新數據顯示 NVIDIA Blackwell Ultra 為 Agentic AI 提供高達 50 倍的效能提升和 35 倍的成本降低 | NVIDIA 部落格
NVIDIA 的人工智慧運算領導地位

新數據顯示 NVIDIA Blackwell Ultra 為 Agentic AI 提供高達 50 倍的效能提升和 35 倍的成本降低

NVIDIA Blackwell 平台已被 Baseten、DeepInfra、Fireworks AI 和 Together AI 等領先的推論供應商廣泛採用,以降低每個 token 的成本高達 10 倍。現在,NVIDIA Blackwell Ultra 平台正在進一步推動 Agentic AI 的發展。
根據 OpenRouter 的 State of Inference 報告,AI 代理和程式碼編寫助手正在推動軟體程式設計相關 AI 查詢的爆炸性增長:從去年的 11% 增長到約 50%。這些應用程式需要低延遲,以在多步驟工作流程中保持即時回應能力,並在整個程式碼庫中進行推理時需要長上下文。
新的效能數據顯示,NVIDIA 的軟體優化和下一代 NVIDIA Blackwell Ultra 平台的結合,在這兩個方面都取得了突破性的進展。與 NVIDIA Hopper 平台相比,NVIDIA GB300 NVL72 系統現在每兆瓦提供高達 50 倍的更高吞吐量,從而使每個 token 的成本降低 35 倍。
透過在晶片、系統架構和軟體方面的創新,NVIDIA 的極端協同設計加速了 AI 工作負載的效能,從 Agentic 程式碼編寫到互動式程式碼編寫助手,同時大規模降低了成本。
GB300 NVL72 為低延遲工作負載提供高達 50 倍的效能提升
Signal65 的最新分析顯示,NVIDIA GB200 NVL72 透過極端的硬體和軟體協同設計,每瓦提供超過 10 倍的 token,與 NVIDIA Hopper 平台相比,每個 token 的成本降低了十分之一。隨著底層堆疊的改進,這些巨大的效能提升將繼續擴大。
NVIDIA TensorRT-LLM、NVIDIA Dynamo、Mooncake 和 SGLang 團隊的持續優化,繼續顯著提高 Blackwell NVL72 在所有延遲目標下的混合專家 (MoE) 推論吞吐量。例如,與四個月前相比,NVIDIA TensorRT-LLM 函式庫的改進使 GB200 在低延遲工作負載上的效能提高了高達 5 倍。
在這些軟體進展的基礎上,採用 Blackwell Ultra GPU 的 GB300 NVL72 將每兆瓦吞吐量的極限推高到 Hopper 平台的 50 倍。
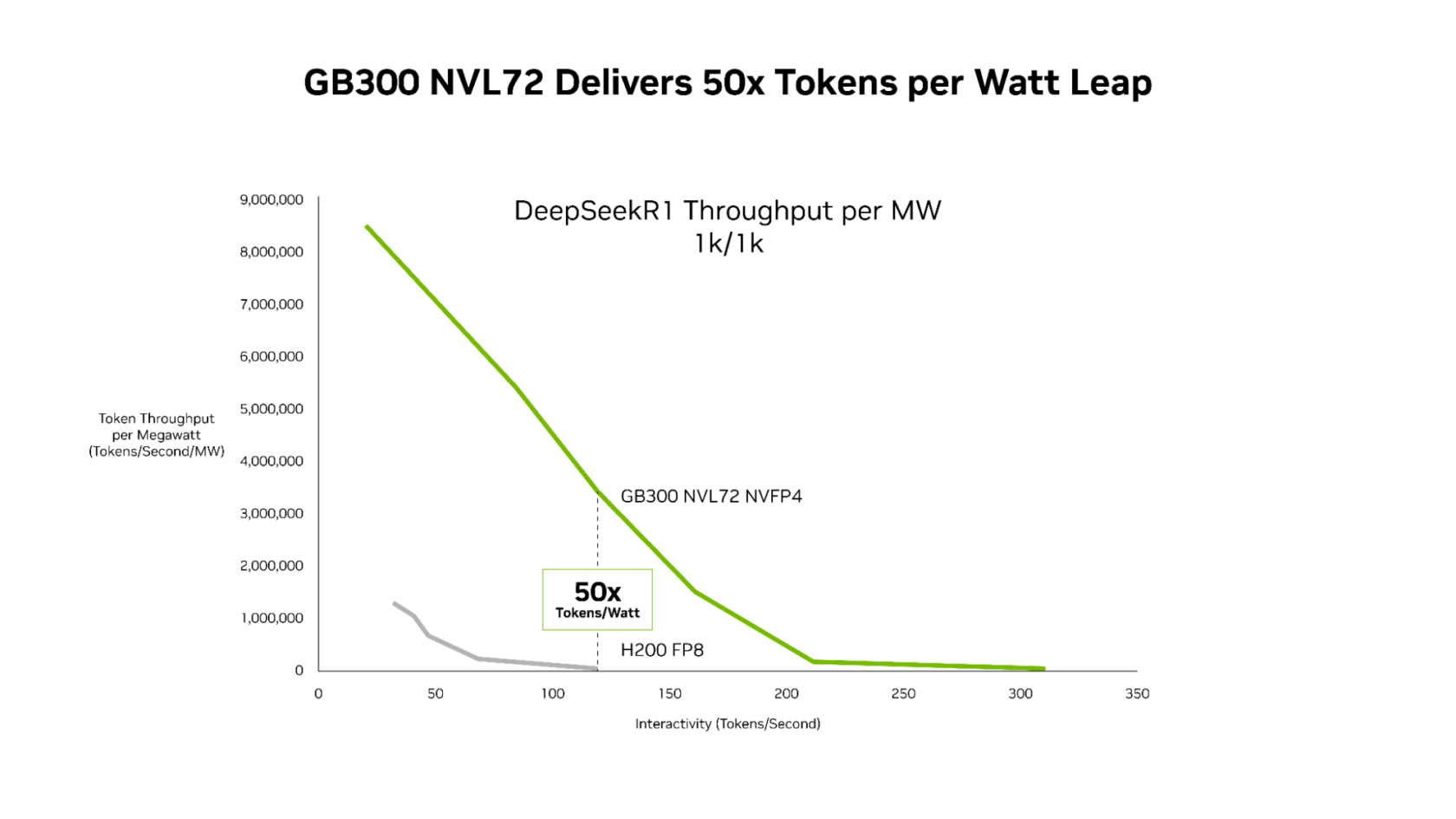
這種效能提升轉化為卓越的經濟效益,與 Hopper 平台相比,NVIDIA GB300 降低了整個延遲範圍內的成本。最顯著的降低發生在 Agentic 應用程式運作的低延遲情況下:與 Hopper 平台相比,每百萬個 token 的成本降低了高達 35 倍。
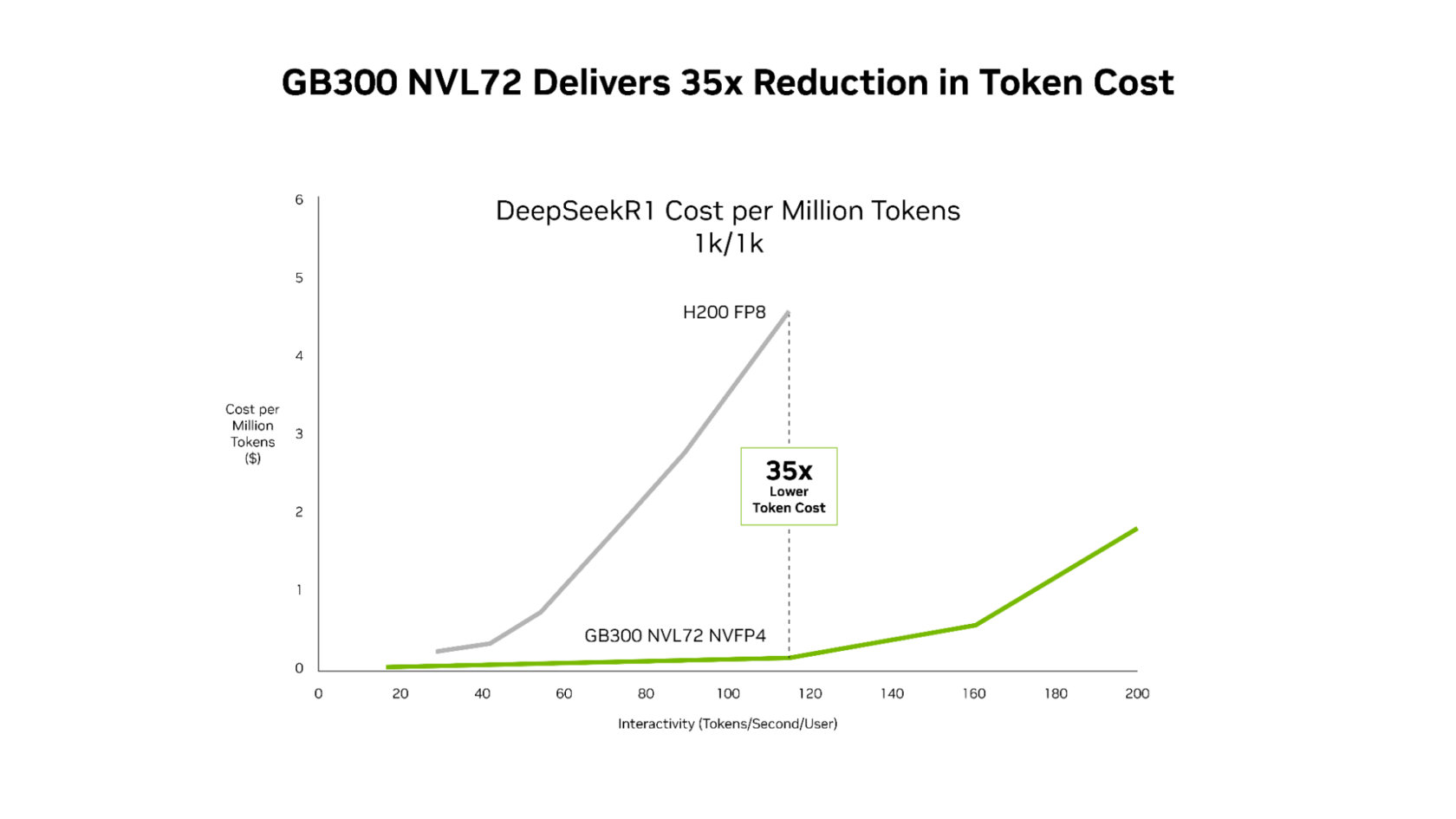
對於 Agentic 程式碼編寫和互動式助手工作負載,每一毫秒都會在多步驟工作流程中累積,這種無情的軟體優化和下一代硬體的結合使 AI 平台能夠將即時互動體驗擴展到更多的使用者。
GB300 NVL72 為長上下文工作負載提供卓越的經濟效益
雖然 GB200 NVL72 和 GB300 NVL72 都能有效地提供超低延遲,但 GB300 NVL72 的獨特優勢在長上下文場景中變得最為明顯。對於具有 128,000 個 token 輸入和 8,000 個 token 輸出的工作負載(例如在程式碼庫中進行推理的 AI 程式碼編寫助手),與 GB200 NVL72 相比,GB300 NVL72 的每個 token 成本降低了高達 1.5 倍。
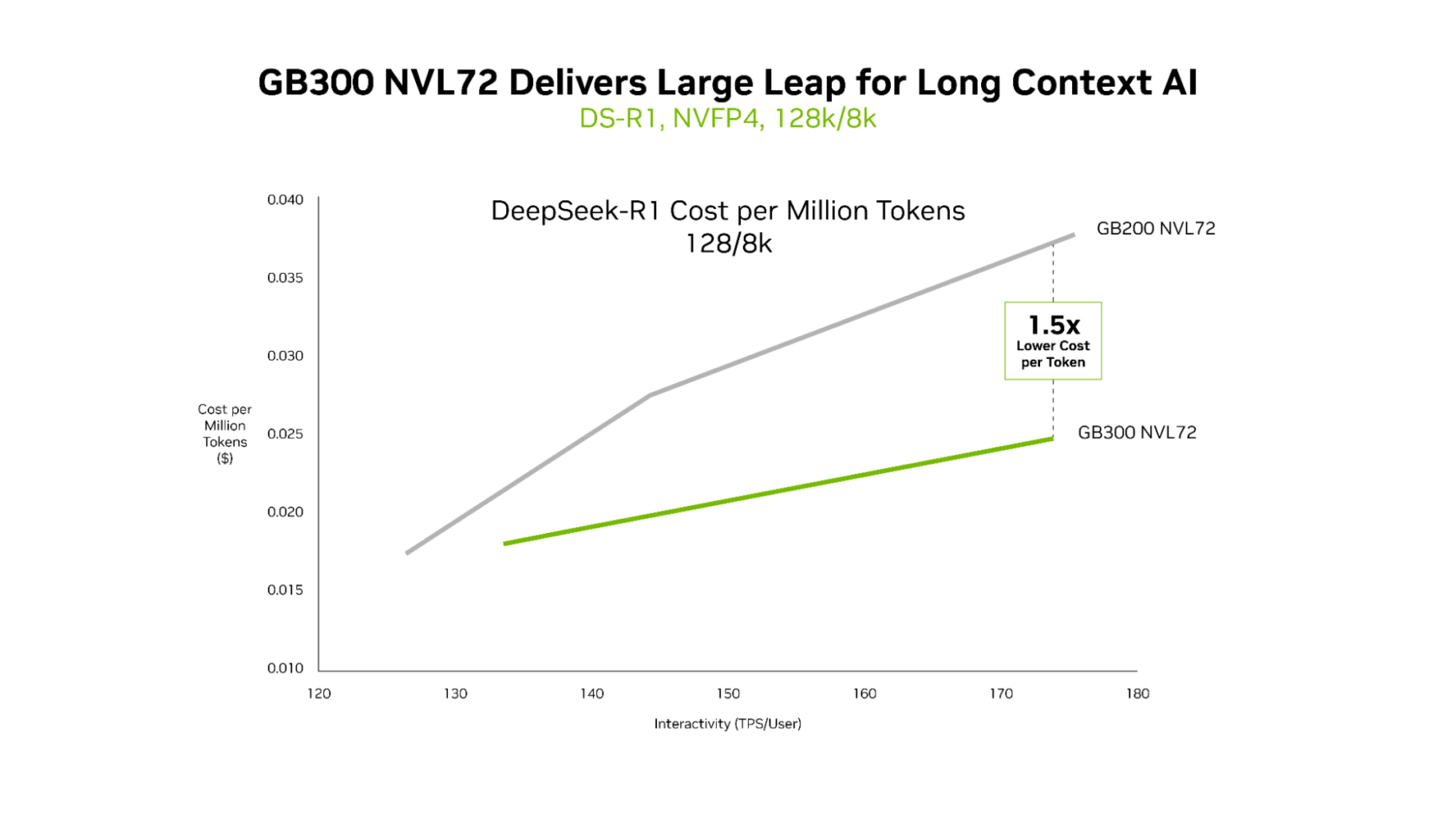
隨著代理讀取更多程式碼,上下文會不斷增長。這使其能夠更好地理解程式碼庫,但也需要更多的計算。Blackwell Ultra 具有 1.5 倍更高的 NVFP4 計算效能和 2 倍更快的注意力處理速度,使代理能夠有效地理解整個程式碼庫。
Agentic AI 的基礎設施
領先的雲端供應商和 AI 創新者已經大規模部署了 NVIDIA GB200 NVL72,並且也在生產環境中部署 GB300 NVL72。Microsoft、CoreWeave 和 OCI 正在部署 GB300 NVL72,用於低延遲和長上下文的使用案例,例如 Agentic 程式碼編寫和程式碼編寫助手。透過降低 token 成本,GB300 NVL72 支援一類新的應用程式,這些應用程式可以即時地在龐大的程式碼庫中進行推理。
CoreWeave 工程資深副總裁 Chen Goldberg 表示:「隨著推論轉向 AI 生產的中心,長上下文效能和 token 效率變得至關重要。Grace Blackwell NVL72 直接解決了這一挑戰,CoreWeave 的 AI 雲端(包括 CKS 和 SUNK)旨在將 GB300 系統的優勢(建立在 GB200 的成功基礎上)轉化為可預測的效能和成本效率。其結果是更好的 token 經濟效益和更易於使用的推論,供客戶大規模執行工作負載。」
NVIDIA Vera Rubin NVL72 將帶來下一代效能
隨著 NVIDIA Blackwell 系統的大規模部署,持續的軟體優化將不斷釋放已安裝基礎架構的額外效能和成本改進。
展望未來,NVIDIA Rubin 平台(它結合了六個新晶片來創建一台 AI 超級電腦)將帶來另一輪巨大的效能飛躍。對於 MoE 推論,與 Blackwell 相比,它每兆瓦提供高達 10 倍的更高吞吐量,從而使每百萬個 token 的成本降低了十分之一。對於下一波前沿 AI 模型,與 Blackwell 相比,Rubin 可以僅使用四分之一的 GPU 數量來訓練大型 MoE 模型。
了解更多關於 NVIDIA Rubin 平台和 Vera Rubin NVL72 系統的資訊。

所有 NVIDIA 新聞
程式碼、運算和連結:深入了解首屆 NVIDIA AI Day 聖保羅

領先的推論供應商透過 NVIDIA Blackwell 上的開源模型將 AI 成本降低高達 10 倍

NVIDIA DGX Spark 為高等教育中的大型專案提供支援

GeForce NOW 將螢幕變成遊戲機

GeForce NOW 慶祝串流六年,二月份推出 24 款遊戲
公司資訊
參與其中
新聞與活動
在 Mastodon 上分享
朋友的電子郵件地址
您的姓名
您的電子郵件地址
評論
發送電子郵件