Anthropic 教育報告:AI 流利度指數
Anthropic 教育報告:AI 流利度指數

人們將 AI 工具融入日常生活的速度,在短短一年前都還難以預測。但僅憑採用率並不能告訴我們這些工具產生的影響。另一個同樣重要的問題是:隨著 AI 成為日常生活的一部分,個人是否正在培養善用它的技能?
之前的 Anthropic 教育報告研究了大學生和教育工作者如何使用 Claude。我們發現學生用它來撰寫報告和分析實驗結果;教育工作者則用它來製作教材和自動化例行工作。但我們知道,任何使用 AI 的人都有可能在工作表現上有所提升。我們希望進一步探索這一點,並了解使用 AI 的人如何隨著時間的推移,對這項技術產生「流利度」(fluency)。
在本報告中,我們開始回答這個問題。我們透過大量匿名對話樣本,追蹤一組代表 AI 流利度的行為分類是否存在。
與我們最近發佈的經濟指數一致,我們發現 AI 流利度最常見的表現是「增強式」的——將 AI 視為思考夥伴,而非完全委派工作。事實上,這類對話展現出的 AI 流利行為數量,是快速簡短對話的兩倍以上。
但我們也發現,當 AI 產生「成品」(Artifacts)時——包括應用程式、程式碼、文件或互動工具——使用者質疑其推理過程的可能性較低(下降 3.1 個百分點),識別缺失背景資訊的可能性也較低(下降 5.2 個百分點)。這與我們最近關於程式編寫技能研究中觀察到的相關模式一致。
這些初步發現為我們提供了一個基準,可用於研究 AI 流利度隨時間發展的情況。
衡量 AI 流利度
為了量化 AI 流利度,我們使用了由 Rick Dakan 教授和 Joseph Feller 教授與 Anthropic 合作開發的「4D AI 流利度框架」。該框架幫助我們定義了 24 種特定行為,我們認為這些行為體現了安全且有效的人機協作。
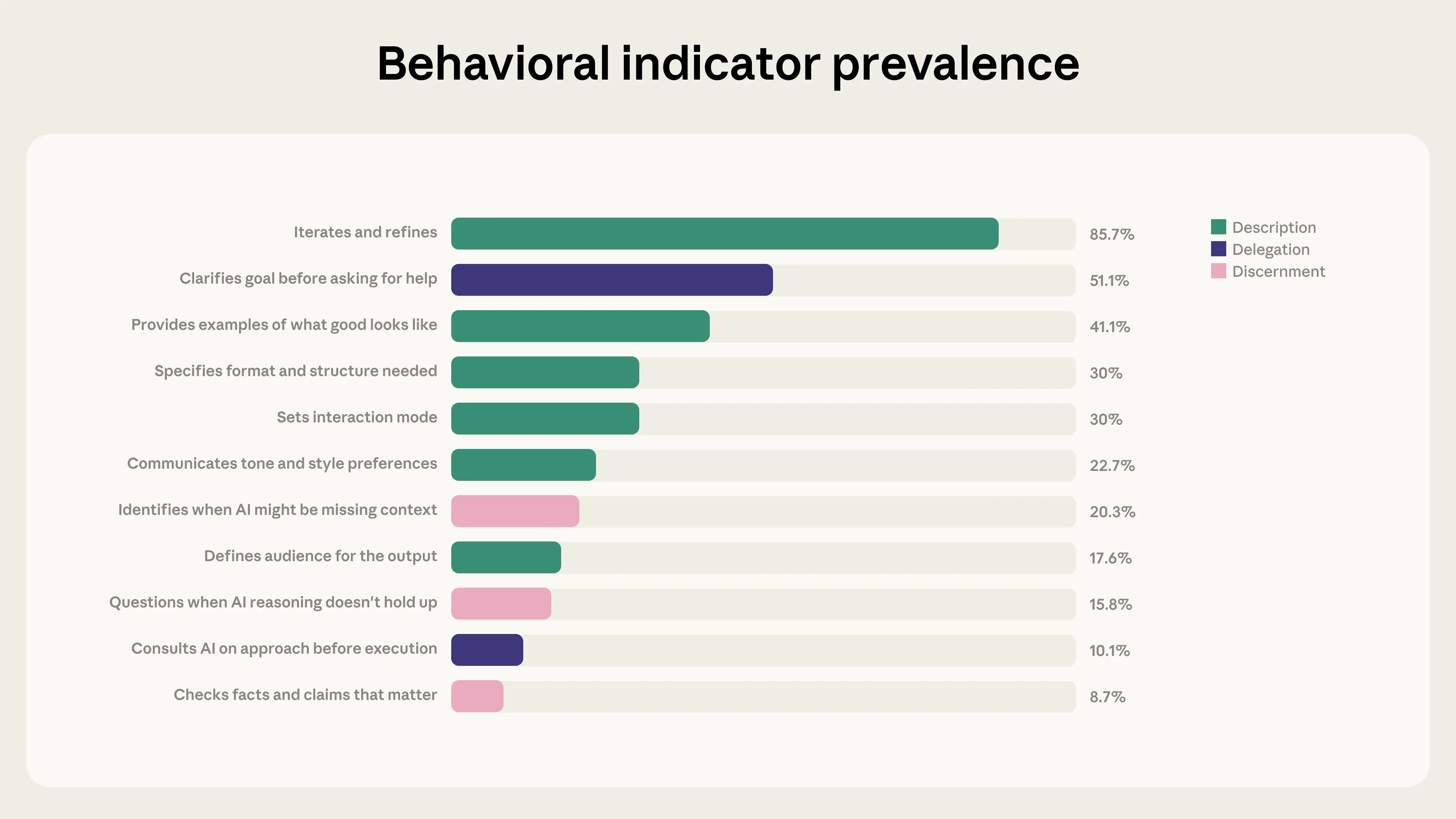
在這 24 種行為中,有 11 種(列於下圖)是在人類於 Claude.ai 或 Claude Code 上與 Claude 互動時可以直接觀察到的。其他 13 種(包括誠實說明 AI 在工作中的角色,或考慮分享 AI 生成內容的後果等)發生在 Claude.ai 的聊天介面之外,因此我們很難追蹤。這些不可觀察的行為可以說是 AI 流利度中最重要的維度,因此在未來的研究中,我們計劃使用定性方法來評估它們。
在本次研究中,我們專注於 11 種直接可觀察的行為。我們使用保護隱私的分析工具,研究了 2026 年 1 月為期 7 天內,包含多次與 Claude 往返對話的 9,830 個對話樣本。1 接著我們測量了這 11 種行為的出現與否;每個對話都可能展現多種行為的證據。我們透過檢查結果在每週各天以及樣本中不同語言之間是否一致,來評估樣本的可靠性(我們發現結果是一致的)。2 最終,這為我們提供了「AI 流利度指數」:一個衡量當前人們如何與 AI 協作的基準,也為追蹤這些行為如何隨模型變化而演進奠定了基礎。
研究結果
透過這項初步研究,我們在 Claude 的使用中發現了兩個主要模式:AI 流利度與透過較長對話進行的「迭代與完善」之間存在強烈關聯,以及使用者在編寫程式或建立其他產出時,流利度行為會發生變化。
流利度與展現「迭代與完善」的對話高度相關
數據中最強大的模式之一,是「迭代與完善」與所有其他 AI 流利行為之間的關係。樣本中 85.7% 的對話展現了迭代與完善:即在之前的交流基礎上精進使用者的工作,而非接受第一個回覆就轉向新任務。如下表所示,這些對話在其他流利行為上的比例顯著更高:
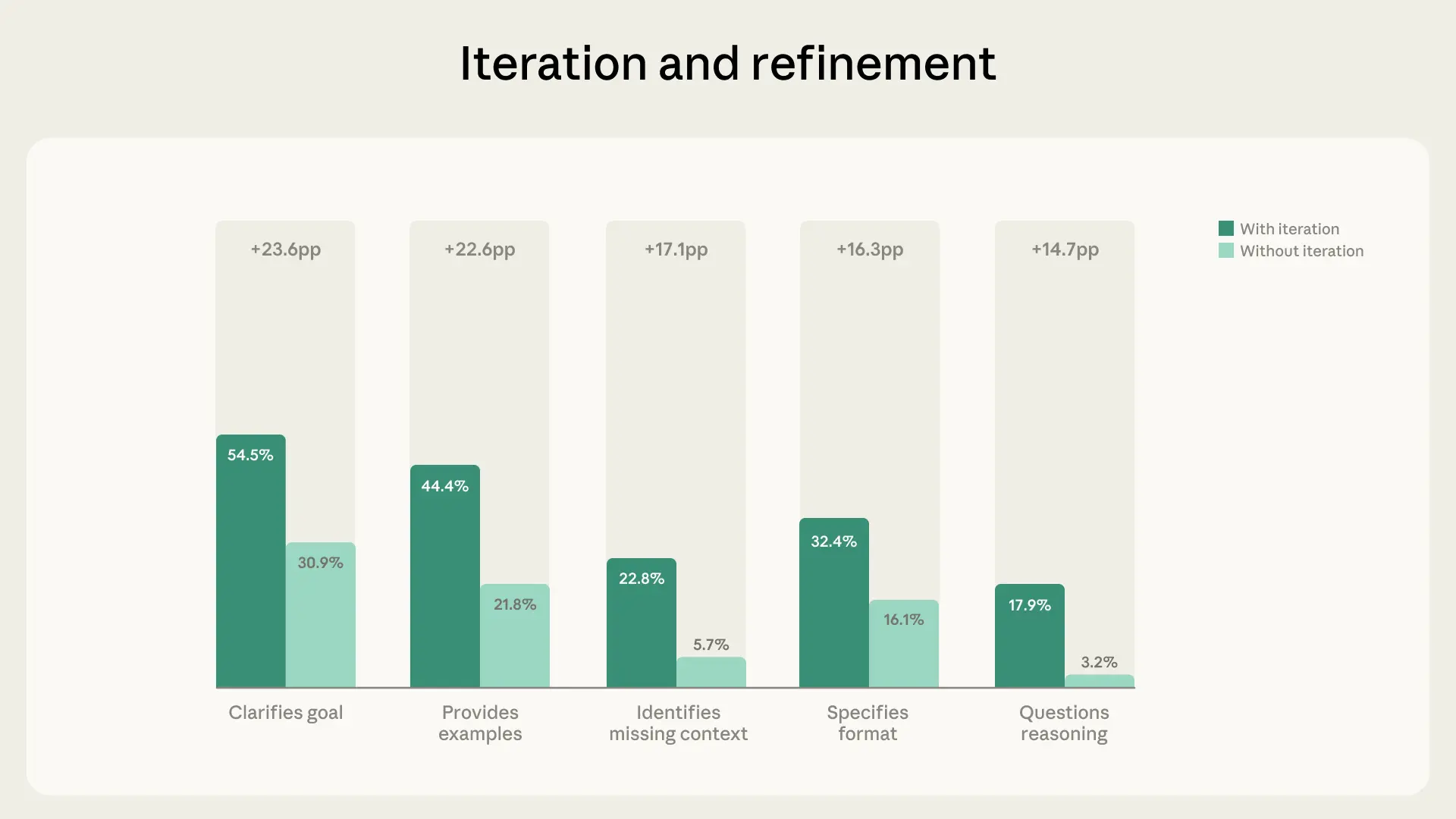
平均而言,具有迭代與完善過程的對話會多展現 2.67 個流利行為——大約是非迭代對話(1.33 個)的兩倍。這在與評估 Claude 輸出相關的流利行為中尤為明顯。具有迭代與完善過程的對話,使用者質疑 Claude 推理的可能性高出 5.6 倍,識別缺失背景資訊的可能性高出 4 倍。
在建立產出時,使用者變得更具指令性,但評估性降低
樣本中 12.3% 的對話涉及「成品」(Artifacts),包括程式碼、文件、互動工具和其他產出。在這些對話中,人們與 AI 協作的方式截然不同。
具體而言,我們發現屬於「描述」和「委派」大類別下的行為比例顯著升高。例如,與非成品對話相比,這些對話中的使用者更有可能澄清目標(+14.7 個百分點)、指定格式(+14.5 個百分點)、提供範例(+13.4 個百分點)以及進行迭代(+9.7 個百分點)。換句話說,他們在工作開始時做了更多引導 AI 的工作。
但這種指令性並沒有對應到更高水平的評估或辨別能力。事實上,情況正好相反:在建立成品的對話中,使用者識別缺失背景資訊(-5.2 個百分點)、查證事實(-3.7 個百分點)或透過要求模型解釋其原理來質疑其推理(-3.1 個百分點)的可能性較低。我們的經濟指數發現——意料之中的是——最複雜的任務正是 Claude 最吃力的地方,因此這一點似乎特別值得注意。
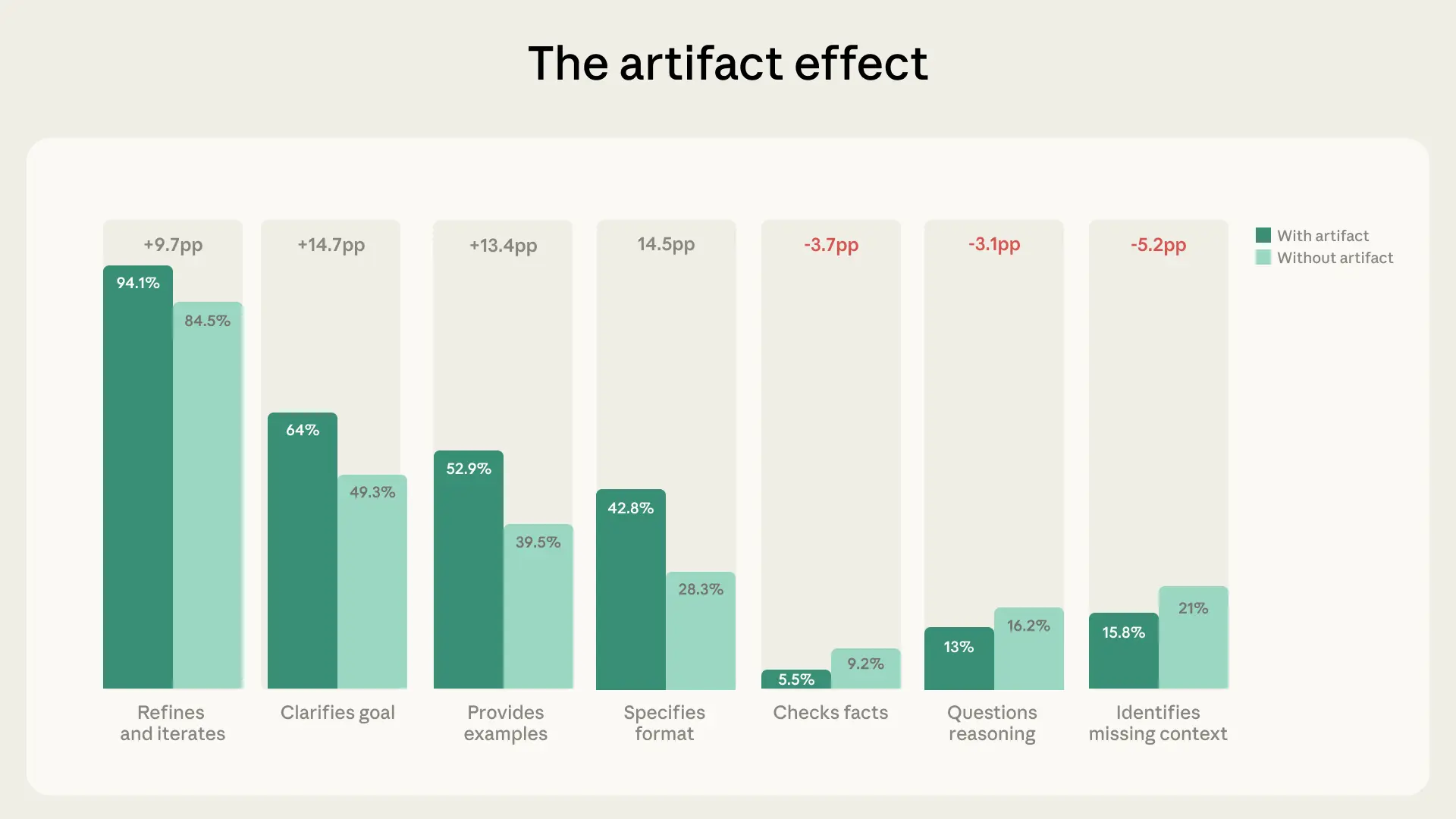
這種模式有幾種可能的解釋。可能是因為 Claude 產出了精美、看起來功能完備的成品,讓人覺得沒必要進一步質疑:如果作品看起來已經完成了,使用者可能會直接接受。但也可能是因為成品對話涉及的任務中,事實精確度不如美觀或功能性重要(例如設計 UI 與撰寫法律分析)。或者,使用者可能正在透過我們無法觀察到的管道評估成品——例如在別處執行程式碼、測試應用程式、與同事分享草稿——而不是在同一個初始對話中表達他們的評估。
無論解釋為何,這種模式都值得關注。隨著 AI 模型產出精美作品的能力日益增強,批判性評估這些產出的能力(無論是在直接對話中還是透過其他方式)將變得越來越有價值,而非相反。
培養您自己的 AI 流利度
局限性
本研究包含以下重要注意事項:
展望未來
這項研究為我們提供了一個基準,可用於評估 AI 流利度隨時間變化的情況。隨著 AI 能力的演進和採用率的增加,我們旨在了解使用者是否正在發展出更複雜的行為、哪些技能會隨著經驗自然產生,以及哪些技能需要更有意識地培養。
在未來的研究中,我們計劃從幾個方向擴展分析。首先,我們計劃進行「群體分析」(cohort analyses),比較新使用者與資深使用者,以了解對 AI 的熟悉程度與流利度發展之間的相關性。其次,我們計劃使用定性研究方法來評估在 Claude.ai 對話中無法直接觀察到的行為。第三,我們旨在探索這項工作提出的因果問題——例如鼓勵迭代對話是否會導致更強的批判性評估,或者是否有其他干預措施可以更有效地鼓勵這一點。
此外,我們希望探索 Claude Code 中的 AI 流利行為,這是一個主要由軟體開發人員使用的平台。在準備這項研究時,我們進行了一些初步分析,發現 Claude Code 對話與 Claude.ai 對話之間具有一致性。但這仍是初步的,Claude Code 非常不同的使用者群體和功能意味著需要進行更深入的研究。
我們預計 AI 流利度的本質將隨時間發生重大發展與演變。透過這項及未來的研究,我們旨在使這種發展變得可見、可衡量且可採取行動。
Bibtex
如果您想引用此貼文,可以使用以下 Bibtex 鍵值:
致謝
Kristen Swanson 設計了本研究,領導了分析並撰寫了此報告。Zoe Ludwig 和 Drew Bent 在框架對齊、訊息傳遞和審查方面做出了貢獻。AI 流利度 4D 框架由 Rick Dakan 和 Joe Feller 開發。Zack Lee 提供了技術支持。Hanah Ho 協助了數據視覺化。Keir Bradwell、Rebecca Hiscott、Ryan Donegan 和 Sarah Pollack 提供了通訊審查和指導。
腳註
1 在研究人們如何使用 AI 模型時,保護使用者隱私至關重要。對於此專案,我們使用了保護隱私的分析工具,該工具透過將使用者對話提煉為高層次的使用摘要(如「排除程式碼錯誤」或「解釋經濟概念」),實現對 AI 使用模式的自下而上探索。在本次分析中,我們使用 Claude Sonnet 4 進行行為分類,並使用 Claude Haiku 3.5 進行語言檢測,運行了 11 個獨立的二元分類器(每個行為指標一個)。這意味著單個對話可能顯示多個 AI 流利度行為指標。對話經過篩選,僅保留具有多次往返的實質性交流,排除了問候、單詞交流、測試訊息和純聊天。對 200 個被篩選掉的聊天進行人工審查後發現,這類聊天不符合任何 AI 流利度指標,因此我們有信心篩選器不會影響研究中觀察到的 AI 流利行為的相對排名。分析中不出現任何個人識別資訊。
2 行為指標是根據為期一週的樣本(2025 年 1 月 20 日至 26 日)計算的,且每天保持穩定,大多數行為的波動僅在 1-5 個百分點之間。週六的某些行為比例略低(例如,週六的迭代與完善比例為 81.4%,而工作日高峰為 87.9%),這表明隨意使用與有目的使用之間存在微小差異,但沒有哪一天顯示出有意義的結構性偏差。六種語言(英語、法語、西班牙語、中文、日語和德語)的比例也保持一致,大多數行為在不同語言組別間的差異在 3 個百分點以內。總之,這些發現表明這裡捕捉到的行為模式反映了人們與 AI 互動的穩定習慣,而非時間、星期幾或語言文化背景的產物。
相關內容
關於我們對 Claude Opus 3 模型棄用承諾的更新
人格選擇模型
在實踐中衡量 AI 代理的自主性