
AI 訓練於鳥類,揭開水下奧秘
2026 年 2 月 9 日
Lauren Harrell,Google Research 資料科學家
我們將描述 Google DeepMind 的生物聲學基礎模型 Perch 2.0,該模型透過訓練於鳥類及其他陸地動物的發聲,以「殺手級」的效能,成功應用於水下聲學挑戰。
水下聲音對於理解海洋物種及其環境中不可見的模式至關重要。海洋聲景充滿了神秘的噪音和未被發現的奧秘。例如,美國國家海洋暨大氣總署(NOAA)近期將神秘的「生物彈簧聲」歸因於難得一見的布氏鯨,這說明了新歌種和物種歸屬的辨識,是一項持續的挑戰。
Google 長期以來一直與外部科學家合作,利用生物聲學監測和保護鯨魚,包括我們最初用於偵測座頭鯨分類的研究模型,以及於 2024 年發布的多物種鯨魚模型。為了跟上這個步伐,Google 在生物聲學領域的 AI 方法不斷演進,以實現從新發現到大規模科學見解的更有效連結。2025 年 8 月,Google DeepMind 發布了最新的 Perch 生物聲學基礎模型 Perch 2.0,這是一個主要訓練於鳥類及其他陸地發聲動物的生物聲學基礎模型。令人驚訝的是,儘管訓練資料中不包含任何水下音訊,Perch 2.0 在海洋驗證任務的遷移學習中,作為嵌入模型表現出色。

白鯨——海洋的「金絲雀」。(圖片來源:Lauren Harrell)
在我們最新的論文「Perch 2.0 將『鯨魚』應用於水下任務」中,Google Research 和 Google DeepMind 的合作成果在 NeurIPS 2025 非人類動物通訊 AI 工作坊上發表,我們將深入探討這些結果。我們展示了這個主要訓練於鳥類資料的生物聲學基礎模型,如何能夠實現並擴展對水下海洋生態系統的見解,特別是對於鯨魚發聲的分類。我們還在 Google Colab 中分享了一個端對端的教學,介紹我們的敏捷建模工作流程,展示如何使用 Perch 2.0,透過 Google Cloud,利用 NOAA NCEI 被動聲學資料歸檔,建立一個自訂的鯨魚發聲分類器。
生物聲學分類如何運作
如果一個預先訓練好的分類模型,例如我們多物種鯨魚模型,已經具備必要的標籤並在研究人員的資料集上表現良好,則可以直接用於產生其音訊資料的分數和標籤。然而,若要為新發現的聲音建立一個自訂分類器,或提高新資料的準確性,我們可以利用遷移學習,而不是從頭開始建立一個新模型。這種方法大大減少了建立新自訂分類器所需的計算和實驗量。
在生物聲學遷移學習中,預先訓練好的模型(如 Perch 2.0)用於為每個音訊視窗產生嵌入。這些嵌入將大型音訊資料縮減為一個較小的特徵陣列,作為簡單分類器的輸入。要為任何標記的音訊資料集建立一個新的自訂模型,我們將預先訓練好的模型應用於音訊資料以獲取嵌入,然後將這些嵌入作為邏輯迴歸分類器的輸入特徵。與學習深度神經網路的所有參數相比,我們現在只需要學習邏輯迴歸最後一步的新參數,這對於研究人員的時間和計算資源都更有效率。
評估
我們使用少樣本線性探測(few-shot linear probe)在海洋任務上評估了 Perch 2.0,例如區分不同的鬚鯨物種或不同的虎鯨亞種。將其效能與我們 Perch Hoplite 儲存庫中用於敏捷建模和遷移學習的預先訓練模型進行比較。這些模型包括 Perch 2.0、Perch 1.0、SurfPerch 和多物種鯨魚模型。
對於水下資料評估,我們使用了三個資料集:NOAA PIPAN、ReefSet 和 DCLDE。
在此協議中,對於給定的帶標籤資料的目標資料集,我們從每個候選模型計算嵌入。然後,我們選擇每類固定數量的樣本(4、8、16 或 32 個),並在嵌入之上訓練一個簡單的多類邏輯迴歸模型。我們使用產生的分類器來計算接收者操作特徵曲線下的面積(AUC_ROC),其中接近 1 的值表示區分類別的能力更強。這個過程模擬了使用給定的預先訓練嵌入模型,從少量標記樣本建立自訂分類器。
我們的結果顯示,每類樣本數量的增加提高了所有模型的效能,除了 ReefSet 資料集,該資料集上的效能即使只有四個樣本,對於所有模型(除了多物種鯨魚模型)都非常高。值得注意的是,Perch 2.0 在每個資料集和樣本大小上,始終是表現最佳或第二最佳的模型。
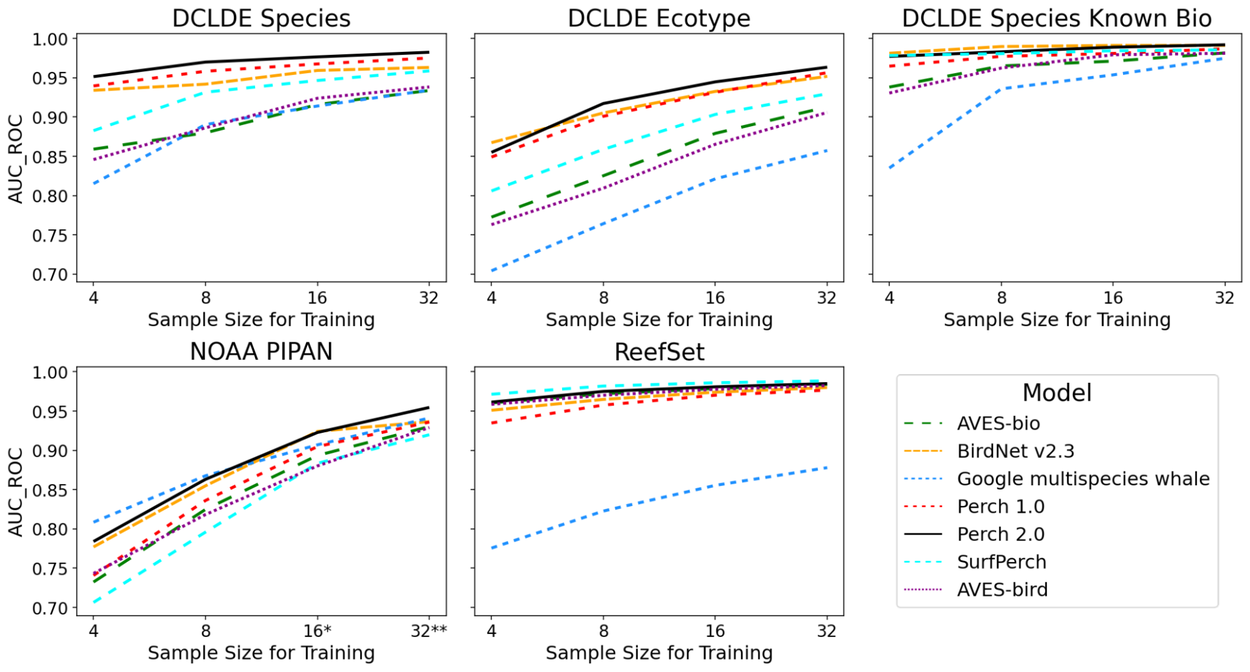
在海洋資料集上訓練模型的效能,樣本數(k)每類訓練樣本數變化。較高的 AUC_ROC 值表示分類效能有所提升。*在 k = 16 時,「Bm」類別被移除;**在 NOAA PIPAN 資料中,k = 32 時,「Bm」和「Be」類別被移除。
我們還將 Perch 2.0 與 AVES-bird 和 AVES-bio(分別在鳥類和生物聲音上訓練的 Earth Species Project transformer 生物聲學模型)以及康乃爾大學鳥類學實驗室 K. Lisa Yang 保護生物聲學中心的 BirdNet v2.3 的嵌入進行了比較。Perch 2.0 在大多數水下任務上優於 AVES-bird 和 AVES-bio,但也有其他未經水下音訊訓練的預先訓練模型表現良好。
Perch 2.0 如何如此「鯨」準?
我們對這個主要訓練於鳥類的模型,在水下聲音上的遷移效能提出了一些可能的解釋。首先,先前的研究表明,擁有大量訓練資料的大型模型能更好地泛化,這使得我們的生物聲學模型即使在對訓練資料集中未包含的物種和聲音進行分類的下游任務上也能表現良好。此外,分類相似鳥類叫聲的挑戰(「鷓鴣的教訓」)迫使模型學習詳細的聲學特徵,這些特徵可能對其他生物聲學任務具有資訊性。例如,北美有 14 種鴿子,每種都有其細微不同的「咕咕」聲。一個能夠提取區分每種物種特有「咕咕」聲的特徵的模型,很可能會分離出有助於區分其他聲音類別的特徵。最後,不同物種之間的特徵遷移也可能與聲音產生機制本身有關,因為包括鳥類和海洋哺乳動物在內的各種物種,都演化出了相似的聲音產生方式。
一個高性能的模型將擁有對應用目標類別具有資訊性且線性可分的嵌入。為了視覺化,我們使用一種稱為 tSNE 的程序來繪製每個模型的嵌入摘要,其中不同的顏色代表不同的類別。一個資訊豐富的模型將顯示每個類別的獨立簇,而在一個資訊較少的模型(如 Google 多物種鯨魚模型)中,類別會更加混合。雖然幾乎所有模型都顯示出南方居民虎鯨(KW_SRKW)和南方阿拉斯加居民(KW_SAR)的一些獨立簇,但在 AVES-bio、AVES-bird 和 SurfPerch 等模型中,北方居民虎鯨(KW_NRKW)、遷徙虎鯨(KW_TKW)和遠洋虎鯨(KW_OKW)的聲音嵌入是混合的,但在 BirdNet v2.3 和 Perch 2.0 中則更清晰地區分。
每個模型在 DCLDE 2026 生態型資料集上的嵌入 tSNE 圖,該資料集包含虎鯨(orca)物種的五種生態型變體。圖表使用 sci-kit learn PCA 和 tSNE 函式庫生成,嵌入首先被投影到 32 維向量,然後應用 tSNE。
展望未來
Google DeepMind Perch 團隊與 Google Research 和外部合作夥伴合作,開創了一種敏捷的生物聲學建模方法,可以在幾個小時內從少量標記樣本建立自訂分類器。為了支持 Google Research 的合作夥伴以及更廣泛的鯨類聲學社群,我們創建了一個端對端的演示,用於處理託管於 Google Cloud 的被動聲學歸檔資料集中的 NOAA 資料,並更新了我們之前的教學,使用更高效的 Perch Hoplite 資料庫來管理嵌入。
致謝
Perch 團隊,開發了 Perch 2.0 模型並隸屬於 Google DeepMind,成員包括 Tom Denton、Bart van Merriënboer、Vincent Dumoulin、Jenny Hamer、Isabelle Simpson、Andrea Burns 和 Lauren Harrell(Google Research)。特別感謝 Ann Allen(NOAA 太平洋島嶼漁業中心)和 Megan Wood(Saltwater Inc.,為 NOAA 提供支援),他們提供了 NOAA PIPAN 資料集中使用的額外註釋,以及 Dan Morris(Google Research)和 Matt Harvey(Google DeepMind)。