Scheduling in a Changing World: Maximizing Throughput with Time-Varying Capacity
Google Research
Algorithms & Theory
Google Research
Algorithms & Theory
AI 生成摘要
Google Research 推出新的、經證明有效的演算法,用於在機器可用性不斷波動的雲端基礎設施上進行工作排程,以最大化吞吐量。
我們努力創造一個有利於跨越多種不同時間尺度和風險等級的各種研究的環境。
我們的研究人員透過基礎和應用研究推動電腦科學的進步。
我們定期與更廣泛的研究社群開放原始碼專案,並將我們的開發應用於 Google 產品。
發表我們的成果使我們能夠分享想法並協同工作,以推進電腦科學領域。
我們向所有人提供產品、工具和資料集,目標是建立一個更具協作性的生態系統。
透過廣泛的程式設計來支持下一代研究人員。
透過與大學教師的有意義的互動參與學術研究社群。
透過活動與更廣泛的研究社群建立聯繫對於在我們工作的各個方面取得進展至關重要。
2026 年 2 月 11 日
Manish Purohit,Google Research 研究科學家
我們介紹了新的、可證明有效的演算法,用於在機器可用性不斷波動時,在雲端基礎架構上排程不中斷的作業。
在演算法作業排程的世界中,計算資源通常被視為靜態的:一台伺服器具有固定數量的 CPU,或者一個叢集具有恆定數量的可用機器。然而,現代大規模雲端運算的現實要動態得多。由於硬體故障、維護週期或電力限制,資源不斷波動。
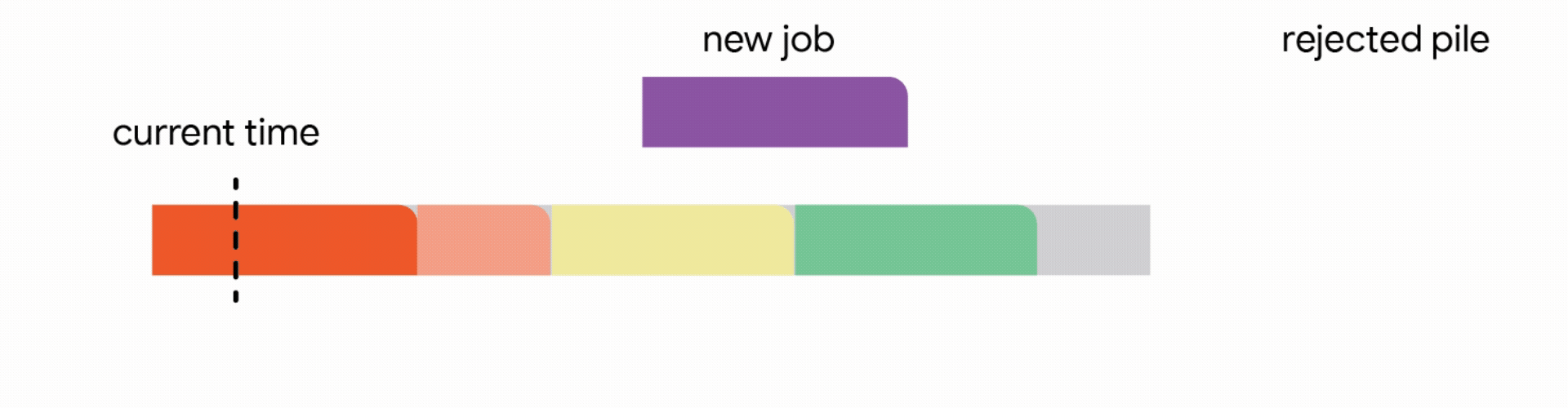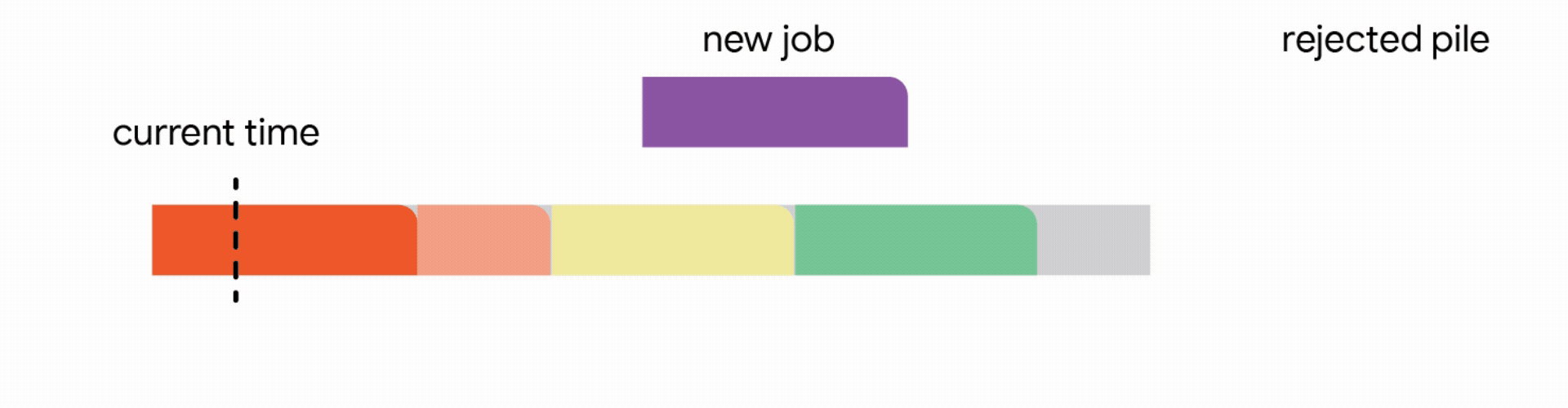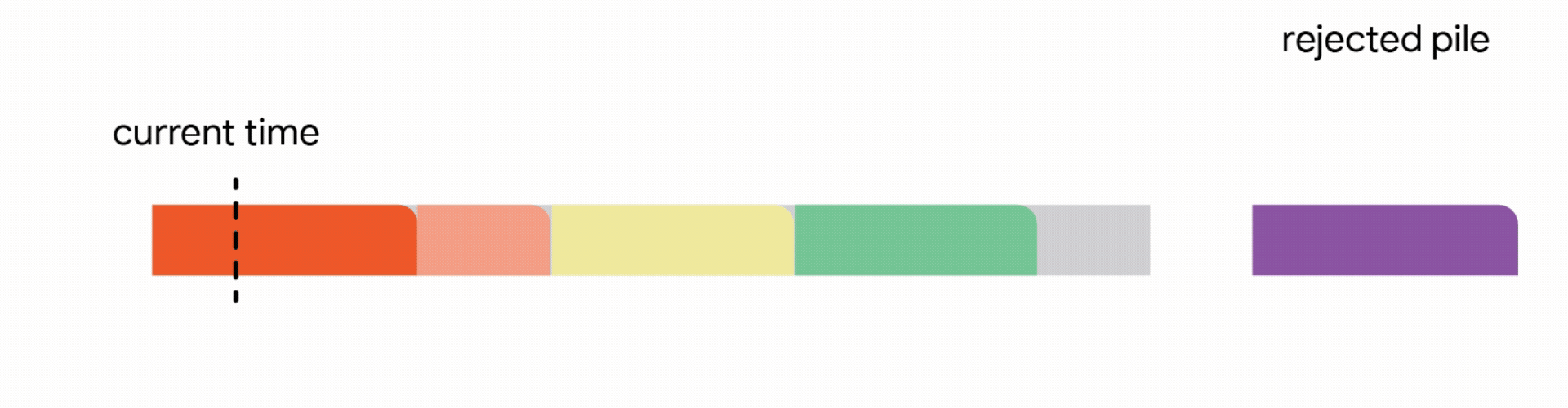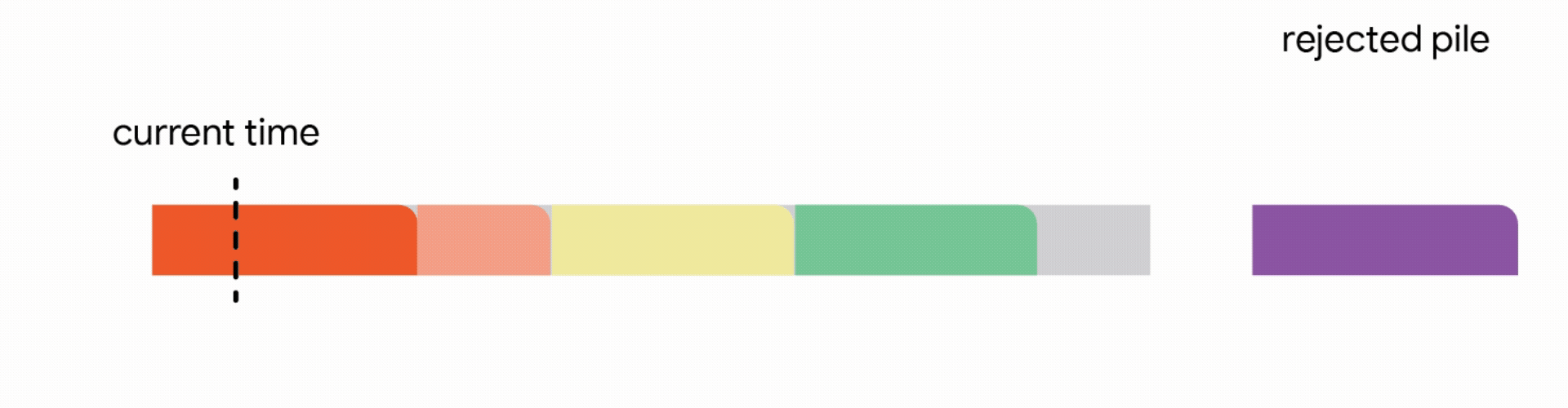
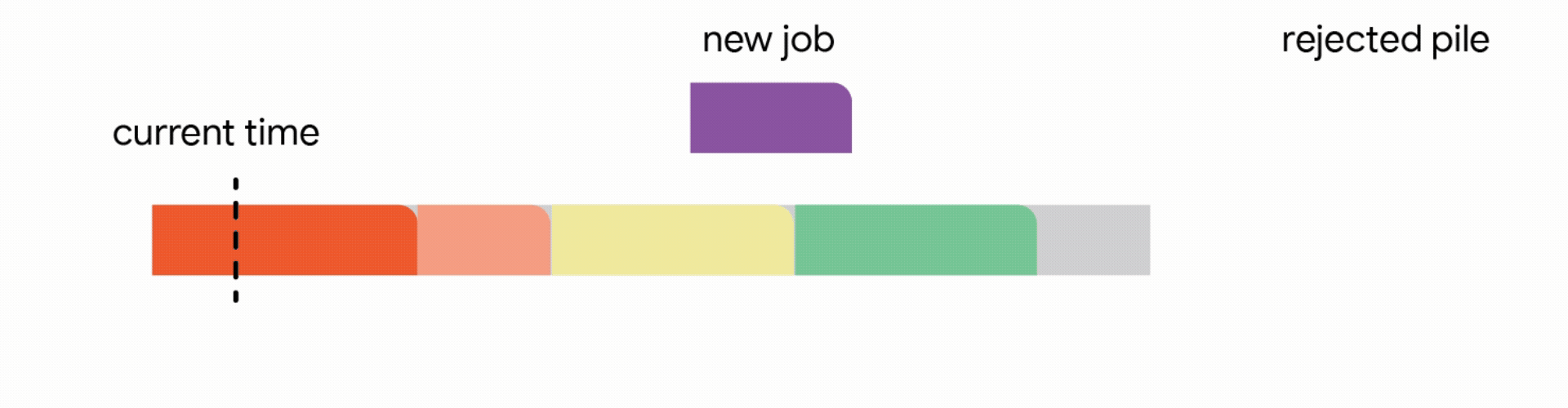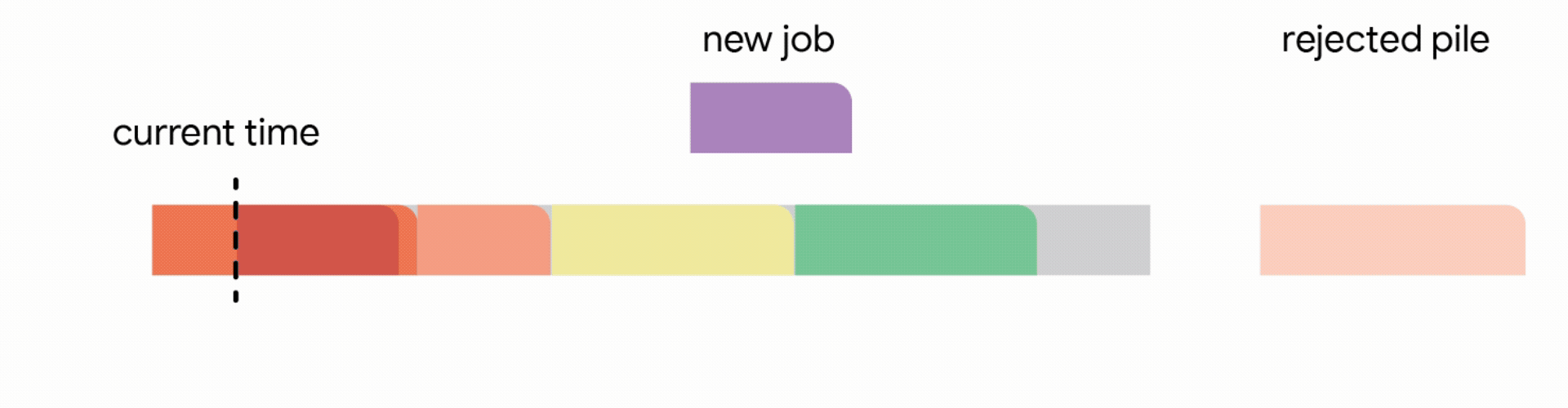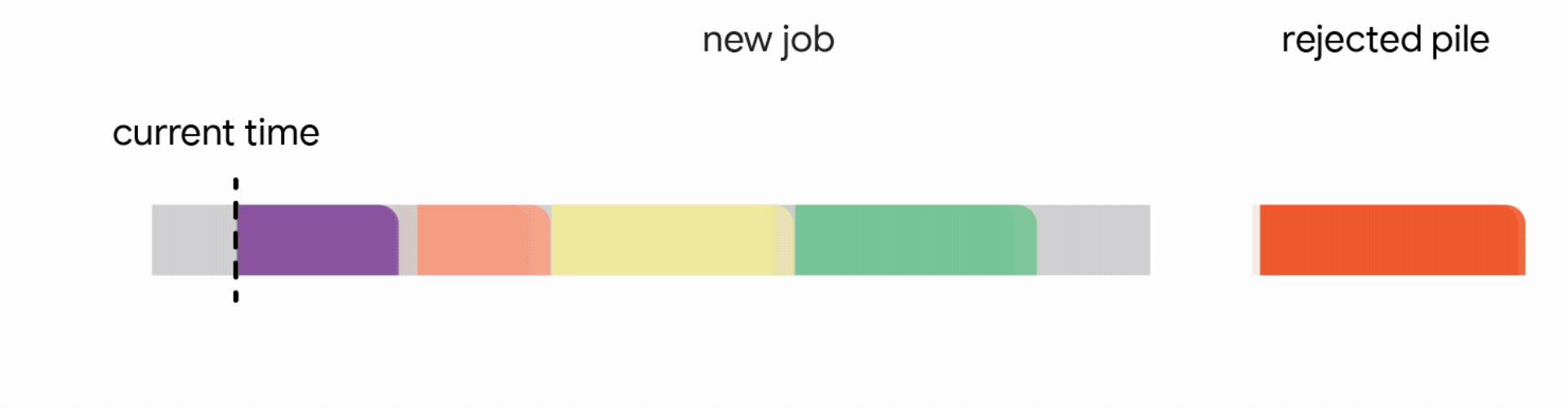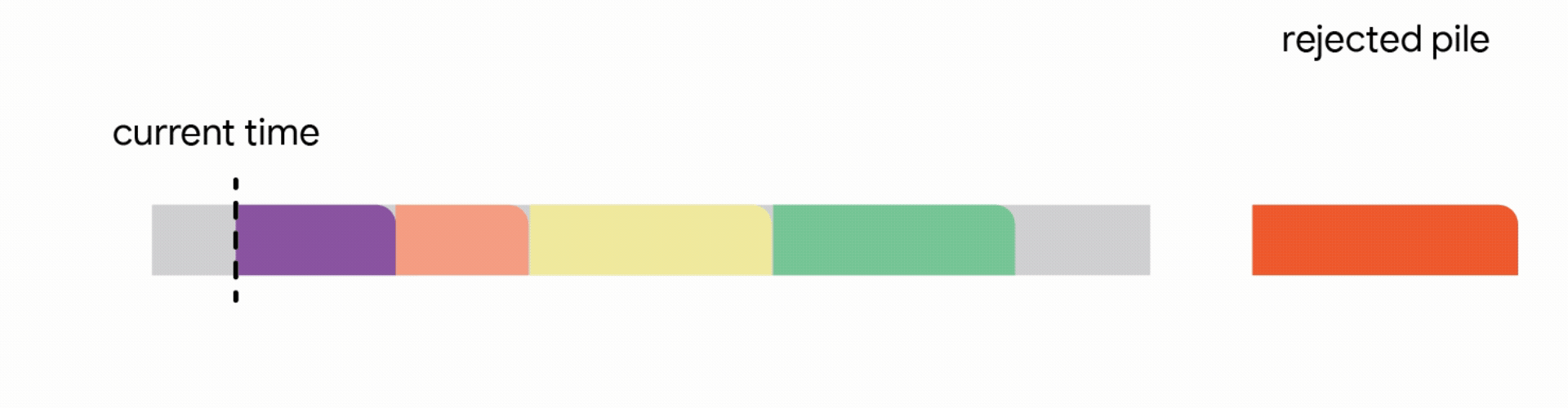
更重要的是,在分層排程系統中,高優先順序的任務通常會按需聲明資源,為低優先順序的批次作業留下時變的「剩餘」容量。想像一家餐廳,其中的桌子在不同的時間為 VIP 保留;在剩餘的桌子上安排普通顧客可能變成一個複雜的難題。
當這些低優先順序的作業是非搶佔式的(意味著它們不能被暫停並稍後恢復)時,風險很高。如果作業因容量下降而中斷,所有進度都將丟失。排程器必須決定:我們現在開始這個長時間的作業,冒著未來容量下降的風險嗎?還是我們等待一個更安全的窗口,可能會錯過截止日期?
在 SPAA 2025 上發表的「時變容量下非搶佔式吞吐量最大化」中,我們開始研究在可用容量隨時間波動的環境中最大化吞吐量(總權重或成功作業的數量)。我們的研究為這個問題的幾個變體提供了第一個常數因子(即,無論問題變得多大,演算法的答案與最佳答案之間的「差距」都保證是一個固定的、穩定的數字)近似演算法,為在不穩定的雲端環境中構建更強大的排程器提供了理論基礎。
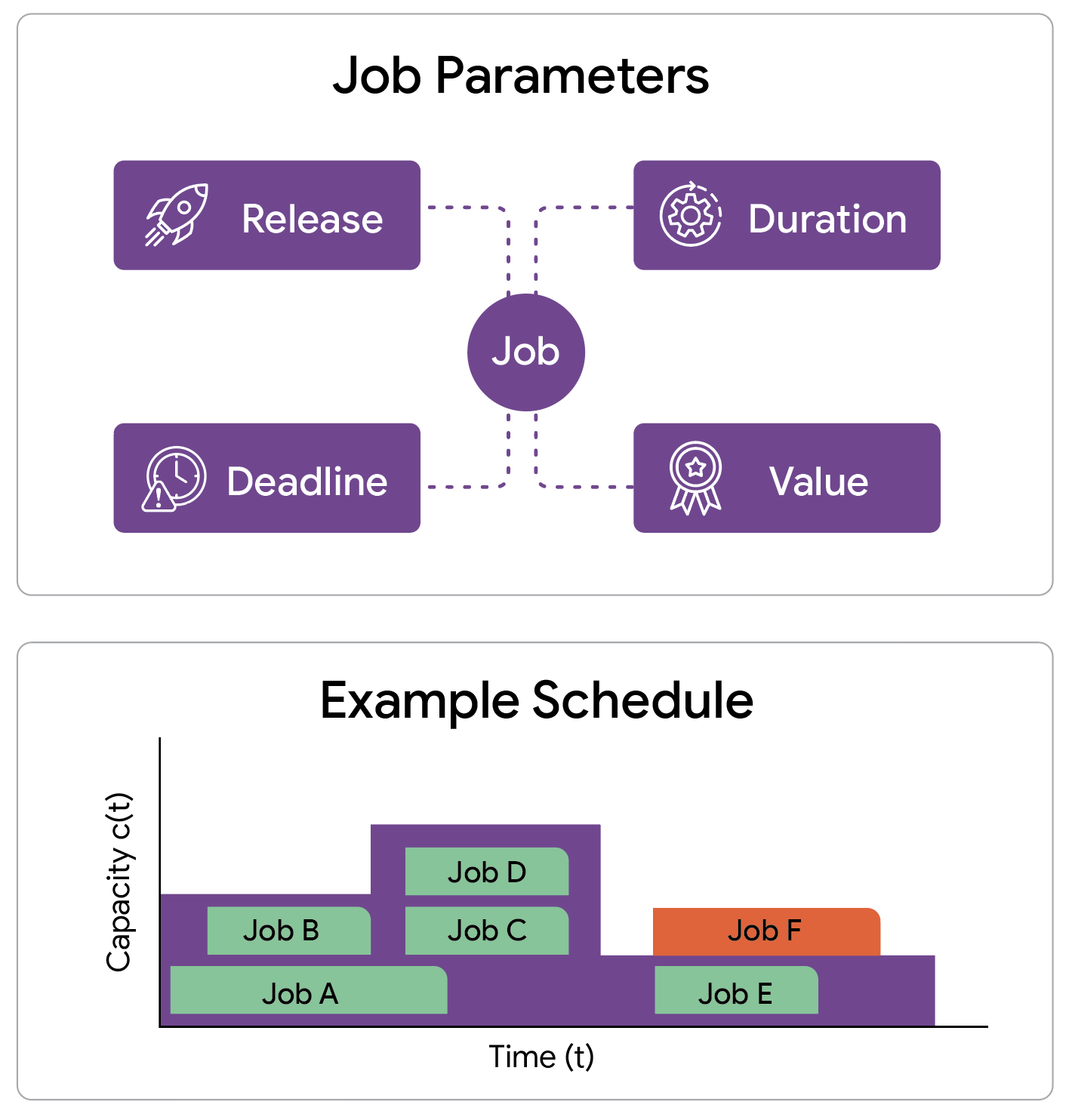
我們的工作重點是設計一個排程模型,該模型可以捕捉許多關鍵約束。我們考慮一台機器(或叢集),其容量配置隨時間變化。此配置決定了在任何給定時刻可以並行運行的最大作業數。我們得到了一組潛在的作業,每個作業都具有四個關鍵屬性:
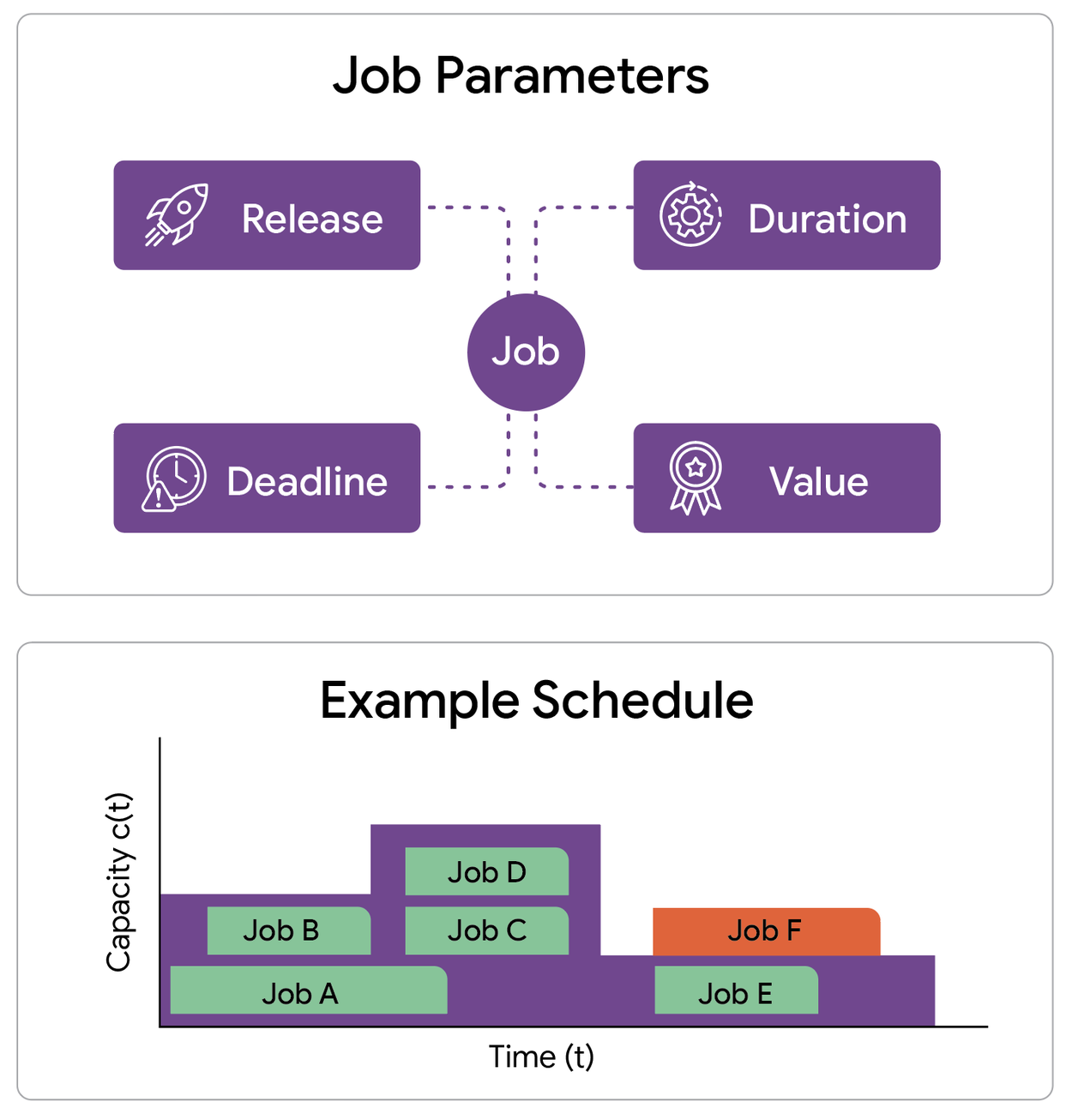
吞吐量最大化問題的一個實例包含一組作業,每個作業都有其發布時間、截止日期、持續時間和價值,以及機器的容量配置。容量配置決定了在任何給定時間可以同時處理的最大作業數。
目標是選擇一個作業子集並對其進行排程,以便每個選定的作業在其有效窗口內連續運行。關鍵約束是,任何時候,正在運行的作業總數都不得超過當前容量。我們的目標是最大化吞吐量,即所有已完成作業的總權重。
我們在兩個不同的環境中解決這個問題:
在我們可以提前計畫的離線設定中,我們發現簡單的策略表現出奇地好。由於在這種設定中找到最佳排程被認為是「NP-hard」(即,沒有已知的捷徑可以找到完美的答案),因此我們專注於具有嚴格近似保證的演算法。我們分析了一種稱為 Greedy 的短視策略,該策略迭代地排程最早完成的作業,並證明當作業具有單位利潤時,這種簡單的啟發式方法可以實現 1/2 近似(在這種情況下,通常是最好的)。這意味著即使在最壞的情況下,作業和容量配置都是對抗性選擇的,我們的簡單演算法也保證至少排程最佳作業數的一半。這與 Greedy 在更簡單的、一次只能執行一項任務的單位容量機器上所享有的保證相符。當不同的作業可以具有不同的相關利潤時,我們利用原始對偶框架來實現 1/4 近似。
真正的複雜性在於線上設定,在線上設定中,作業是動態到達的,排程器必須立即做出不可撤銷的決定,而不知道接下來會到達哪些作業。我們透過其競爭比率來量化線上演算法的效能,競爭比率是我們的線上演算法的吞吐量與預先知道所有作業的最佳演算法的吞吐量之間的最壞情況比較。
標準的非搶佔式演算法在這裡完全失敗,因為它們的競爭比率接近於零。發生這種情況的原因是,排程長時間作業的一個錯誤決定可能會破壞排程許多未來較小作業的可能性。在這個例子中,如果你想像一下,無論長度如何,每個已完成的作業都帶來相同的權重,那麼完成許多短作業比完成一個長作業更有利可圖。
為了使線上問題可解決並反映真實世界的靈活性,我們研究了兩種模型,這些模型允許在出現更好的機會時中斷活動作業(儘管只有重新啟動並稍後以非搶佔方式完成的作業才算作成功)。
在這個模型中,允許線上演算法中斷當前正在執行的作業。雖然已經對中斷的作業執行的部分工作會丟失,但作業本身仍保留在系統中並且可以重試。
我們發現,允許作業重新啟動所提供的靈活性非常有益。迭代地排程最早完成的作業的 Greedy 變體繼續實現 1/2 競爭比率,與離線設定中的結果相符。
在這個更嚴格的模型中,對中斷的作業執行的所有工作都會丟失,並且作業本身會永遠丟棄。不幸的是,我們發現,在這個嚴格的模型中,任何線上演算法都可能遇到一系列作業,這些作業會迫使它做出阻止它在未來滿足更多工作的決定。再次,所有線上演算法的競爭比率都接近於零。分析上述困難實例使我們專注於所有作業共享一個共同截止日期的實際場景(例如,所有資料處理都必須在夜間批次運行之前完成)。對於這種常見的截止日期實例,我們設計了新穎的常數競爭演算法。我們的演算法非常直觀,我們在這裡描述了單位容量配置的簡單設定的演算法,即我們可以在任何時間排程單個作業。
在這種設定中,我們的演算法透過將已到達的作業分配到不相交的時間間隔來維護一個暫定排程。當一個新的作業到達時,演算法透過從以下四個動作中選擇第一個適用的動作來修改暫定排程:
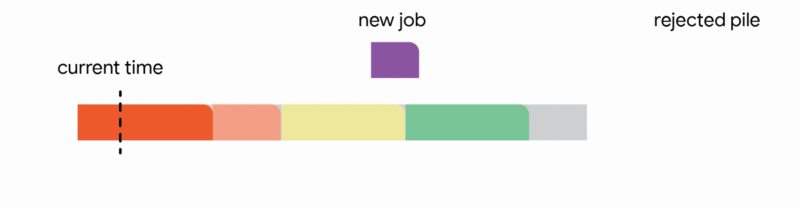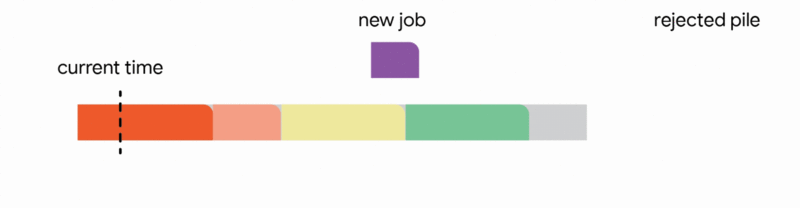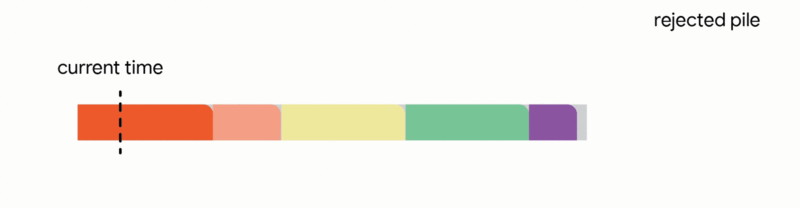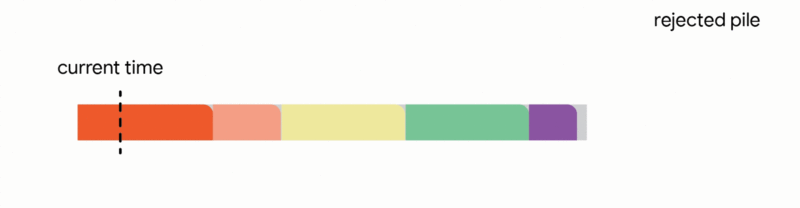
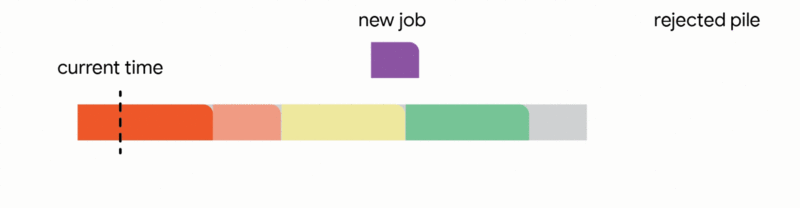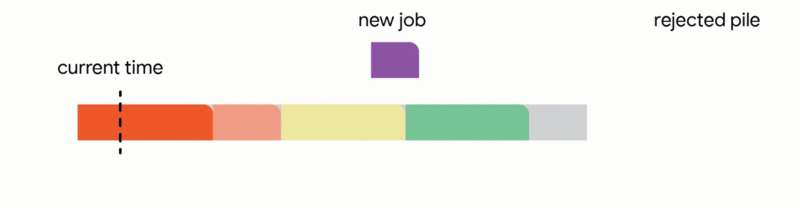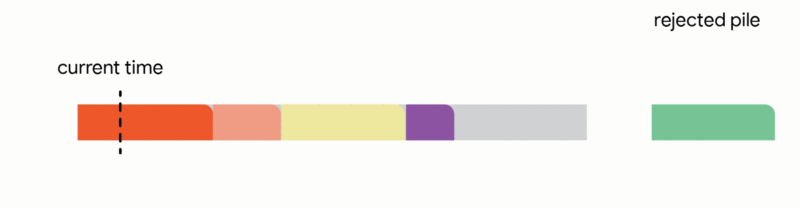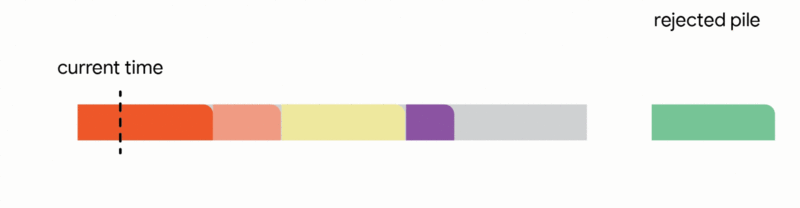
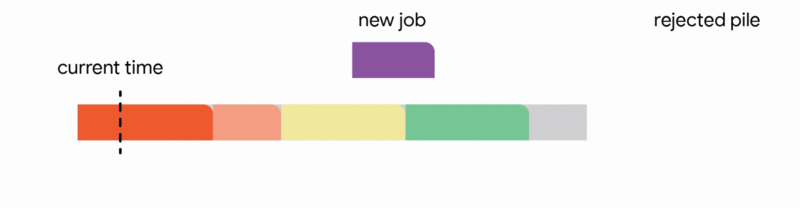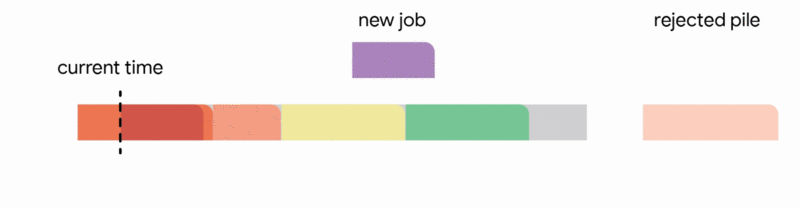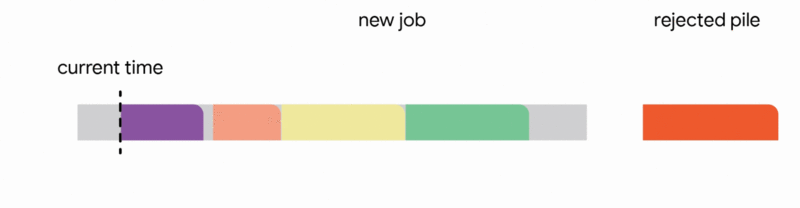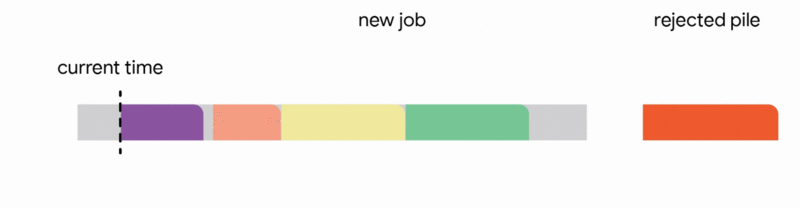
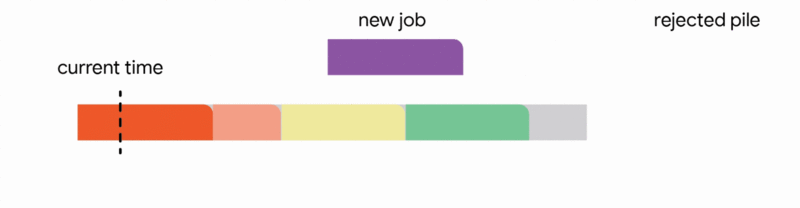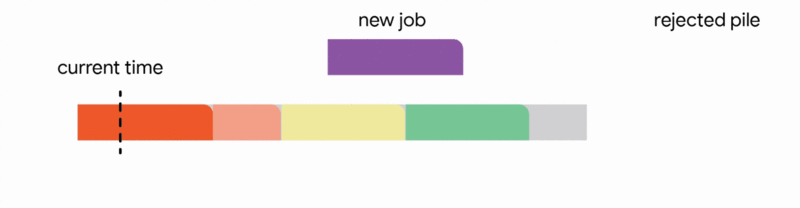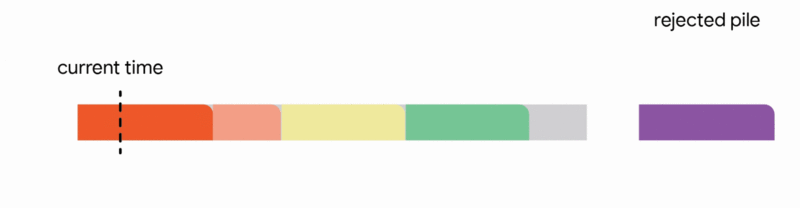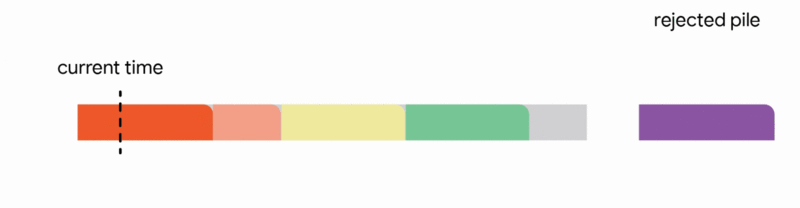
我們的主要結果表明,將此演算法推廣到任意容量配置可以為此問題提供第一個常數競爭比率。正式地,我們獲得了 1/11 的競爭比率。雖然保證僅排程最佳作業數的約 9% 聽起來像是一個微弱的保證,但這是一個最壞情況的保證,即使在最不利的情況下也成立。
隨著雲端基礎架構變得越來越動態,排程演算法中靜態容量的假設不再成立。本文啟動了在時變容量下吞吐量最大化的正式研究,彌合了理論排程模型與資料中心波動的現實之間的差距。
雖然我們建立了強大的常數因子近似,但仍有增長空間。我們線上設定的 1/11 競爭比率與 1/2 的理論上限之間的差距表明可能存在更有效的演算法。探索隨機演算法或對未來容量有不完善知識的場景可能會為實際應用產生更好的結果。
這代表與 Aniket Murhekar(伊利諾大學厄巴納香檳分校)、Zoya Svitkina(Google Research)、Erik Vee(Google Research)和 Joshua Wang(Google Research)的共同工作。

2026 年 2 月 4 日

2026 年 1 月 23 日

2026 年 1 月 13 日


追蹤我們