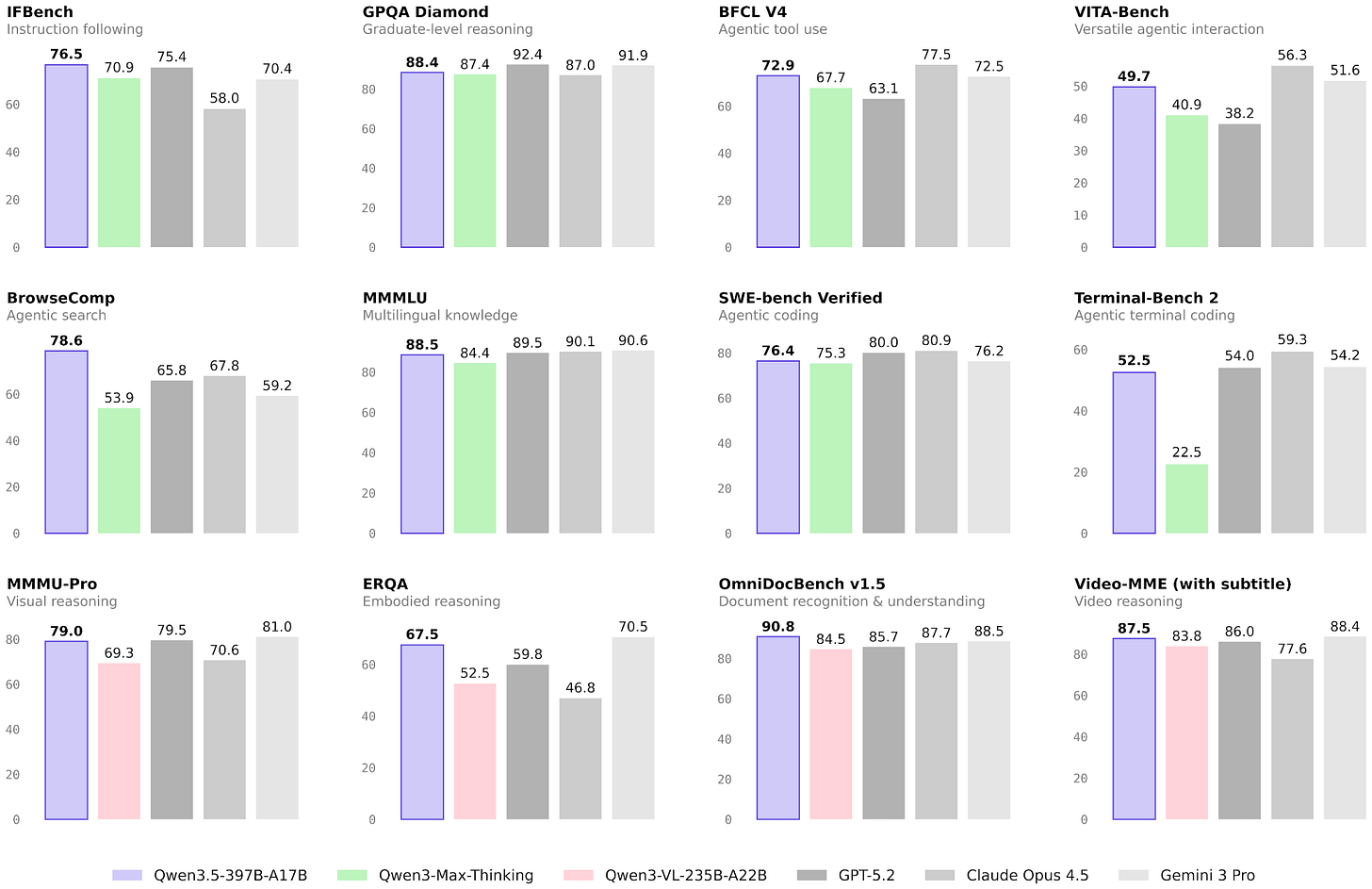
由於 Qwen 團隊喜歡發佈單獨的編程模型(例如我們之前討論過的 Qwen3-Coder-Next),這讓我很好奇潛在的 Qwen3.5-Coder 表現會如何。
在架構方面,Qwen3.5 採用了 Qwen3-Next 和 Qwen3-Coder-Next(第 4 節)使用的混合注意力模型(具有 Gated DeltaNet)。這很有趣,因為 Qwen3-Next 模型最初是作為全注意力 Qwen3 模型的替代方案,但這表明 Qwen 團隊現在已將混合注意力機制納入其主線模型。
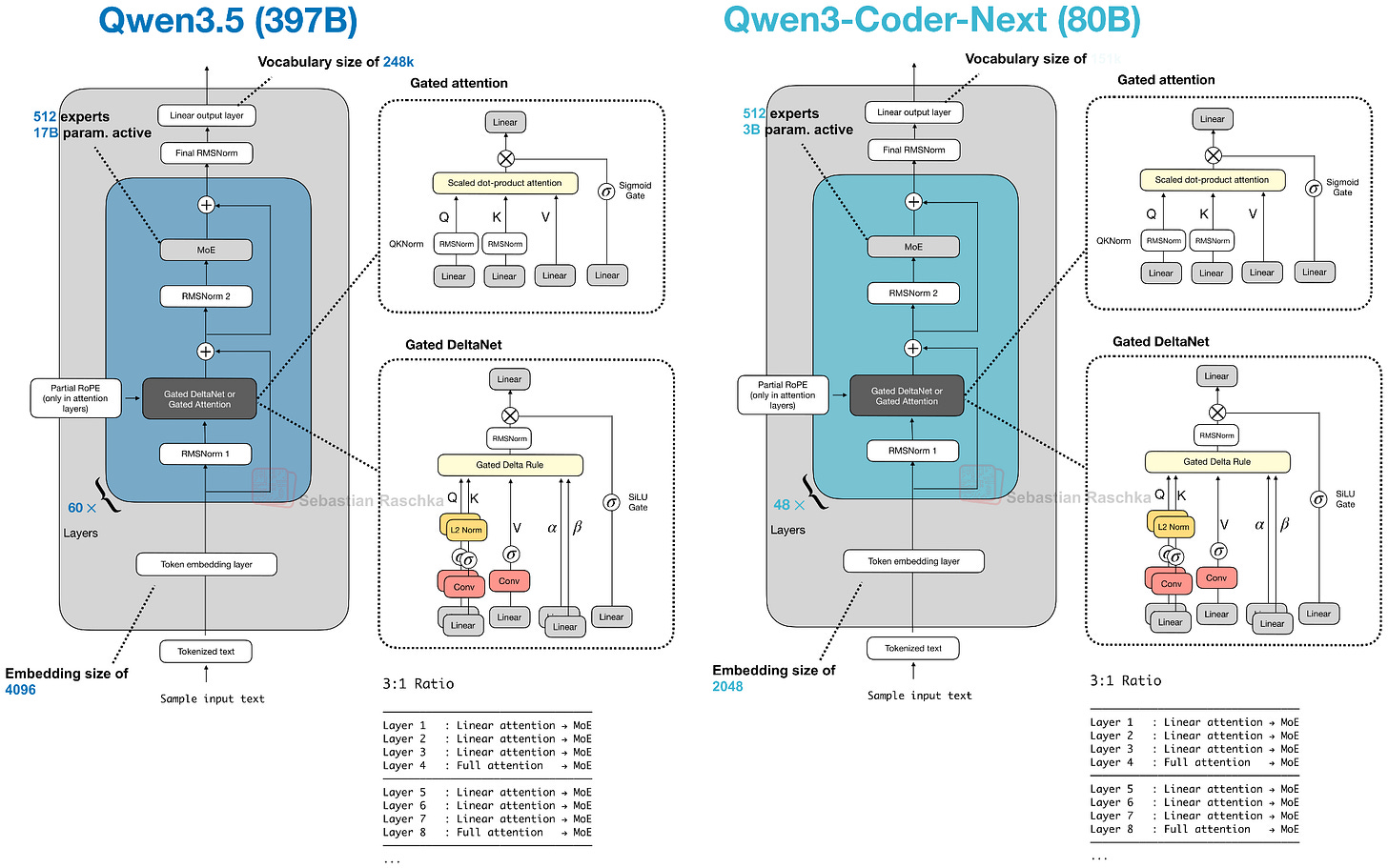
除了擴大模型規模外,如上圖所示,Qwen3.5 現在還包含了多模態支持(以前僅在單獨的 Qwen3-VL 模型中提供)。
無論如何,Qwen3.5 是 Qwen 系列的一次不錯的更新,我希望未來也能看到較小的 Qwen3.5 變體!
編輯:就在我定稿這篇文章時,Qwen 團隊推出了上述的較小模型變體:
Qwen3.5-27B
Qwen3.5-35B-A3B
Qwen3.5-122B-A10B
靈 (Ling) 2.5(以及推理變體 鈴 (Ring) 2.5)是 1 萬億參數的 LLM,採用與 Qwen3.5 和 Qwen3-Next 精神相似的混合注意力架構。
然而,他們沒有使用 Gated DeltaNet,而是使用了一種稍微簡單的循環線性注意力變體,稱為 Lightning Attention。此外,靈 2.5 還採用了來自 DeepSeek 的多頭潛在注意力 (MLA) 機制。
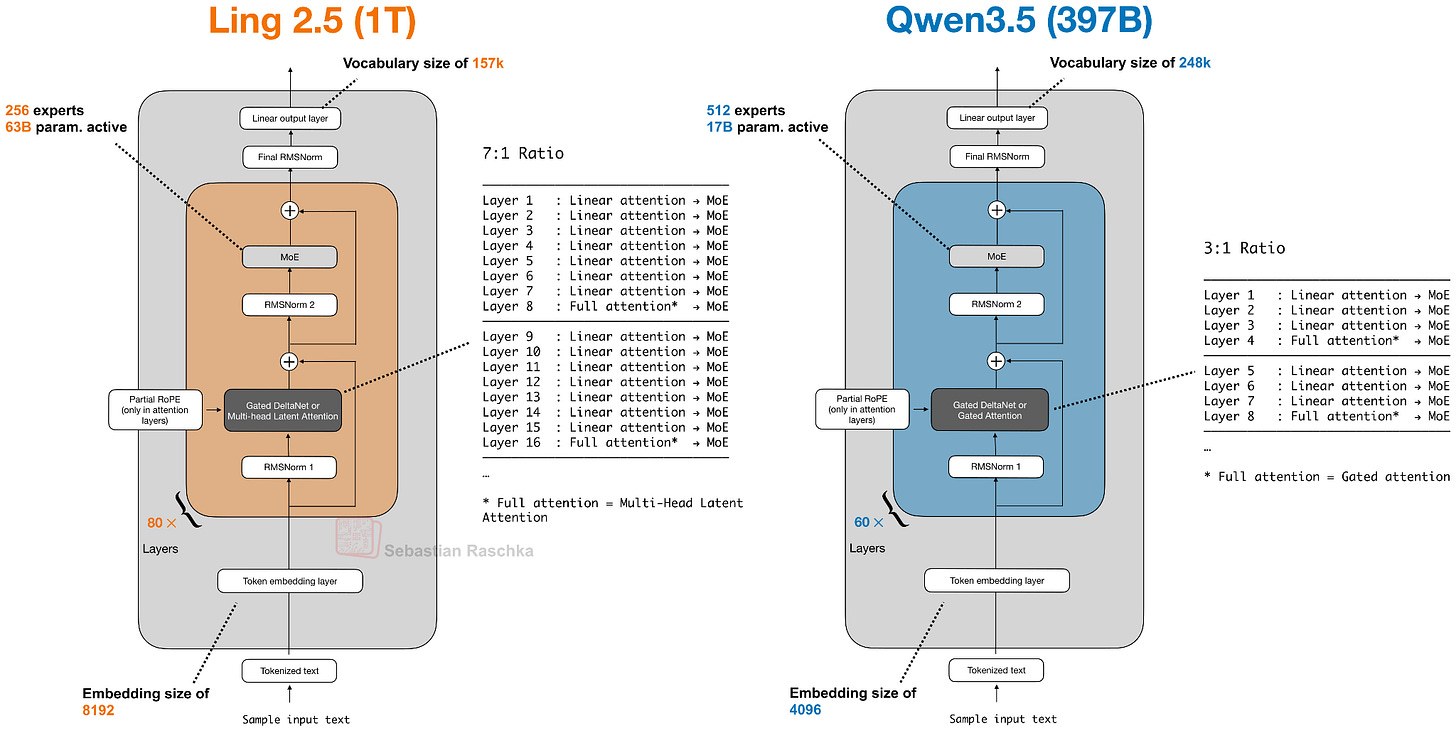
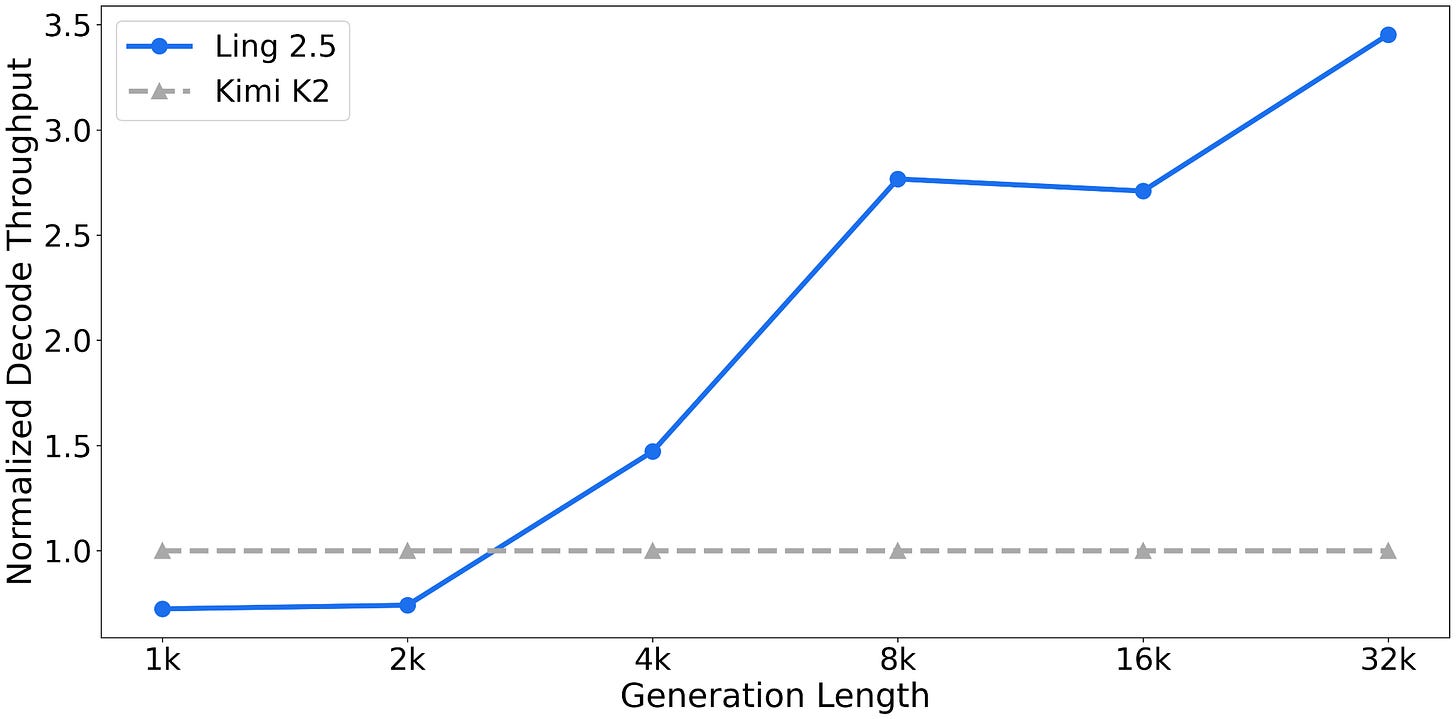
就絕對基準測試性能而言,靈 2.5 並不是最強的模型,但其賣點在於長文本中的極高效率(歸功於混合注意力)。遺憾的是沒有與 Qwen3.5 的直接比較,但與 Kimi K2(1T 參數;與靈 2.5 規模相同)相比,靈 2.5 在 32k token 的序列長度下實現了 3.5 倍的吞吐量。
Tiny Aya 於 2 月 17 日發佈,是 Cohere 推出的一款新的「小型」LLM,據稱是 3B 參數級別中「最強大的多語言開源權重模型」。(根據發佈公告,Tiny Aya 超越了 Qwen3-4B、Gemma 3 4B 和 Ministral 3 3B)。
這是一個非常適合在本地運行和實驗的模型。唯一的遺憾是,雖然它是開源權重模型,但其許可條款相對受限,僅允許非商業用途。
撇開這點不談,Aya 是一個 3.35B 參數的模型,有多種版本,適用於個人和(非商業)研究用途:
tiny-aya-base (基礎模型)
tiny-aya-global (在不同語言和地區之間取得最佳平衡)
tiny-aya-fire (針對南亞語言優化)
tiny-aya-water (針對歐洲和亞太語言優化)
tiny-aya-earth (針對西亞和非洲語言優化)
具體而言,以下是模型優化的語言列表。
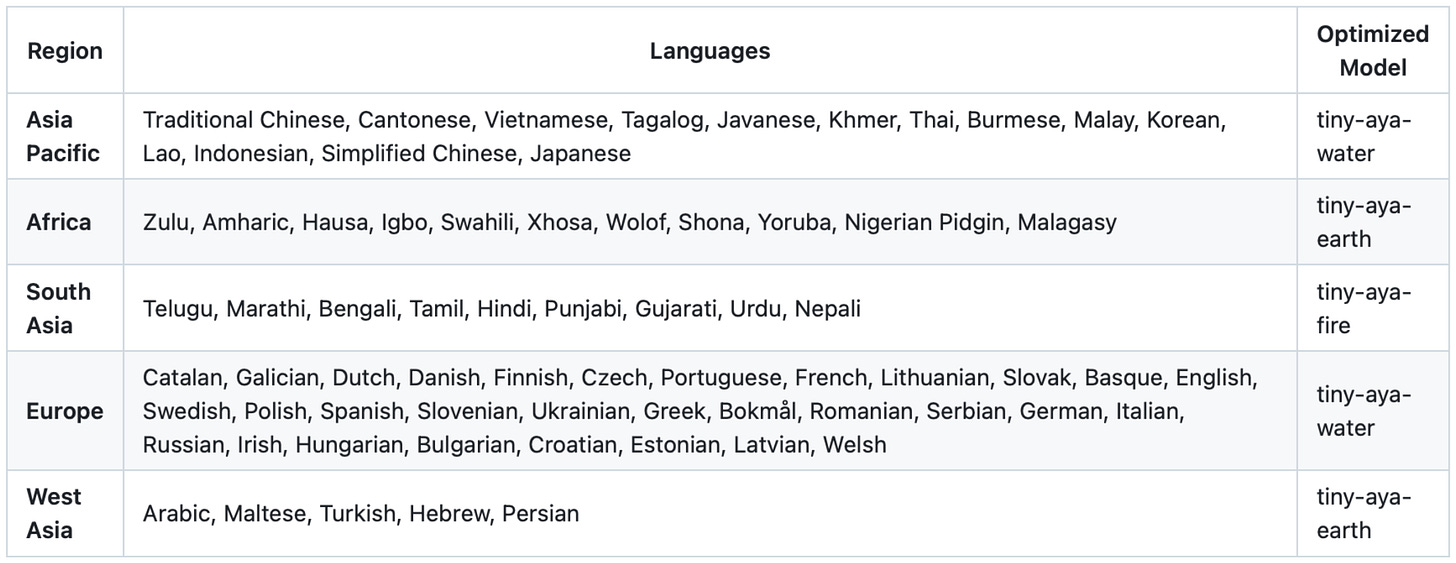
在架構方面,Tiny Aya 是一個經典的解碼器風格 Transformer,並帶有一些值得注意的修改(除了 SwiGLU 和群組查詢注意力等顯而易見的修改),如下圖所示。
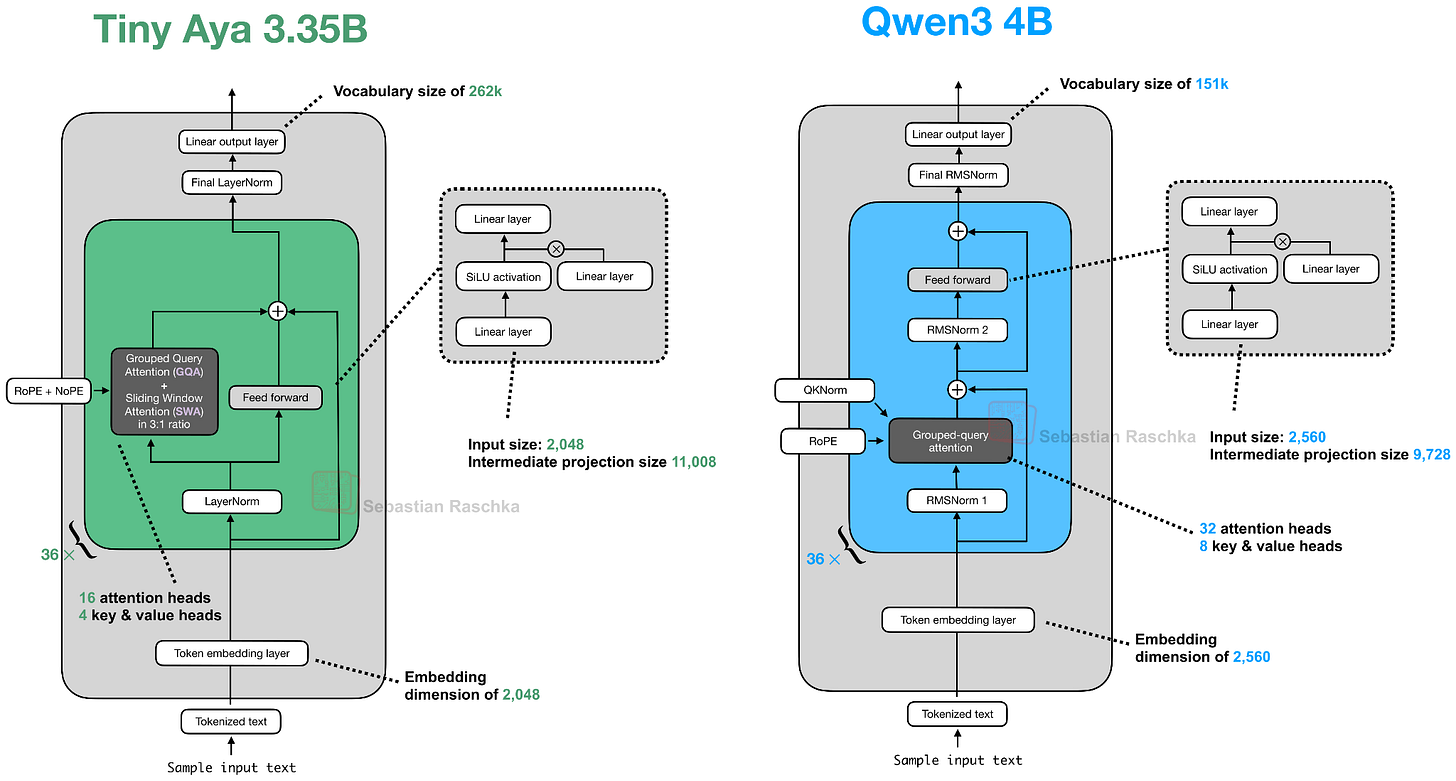
總體而言,該架構中最值得注意的亮點是並行 Transformer 區塊。在這裡,並行 Transformer 區塊從同一個歸一化輸入中同時計算注意力和 MLP,然後在單個步驟中將兩者加回殘差。我推測這是為了減少層內的串行依賴,以提高計算吞吐量。
對於熟悉 Cohere 的 Command-A 架構的讀者來說,Tiny Aya 似乎是它的縮小版。此外,一個有趣的細節是 Tiny Aya 團隊放棄了 QK-Norm(在注意力機制內部應用於 Key 和 Query 的 RMSNorm);QK-Norm 已成為減少損失尖峰以提高訓練穩定性的標準做法。根據 Cohere 團隊的一位開發人員的說法,放棄 QK-Norm 是「因為它可能會干擾長文本性能」。
如你所知,我偶爾會從頭開始編寫架構代碼。由於我發現並行 Transformer 區塊非常有趣,且該模型在低端硬件上運行良好,我從頭實現了它(出於教育目的),你可以在 GitHub 上的這裡找到它。
這篇文章是對 2026 年 2 月前後主要開源權重 LLM 發佈的一次走馬觀花式的巡禮。如果說有什麼啟示的話,那就是有各種模型架構(均源自原始 GPT 模型)都能很好地運作。建模性能可能不歸功於架構設計本身,而更多地歸功於數據集質量和訓練配方(這是一個適合單獨成文的好主題)。
即便如此,架構設計仍然是構建成功 LLM 的重要組成部分,許多開發者似乎正傾向於加入越來越多的計算性能優化。例如,這包括採用 MLA (Kimi K2.5, GLM-5, 靈 2.5) 和 DeepSeek 稀疏注意力 (GLM-5),以延續 Gated DeltaNet (Qwen3.5) 或類似形式的線性注意力 (靈 2.5)。
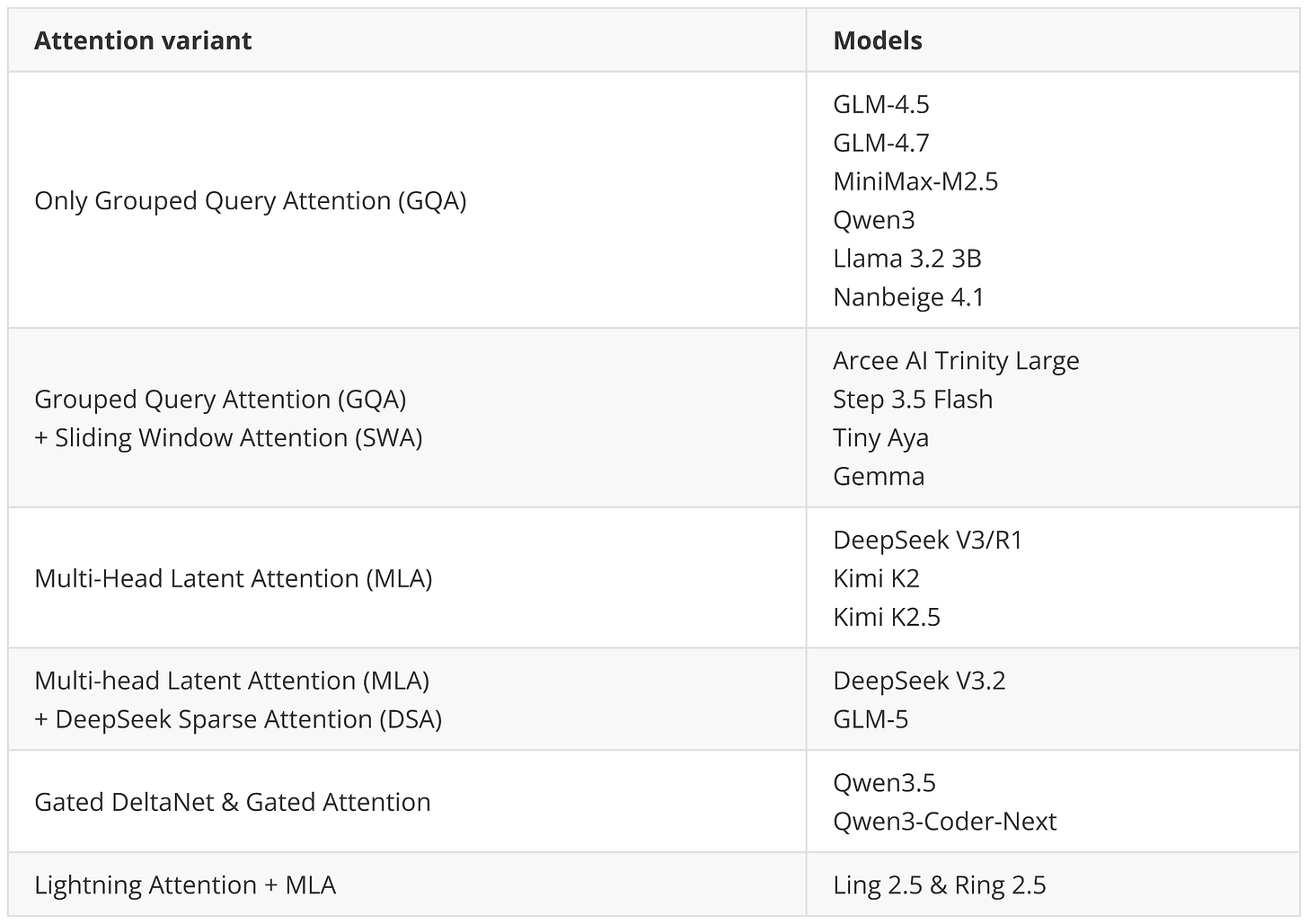
此外,更經典的效率優化如群組查詢注意力和滑動窗口注意力 (Arcee Trinity, Step 3.5 Flash, Tiny Aya) 仍然很受歡迎。在新發佈的模型中,只有 MiniMax M2.5 和南北閣 4.1 在這方面保持非常經典,僅使用群組查詢注意力而沒有任何其他效率優化。
DeepSeek V4 是每個人都在期待的模型。遺憾的是,截至本文撰寫時,它尚未發佈。不過,我計劃在它發佈後(很可能在 3 月的第一週或之前)將其添加到本文中。
另一個有趣的模型是來自印度的 Sarvam (30B & 100B)。該模型最近剛宣佈,但尚未發佈。請關注這裡的更新。
正如所承諾的,這裡是關於 Sarvam 的簡短更新。
在等待 DeepSeek V4 的同時,我們得到了兩款來自印度的非常強大的開源權重 LLM。
共有兩種規模:Sarvam 30B 和 Sarvam 105B 模型(均為推理模型),它們於 3 月 6 日作為開源權重模型發佈,並附帶了一份相當詳細的公告博客。
有趣的是,較小的 30B 模型使用了「經典」的群組查詢注意力 (GQA),而較大的 105B 變體則轉向了 DeepSeek 風格的多頭潛在注意力 (MLA)。
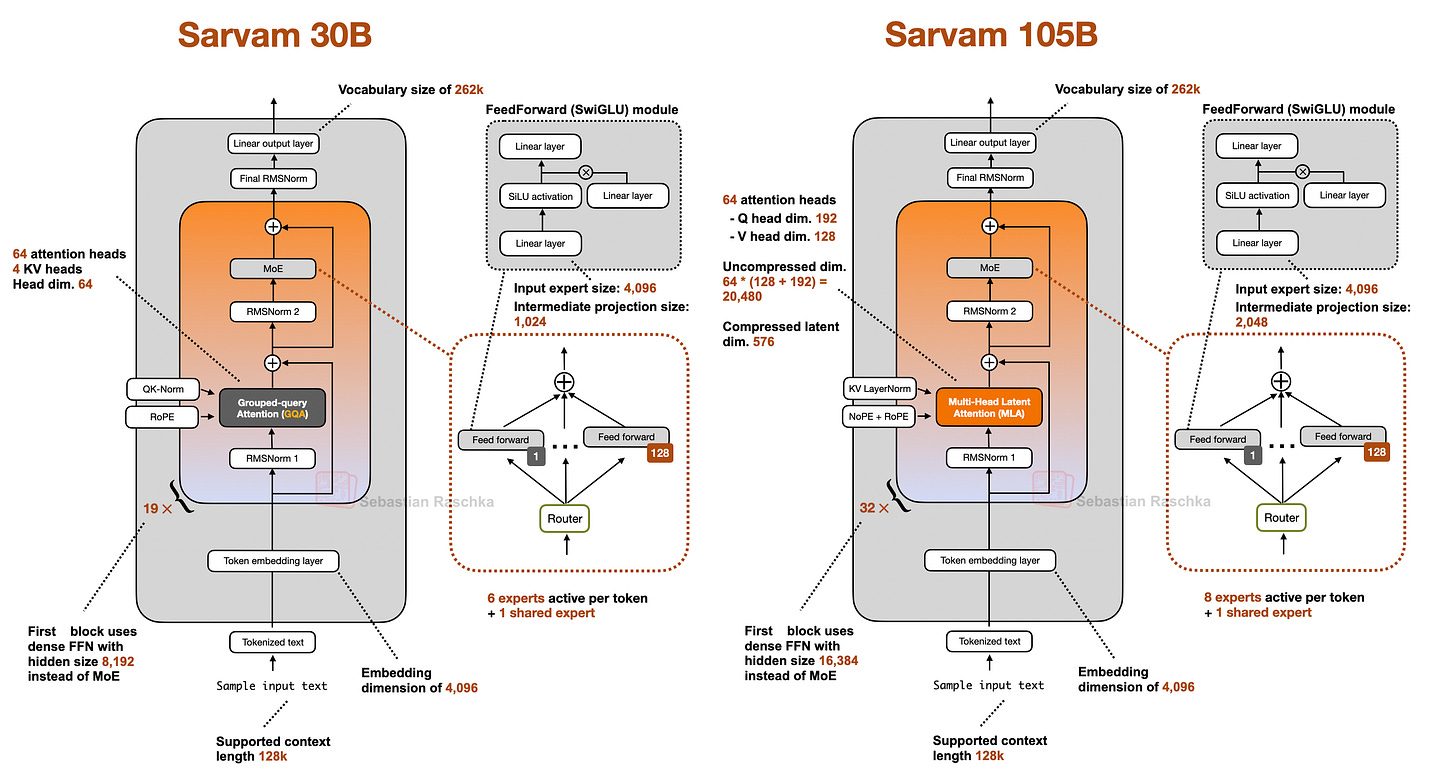
正如我之前在分析中所寫,兩者都是減少 KV 快取大小的流行注意力變體(上下文越長,與常規注意力相比節省越多)。
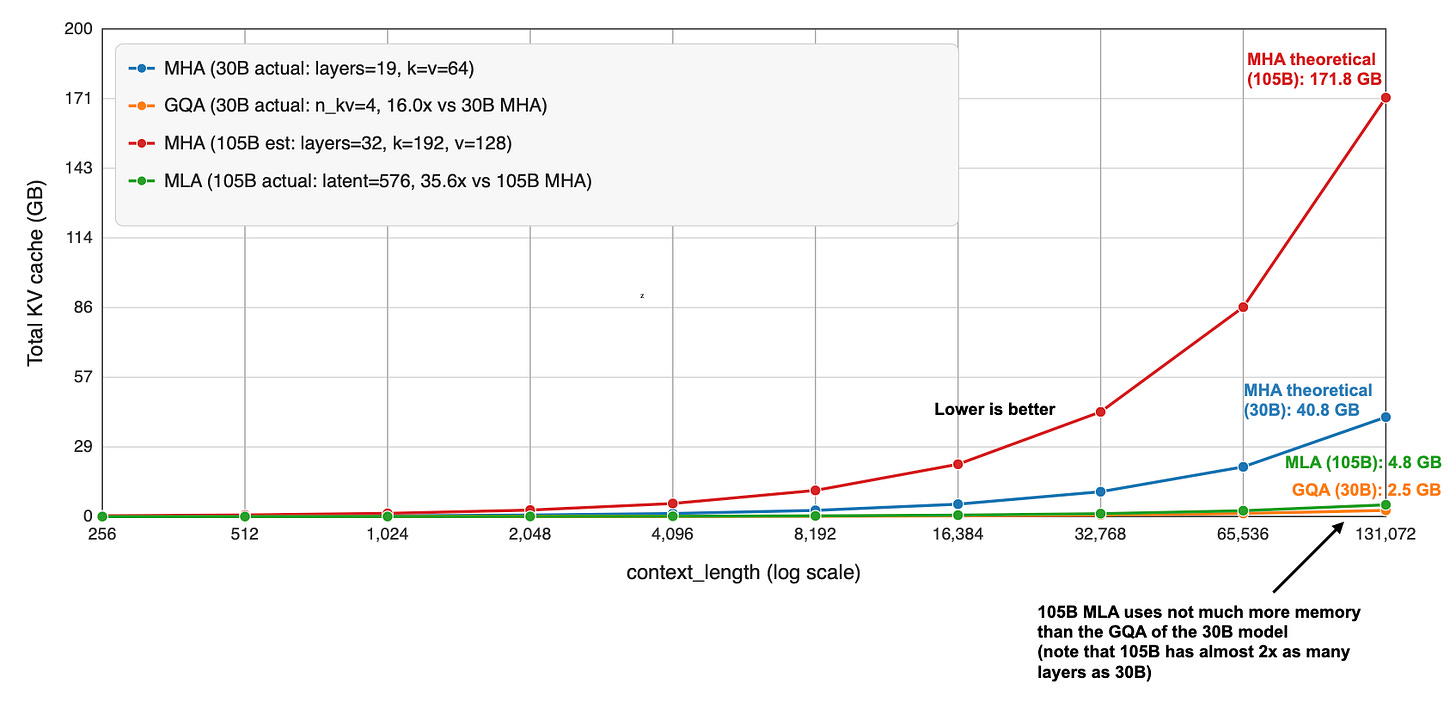
MLA 實現起來更複雜,但如果根據 2024 年 DeepSeek V2 論文中的消融研究(據我所知,這仍是最近的同類比較),它可以提供更好的建模性能。
說到建模性能,105B 模型與同等規模的 LLM 持平:gpt-oss 120B 和 Qwen3-Next (80B)。Sarvam 在某些任務上表現更好,在其他任務上表現較差,但平均而言大致相同。
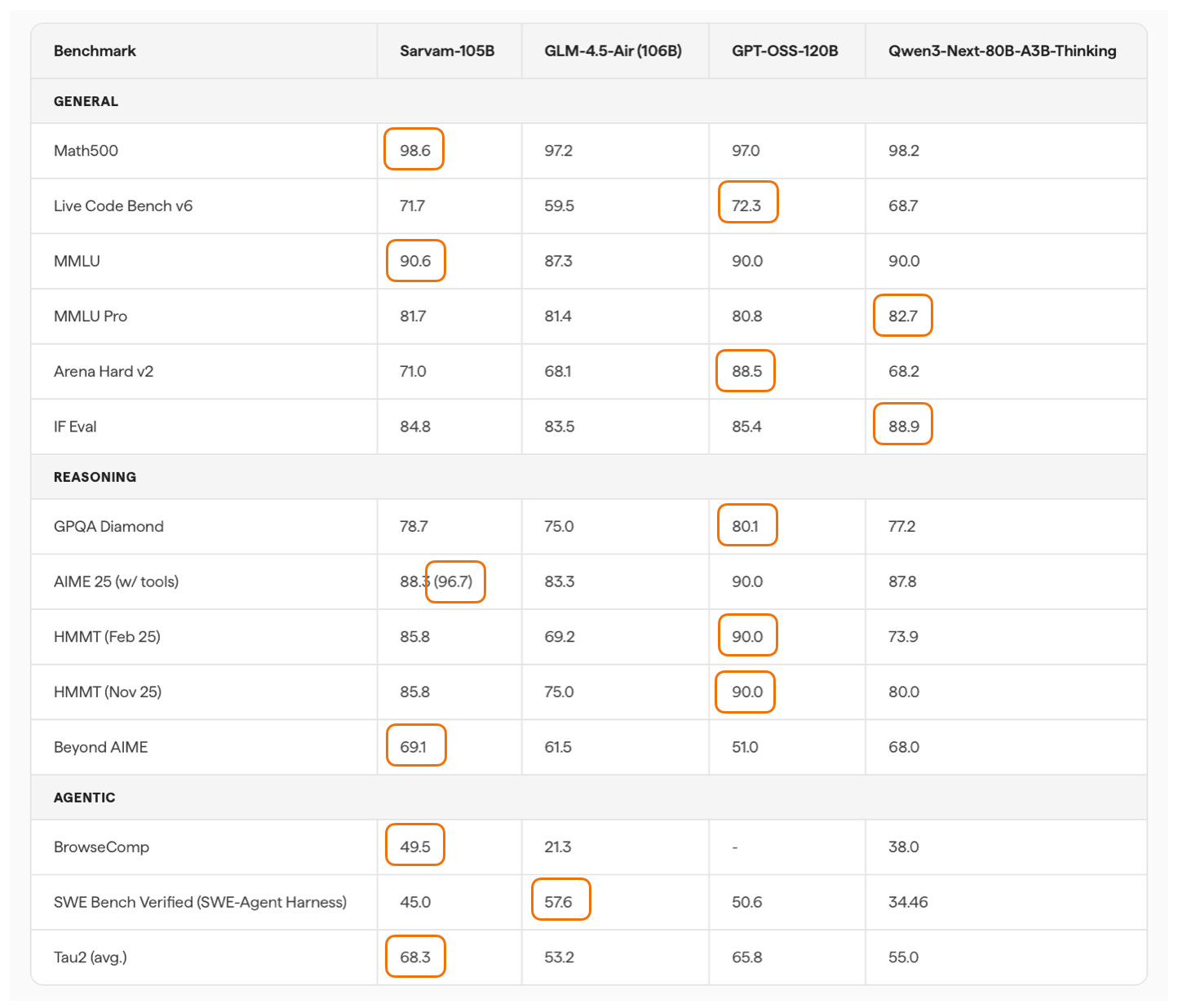
就 SWE-Bench Verified 而言,它不是最強的編程模型,但在 Agent 推理和任務完成 (Tau2) 方面出奇地好。它甚至優於 Deepseek R1 0528(未在圖中顯示)。
考慮到較小的 Sarvam 30B,與 30B 模型最可比的模型可能是 Nemotron 3 Nano 30B,後者在 SWE-Bench Verified 編程和 Agent 推理 (Tau2) 方面略微領先,但在其他一些方面(Live Code Bench v6, BrowseComp)略遜一籌。
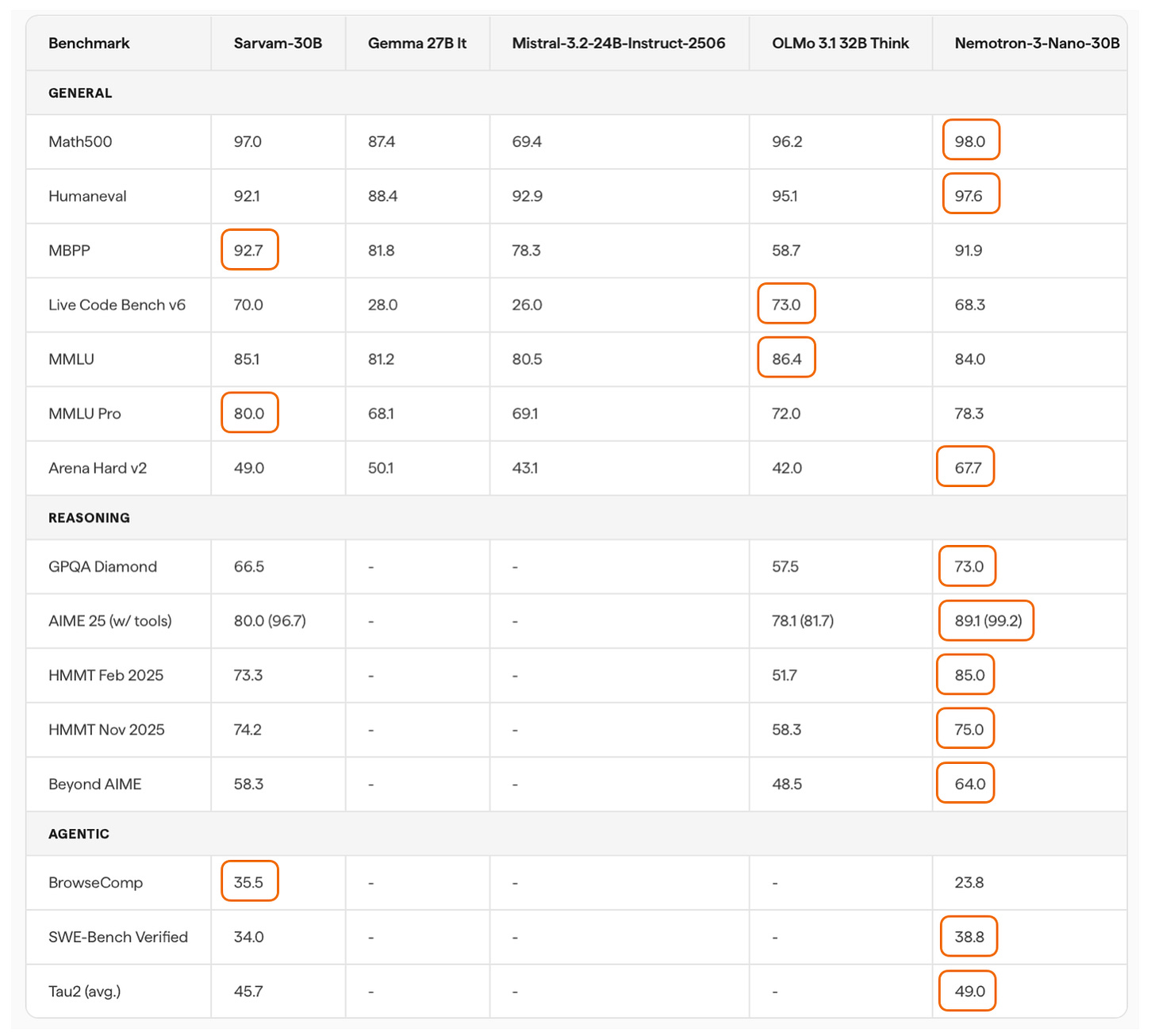
遺憾的是,上述基準測試中缺少了 Qwen3-30B-A3B,據我所知,它是該規模級別中最受歡迎的模型。不過有趣的是,Sarvam 團隊在計算性能分析中將其 30B 模型與 Qwen3-30B-A3B 進行了比較,發現由於代碼和內核優化,Sarvam 的 token/sec 吞吐量比 Qwen3 高出 20-40%。
上述基準測試未捕捉到的一點是 Sarvam 在印度語言上的出色表現。根據一個評判模型,Sarvam 團隊發現,在處理印度文本時,他們的模型在 90% 的情況下比其他模型更受青睞。(由於他們還從頭開始構建和訓練了分詞器,Sarvam 在印度語言上的 token 效率也高出 4 倍。)
本雜誌是一個個人熱情項目,您的支持有助於維持它的生命力。
如果您想支持我的工作,請考慮訂閱或購買我的《從頭開始構建大型語言模型》一書或其後續作品《從頭開始構建推理模型》。(我相信您會從中獲益匪淺;它們深入解釋了 LLM 的運作方式,這是其他地方找不到的。)
感謝閱讀,並感謝支持獨立研究!
如果您讀過這本書並有幾分鐘空閒時間,我將非常感激您的簡短評論。這對我們作者幫助很大!
您的支持意義重大!謝謝!