Teaching AI to read a map
Google Research
Machine Perception
Google Research
Machine Perception
AI 生成摘要
我們提出了一套合成數據生成系統,用以訓練人工智慧系統視覺化地遵循任何地圖上的路線,最終教導語言模型在我們的世界中導航。
我們致力於營造一個有利於跨越不同時間尺度和風險水平、進行多種類型研究的環境。
我們的研究人員透過基礎研究與應用研究,推動電腦科學的進步。
我們定期與廣大的研究社群分享開源專案,並將研發成果應用於 Google 產品中。
發表作品讓我們能夠分享創意並協作,共同推動電腦科學領域的發展。
我們向所有人提供產品、工具和數據集,目標是建立一個更具協作性的生態系統。
透過廣泛的課程計畫支持下一代研究人員。
透過與大學教職員的深度參與,投入學術研究社群。
透過活動與更廣泛的研究社群建立聯繫,對於推動我們工作各方面的進展至關重要。

2026 年 2 月 17 日
Artemis Panagopoulou,學生研究員;Mohit Goyal,Google 資深軟體工程師
我們提出了一套合成數據生成系統,用於訓練 AI 系統在任何地圖上視覺化地遵循任何路線,最終教導語言模型在我們的世界中導航。
看看購物中心或主題樂園的地圖。在幾秒鐘內,你的大腦就能處理視覺資訊、識別你的位置,並描繪出前往目的地的最佳路徑。你本能地理解哪些線條是牆壁,哪些是走道。這種基本技能——精細的空間推理——是與生俱來的。
儘管多模態大型語言模型(MLLMs)取得了令人難以置信的進步,但它們往往在這一特定任務上感到吃力。雖然 MLLM 可以識別動物園的照片並列出你可能在那裡找到的動物,但它們可能難以描繪出一條從入口到爬蟲館的有效路徑。它們可能會直接穿過圍欄或禮品店畫出一條線,未能遵守環境的基本約束。這揭示了一個關鍵差距:當今的模型非常擅長識別圖像中的內容,但在需要理解物體之間的幾何和拓撲關係時卻顯得力不從心。
為了應對這一挑戰,在《MapTrace:地圖路線追蹤的可擴展數據生成》中,我們引入了一項新任務、數據集和合成數據生成流程,旨在教導 MLLM 在地圖上追蹤路徑的基本技能。我們的研究表明,這種在預訓練模型中很大程度上缺失的複雜空間能力,可以透過有針對性的合成生成數據進行明確教導。我們還開源了利用 Gemini 2.5 Pro 和 Imagen-4 模型透過該流程生成的 200 萬個問答對,以鼓勵研究社群進一步探索這一領域。
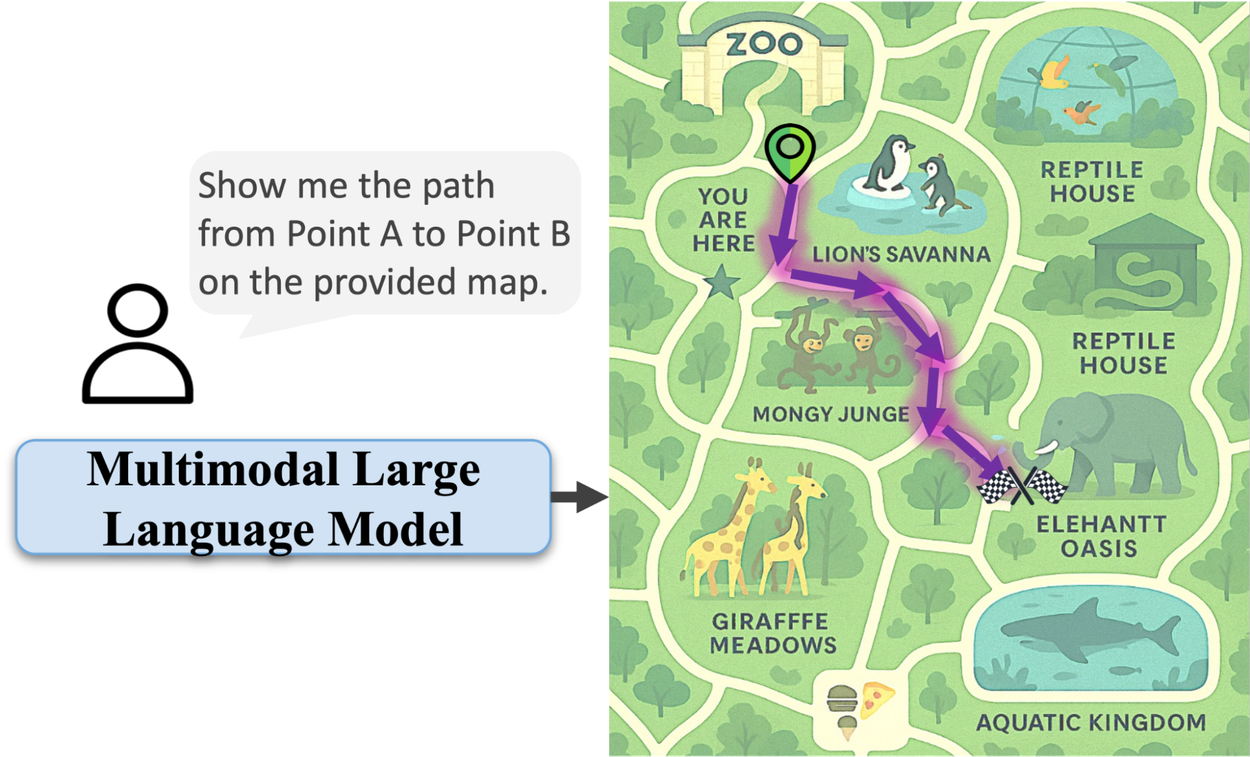
給定地圖上的起點和終點位置,模型會輸出符合地圖約束的有效路徑。我們觀察到生成的圖像往往會錯誤地呈現文字,但本研究主要關注路徑品質。我們相信隨著圖像生成模型的改進,這些瑕疵在未來的工作中可以輕易被消除。
為什麼在地圖上追蹤路徑對 AI 模型來說如此困難?這歸結為數據問題。MLLM 從龐大的圖像和文本數據集中學習。它們學會將「路徑」一詞與人行道和步道的圖像聯繫起來。然而,它們很少看到明確教導導航規則的數據——例如路徑具有連通性、不能穿牆而過,以及路線是連接點的有序列。
教導這一點最直接的方法是收集一個包含數百萬條手工描繪路徑的大型地圖數據集。但以像素級精度標註單條路徑是一個艱苦的過程,將其擴展到訓練大型模型所需的規模實際上是不可能的。此外,許多複雜地圖的最佳範例(如購物中心、博物館和主題樂園的地圖)都是私有的,無法輕易收集用於研究。
這種數據瓶頸阻礙了進展。沒有足夠的訓練範例,模型就缺乏解釋地圖的「空間語法」。它們看到的是像素的組合,而不是一個結構化的、可導航的空間。
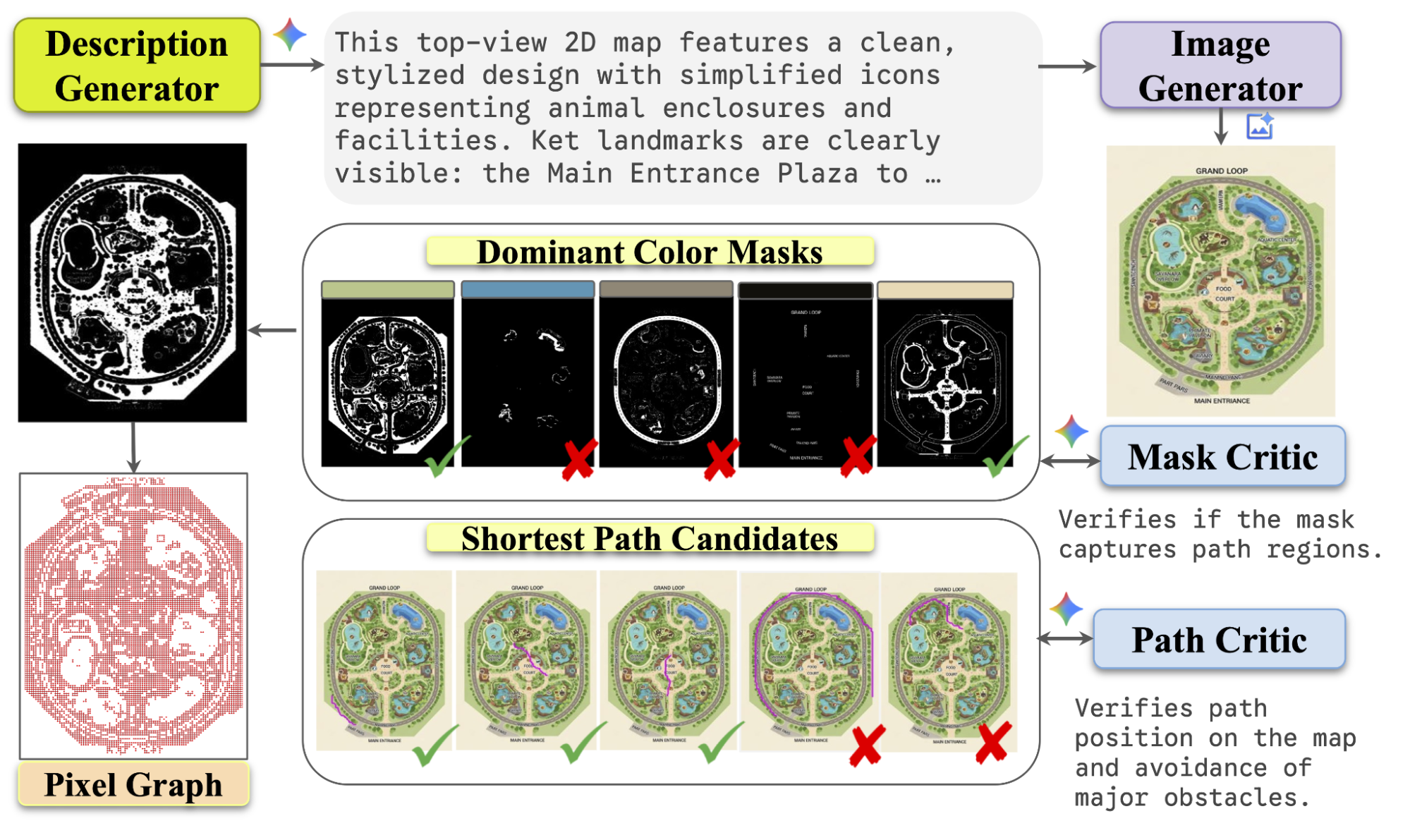
為了填補這一數據空白,我們設計了一個全自動、可擴展的流程,利用 Gemini 模型的生成能力來產出多樣化的高品質地圖。這個過程允許對數據的多樣性和複雜性進行精細控制,生成符合預期路線並避開不可通行區域的標註路徑,而無需收集大規模的現實世界地圖。
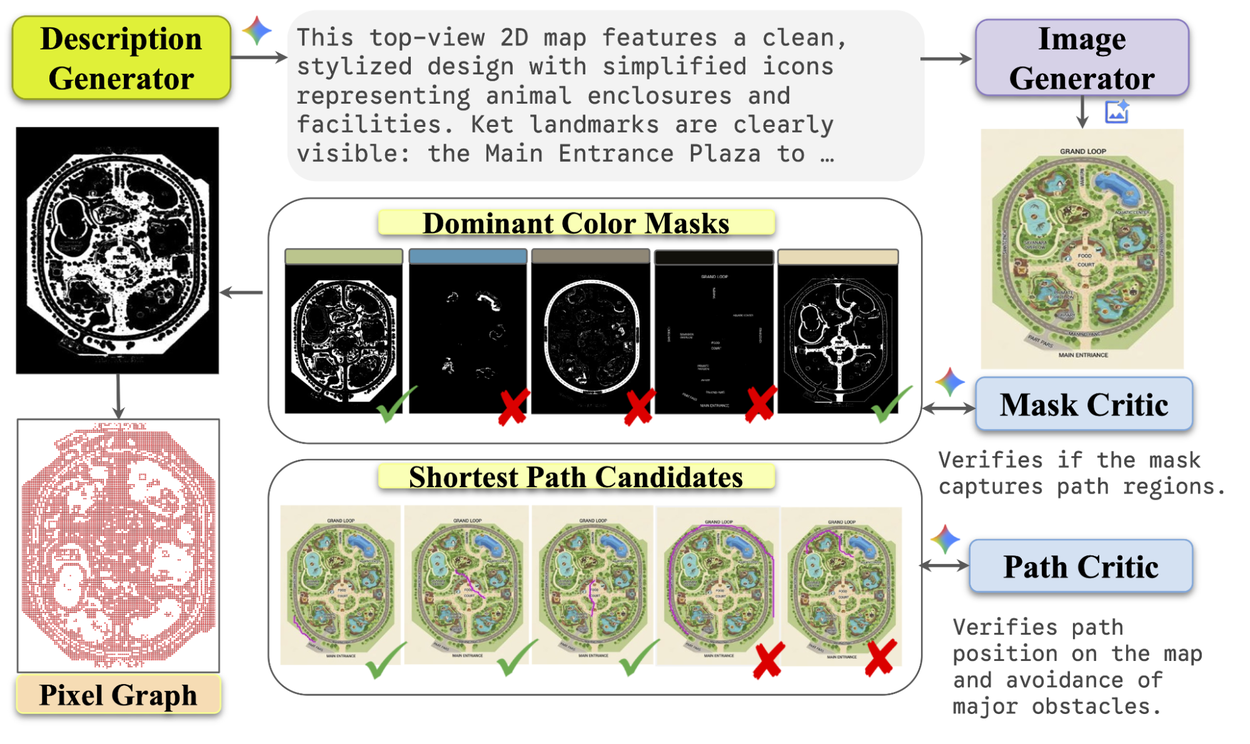
用於地圖路線追蹤數據的可擴展流程。
該流程分為四個自動化且可擴展的階段,使用 AI 模型同時擔任創作者和評論者,以確保品質並產出像素級標註。
首先,我們使用大型語言模型(LLM)為不同類型的地圖生成豐富且具描述性的提示詞(Prompts)。LLM 會生成從「具有互連棲息地的動物園地圖」到「帶有中央美食廣場的購物中心」或「擁有穿過不同主題區域蜿蜒路徑的奇幻主題樂園」等各種內容。這些文本提示隨後被輸入到文本轉圖像模型中,將其渲染成複雜的地圖圖像。
一旦我們有了地圖圖像,我們需要識別所有「可行走」的區域。我們的系統透過按顏色對像素進行聚類來創建候選路徑遮罩——本質上是所有走道的黑白地圖。
但並非每個陰影區域都是有效路徑。因此,我們聘請另一個 MLLM 作為「遮罩評論者(Mask Critic)」,透過同時觀察地圖圖像和候選遮罩,判斷每個候選遮罩是否代表一個現實且連通的路徑網絡。如果 MLLM 認定候選遮罩主要包含有效的可通行區域(例如:鋪設的人行道、標記的斑馬線、行人專用道),則將該候選標記為高品質。隨後只有這些高品質遮罩會進入下一階段。
有了乾淨的可通行區域遮罩後,我們將該 2D 圖像轉換為更具結構性的圖形格式。這可以想像成創建一個道路網絡的數位版本,其中路口是節點,之間的道路是邊。這種「像素圖(pixel-graph)」捕捉了地圖的連通性,使得計算路徑變得容易。
最後,我們在每張地圖的圖形上隨機採樣數千個起點和終點。我們使用經典的 Dijkstra 演算法來尋找這些點之間的絕對最短路徑。然後,我們使用另一個 MLLM 作為「路徑評論者(Path Critic)」進行最終的品質檢查。這位評論者會觀察疊加在地圖圖像上的最終生成路徑,並給予認可或否決,確保路線邏輯正確、保持在線條內,且看起來像人類會走的路徑。
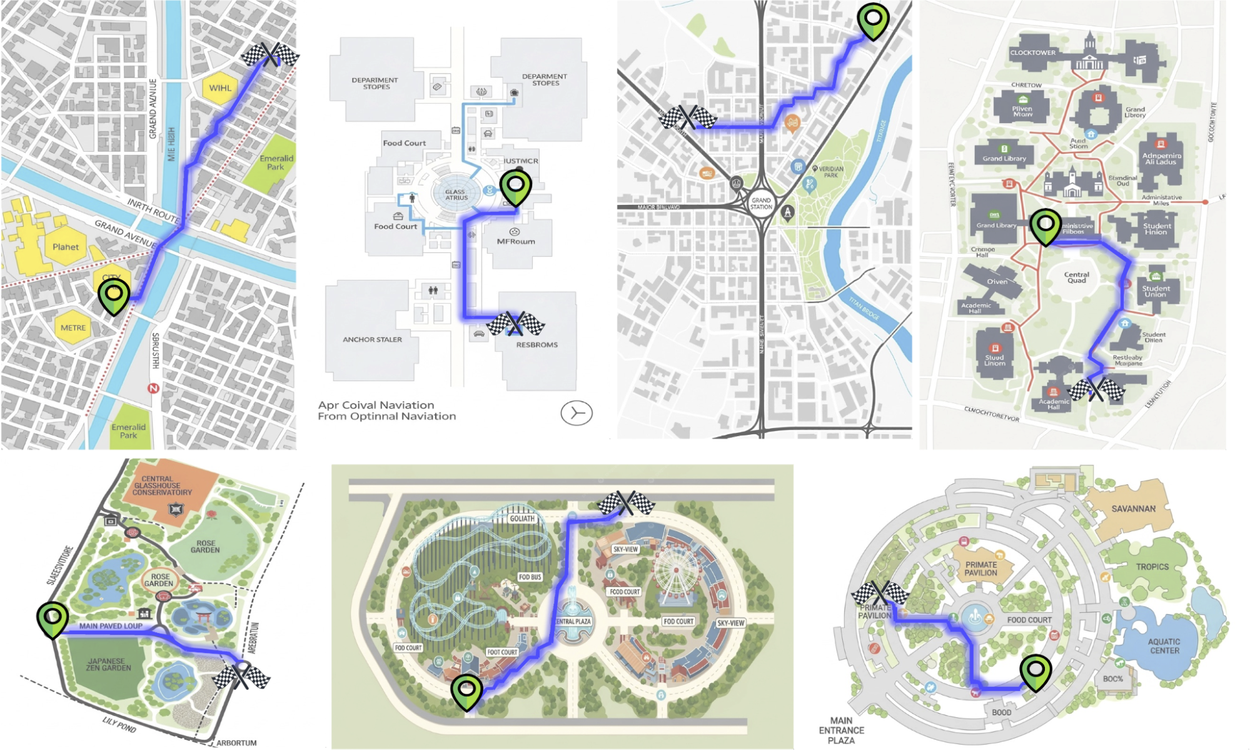
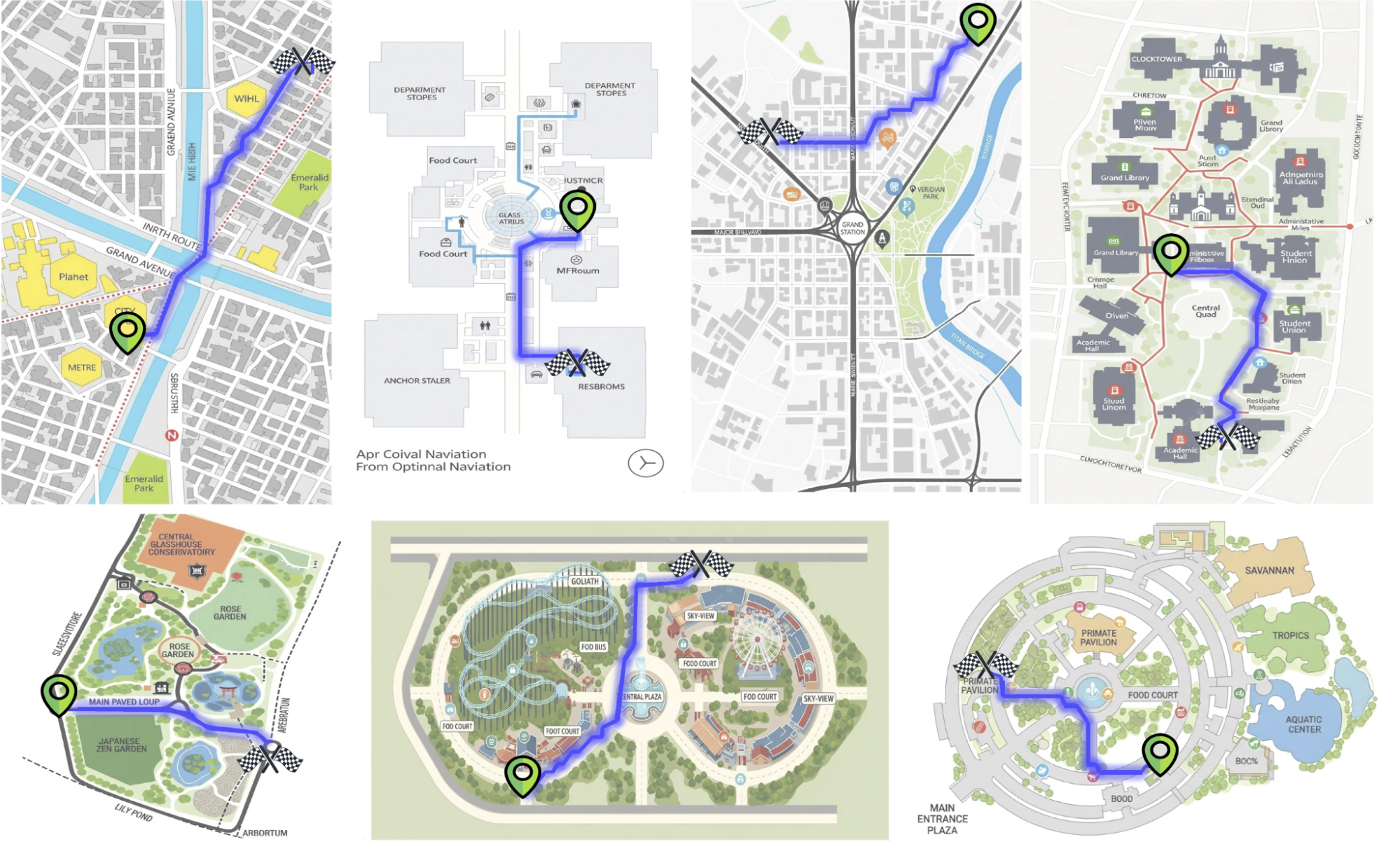
由提議流程生成的路徑範例。
這個流程使我們能夠創建一個包含 200 萬張帶有有效路徑標註的地圖圖像數據集。雖然生成的圖像偶爾會出現排版錯誤,但本研究主要關注路徑的準確性。我們預計生成式建模的持續進步將在未來的迭代中自然減輕這些瑕疵。
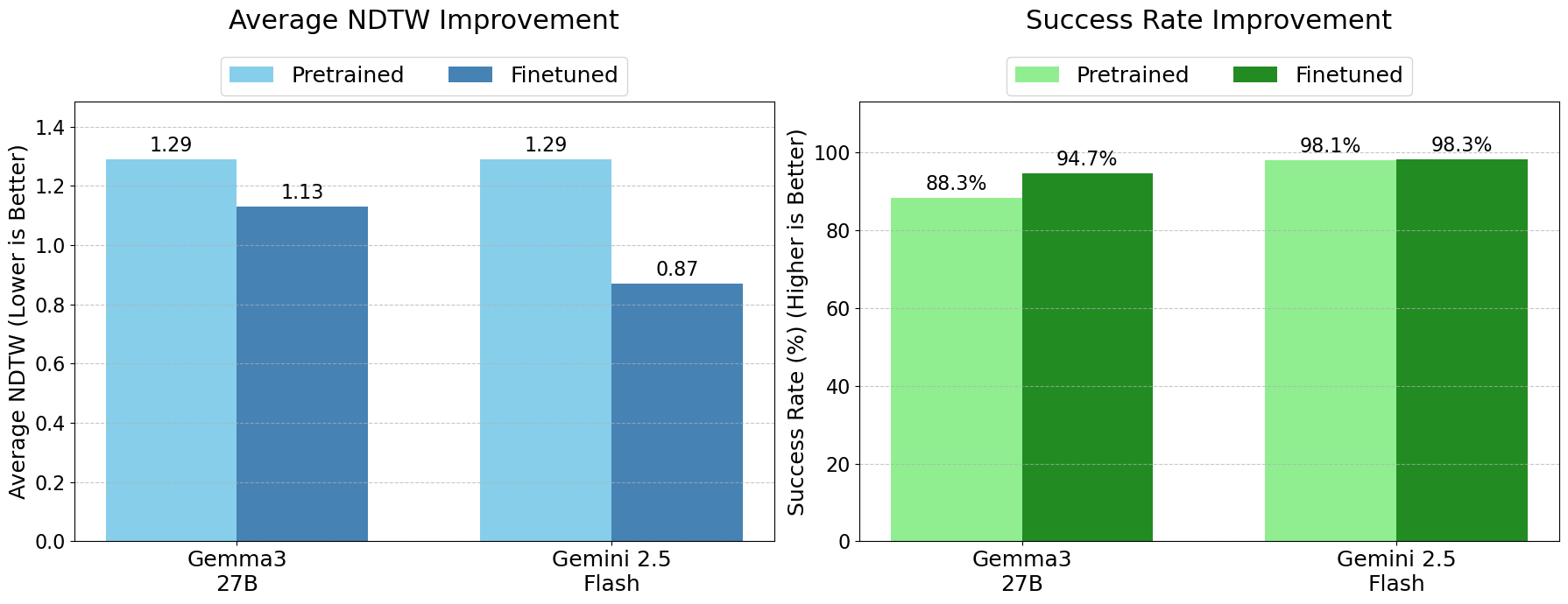
那麼,在這些合成數據上進行訓練真的有效嗎?為了找出答案,我們在從數據集中提取的較小數據子集(23,000 條路徑)上微調了幾個 MLLM,包括開源的 Gemma 3 27B 和 Gemini 2.5 Flash。然後,我們在 MapBench 上評估了它們的表現,這是一個由 MLLM 在訓練期間未見過的真實世界地圖組成的熱門基準測試。
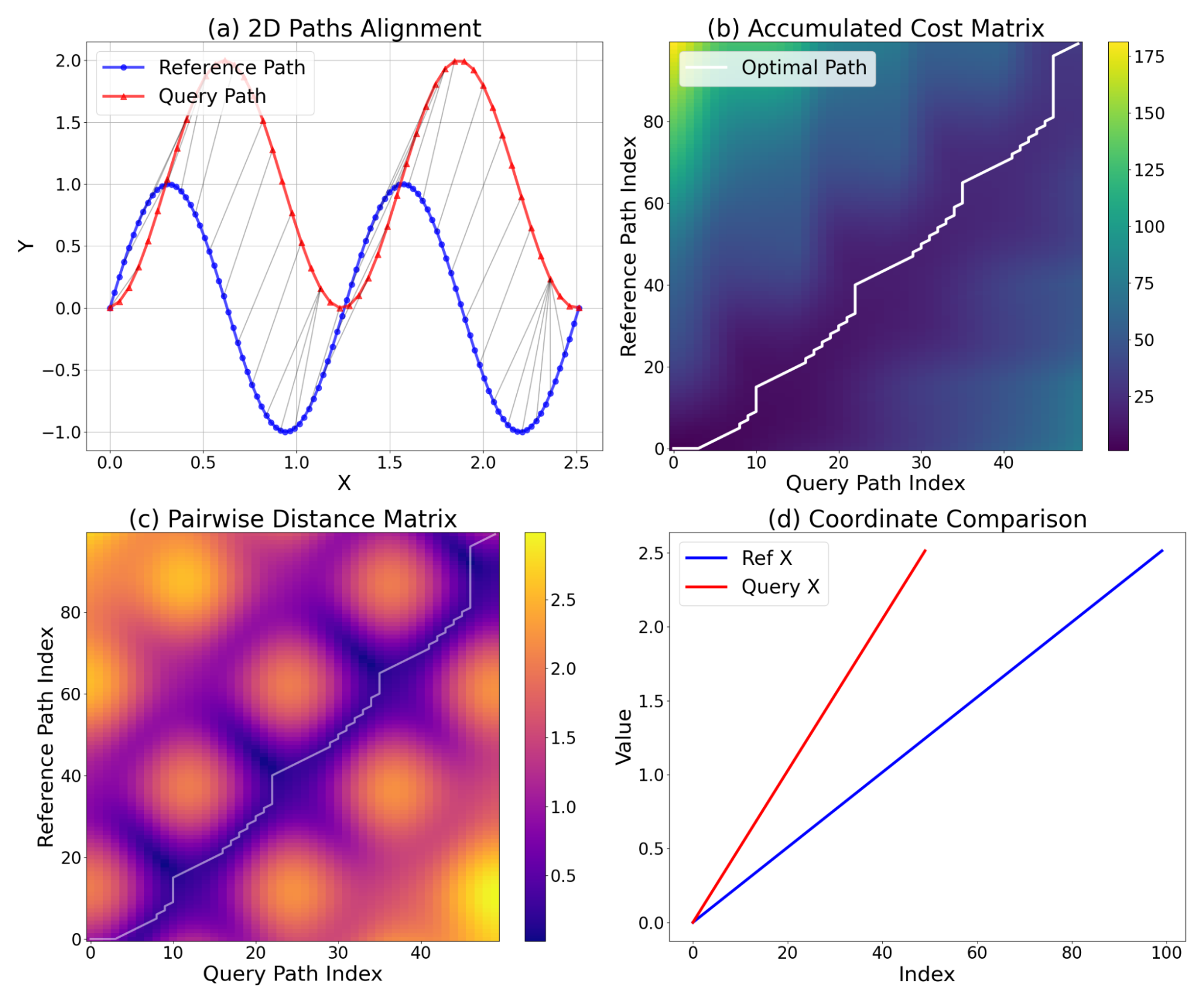
我們使用標準化動態時間規整(NDTW)指標來衡量模型的路徑追蹤誤差,這是動態時間規整的一種擴展,用於比較兩組速度可能不同(或在此情況下,預測點數量不同)的座標序列。輸出結果隨後根據總路徑長度進行標準化,得到最終的標準化指標,即兩條路徑之間的距離,數值越低代表表現越好。下圖顯示了 NDTW 指標的計算方式,詳細說明了對齊過程。圖 (a) 顯示了參考路徑(藍色)和查詢路徑(紅色,為視覺化平移了 Y=1.0)的 2D 對齊。灰色線連接了由 DTW 識別的匹配點,展示了對相位偏移和採樣差異的處理。圖 (b) 和 (c) 顯示了累積代價矩陣和成對歐幾里得距離矩陣,說明了最佳規整路徑(白色)如何追蹤距離最低的點對,以最小化總對齊代價。最後,圖 (d) 顯示了 x 座標的 1D 比較,突出了 DTW 解決的時間對齊問題:訊號具有相似的形狀,但採樣率和時間偏移不同。
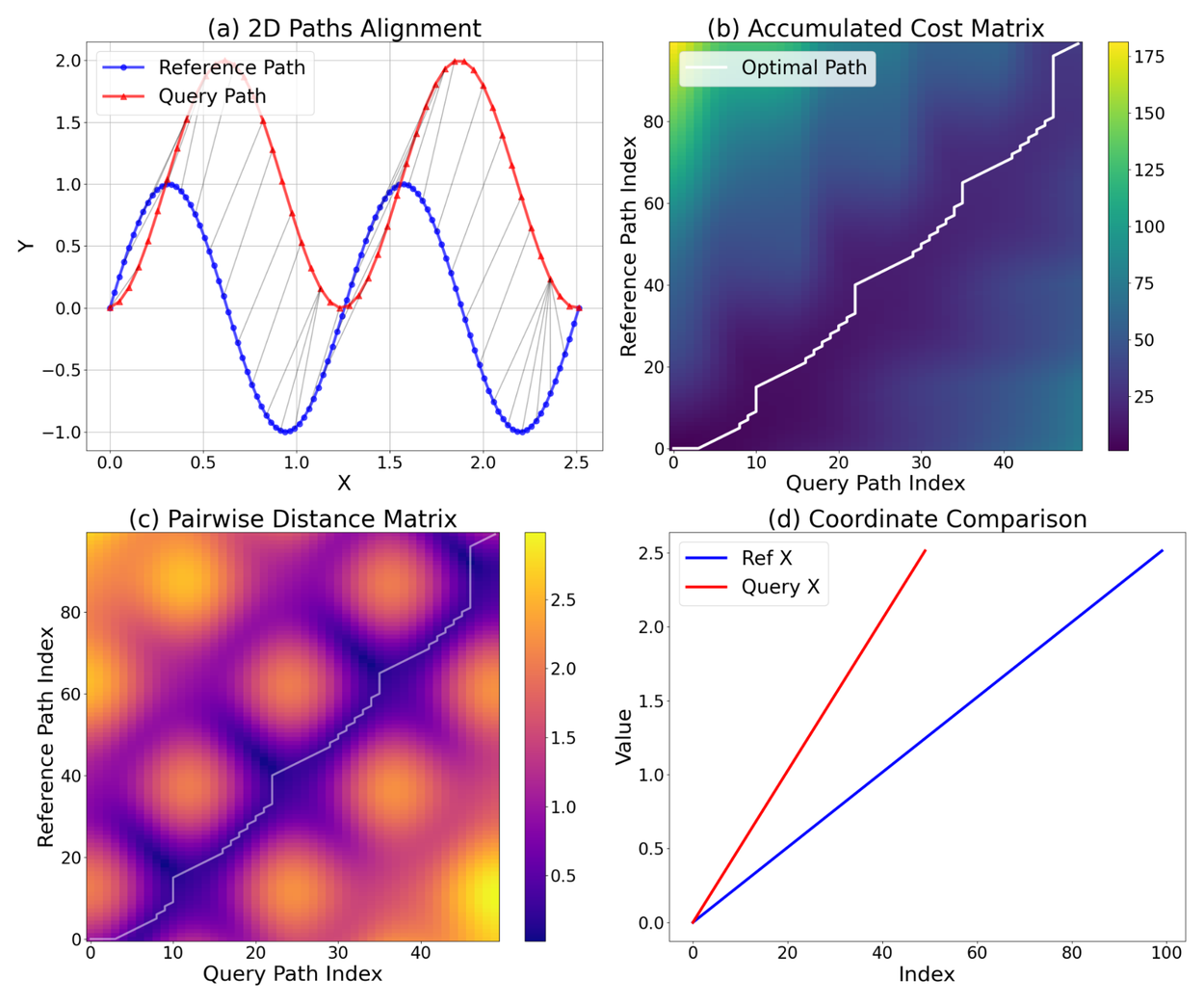
兩條 2D 路徑的動態時間規整 (DTW) 分析。
在我們的數據集上進行微調後,全面顯著提升了模型的能力。例如,微調後的 Gemini 2.5 Flash 模型的 NDTW 顯著下降(從 1.29 降至 0.87),實現了最佳的整體表現。
更重要的是,模型變得更加可靠。所有模型的成功率(即模型產生有效、可解析路徑的百分比)都有所提高。微調後的 Gemma 模型成功率提高了 6.4 個百分點,NDTW 也有所改善(1.29 降至 1.13),這一顯著進步展現了新的魯棒性。這意味著在我們的數據集上訓練後,模型不僅在成功時更準確,而且完全失敗的可能性也大大降低。
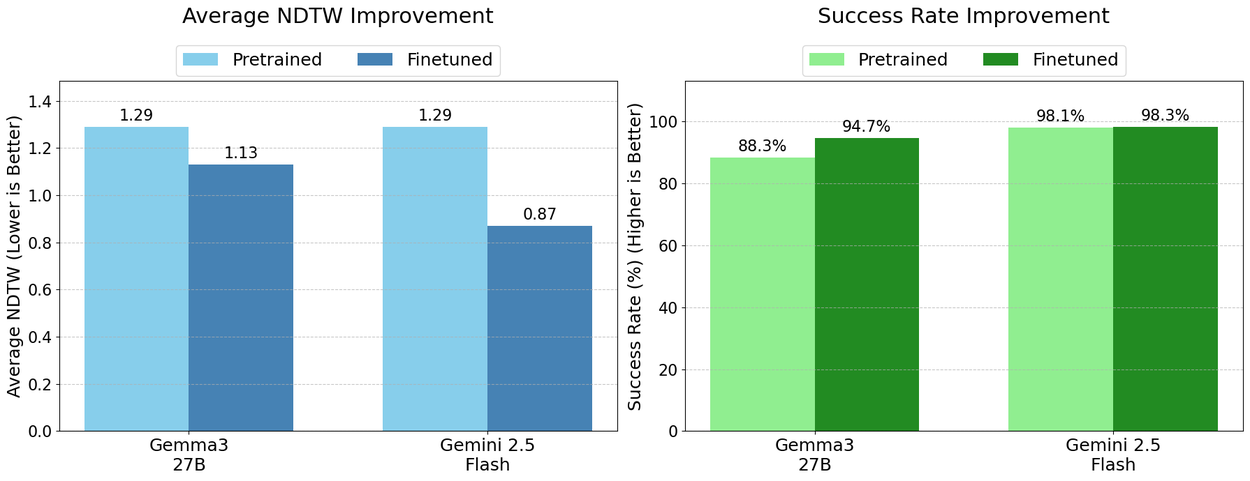
透過在生成的數據集上訓練,量化 MapBench 上的性能提升。我們報告了 NDTW 以及成功率(成功找到有效路徑)的顯著改善。
這些成果證實了我們的核心假設:精細的空間推理不是 MLLM 的先天屬性,而是一項習得的技能。透過正確類型的明確監督,即使是合成生成的,我們也可以教導模型理解並導航空間佈局。
對於「路徑評論者」,我們手動審查了 56 張隨機採樣地圖中的 120 個決策,達到了 76% 的準確率和 8% 的誤報率(將無效路徑標記為「高品質」)。錯誤主要源於:1) 當顏色與路徑相似時,將背景區域誤分類為可通行區域;2) 遺漏了較大開放區域內的細長有效路徑。對於「遮罩評論者」,我們檢查了 20 張地圖上的 200 個判斷,觀察到 83% 的準確率和 9% 的誤報率。常見錯誤包括:1) 由於顏色相似而包含背景像素;2) 小型的非路徑元素(如文字)被吸收到原本正確的遮罩中;3) 細長的有效路徑被標記為無效。
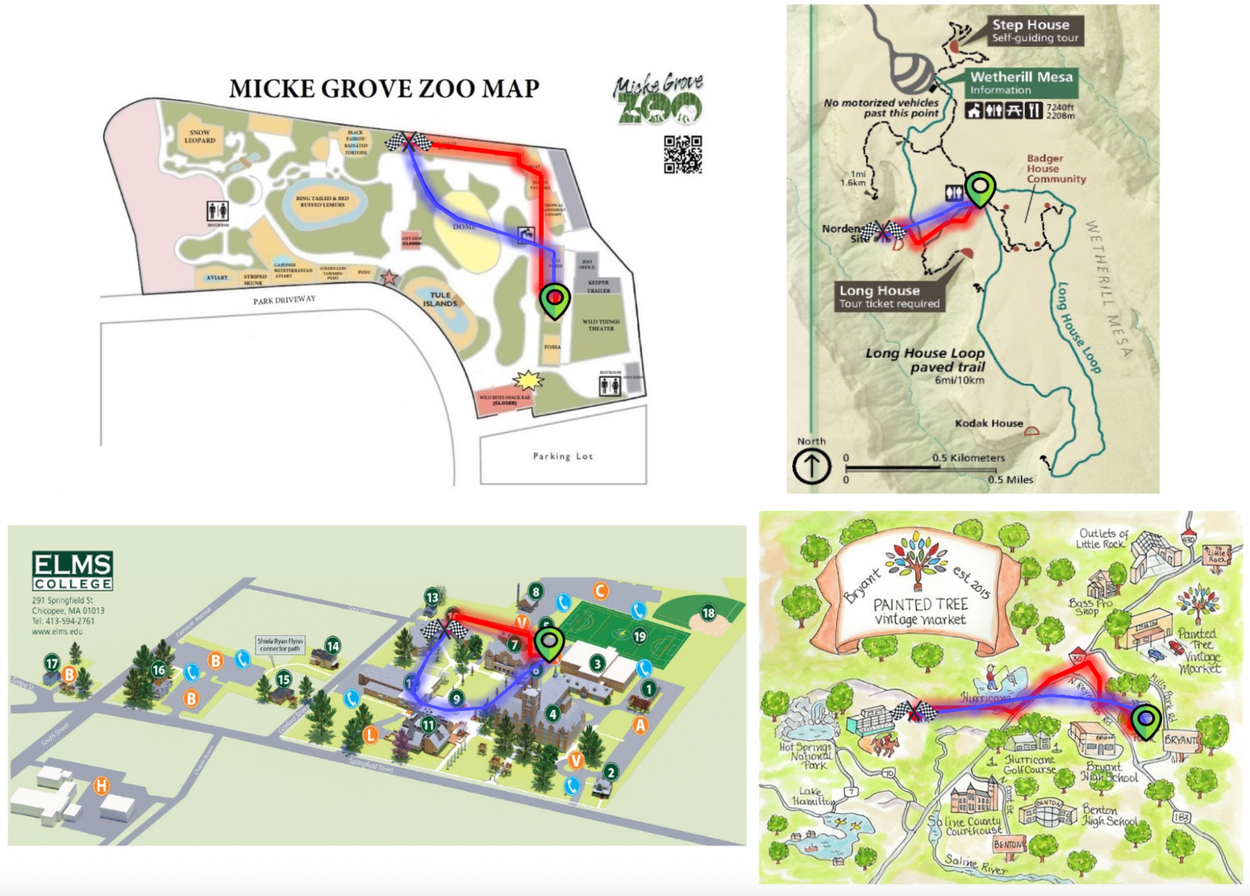
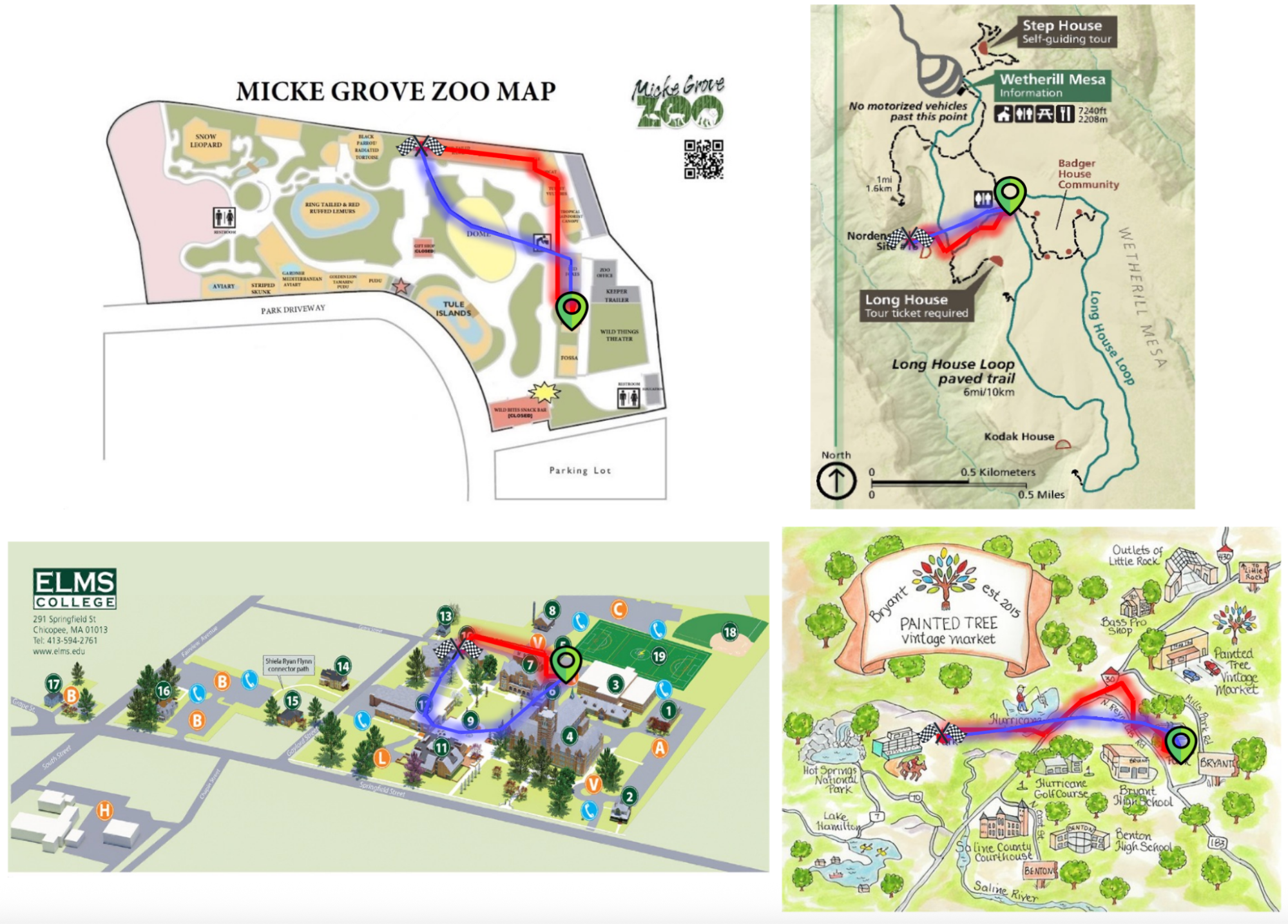
微調後的 Gemini-2.5-Flash(紅色)與基礎模型(藍色)的定性範例比較。微調後的模型更緊密地遵循預期路線並避開不可通行區域。
對路徑和連通性進行推理的能力開啟了許多未來的應用,包括:
本研究由 Artemis Panagopoulou(在 Google 擔任學生研究員期間)、Mohit Goyal、Soroosh Yazdani、Florian Dubost、Chen Chai、Achin Kulshrestha 和 Aveek Purohit 共同完成。

2026 年 2 月 9 日

2026 年 1 月 22 日
2026 年 1 月 12 日
關注我們