教導大型語言模型(LLM)像貝氏主義者一樣推理

教導大型語言模型(LLM)像貝氏主義者一樣推理
2026 年 3 月 4 日
Sjoerd van Steenkiste 與 Tal Linzen,Google Research 研究科學家
我們透過訓練大型語言模型(LLM)模仿最佳貝氏模型(Optimal Bayesian Model)的預測,教導它們以貝氏方式進行推理。
快速連結
基於大型語言模型(LLM)的 AI 系統正日益被用作與用戶及世界互動的代理人(Agents)。為了成功實現這一點,LLM 需要構建世界的內部表徵,並估計這些表徵中每一項準確的機率。以個人化推薦為例:LLM 需要在多次互動的過程中,從用戶的選擇中逐漸推斷出其偏好。
貝氏推論(Bayesian inference)定義了執行此類更新的最佳方式。透過實施這種策略,LLM 可以在有關用戶的新資訊到達時,更新對用戶偏好的估計,從而優化用戶互動。但如果沒有經過特定訓練,LLM 通常會預設使用簡單的啟發式方法(例如假設每個人都想要最便宜的選項),而不是推斷特定用戶的獨特偏好。
在《貝氏教學使大型語言模型具備機率推理能力》(Bayesian teaching enables probabilistic reasoning in large language models)一文中,我們透過訓練 LLM 模仿貝氏模型的預測來教導它們以貝氏方式推理,該模型定義了機率推理的最佳方式。我們發現,這種方法不僅顯著提高了 LLM 在其受訓的特定推薦任務上的表現,還使其能夠推廣到其他任務。這表明該方法教會了 LLM 更好地逼近貝氏推理。更廣泛地說,我們的結果表明 LLM 可以有效地從範例中學習推理技能,並將這些技能推廣到新的領域。
評估 LLM 的貝氏能力
與人類一樣,為了發揮效用,LLM 與用戶的互動需要根據每次新互動,持續更新其對用戶偏好的機率估計。在這裡我們提出疑問:LLM 的行為是否表現得像是擁有了能根據最佳貝氏推論預期進行更新的機率估計?在 LLM 的行為偏離最佳貝氏策略的範圍內,我們該如何最小化這些偏差?
為了測試這一點,我們使用了一個簡化的航班推薦任務,其中 LLM 作為助手與模擬用戶進行五輪互動。在每一輪中,用戶和助手都會看到三個航班選項。每個航班由出發時間、飛行時長、停靠次數和價格定義。每個模擬用戶都有其偏好特徵:對於每個特徵,他們可能對高值或低值有強烈或微弱的偏好(例如,他們可能偏好較長或較短的航班),或者對該特徵沒有偏好。
我們將 LLM 的行為與遵循最佳貝氏策略的模型(貝氏助手)進行了比較。該模型維持一個反映其對用戶偏好估計的機率分佈,並在有關用戶選擇的新資訊出現時,使用貝氏法則更新此分佈。與許多難以在計算上指定和實施貝氏策略的現實場景不同,在這種受控環境中,貝氏策略很容易實施,並允許我們精確估計 LLM 偏離該策略的程度。
助手的目標是推薦符合用戶選擇的航班。在每一輪結束時,用戶會向助手指示其選擇是否正確,並提供正確答案。
貝氏助手如何根據每一輪後獲得的觀察證據(即用戶選擇)更新其對用戶偏好航班的估計。至關重要的是,助手無法直接獲取用戶的偏好,這使得這成為一項具有挑戰性的機率推理任務。
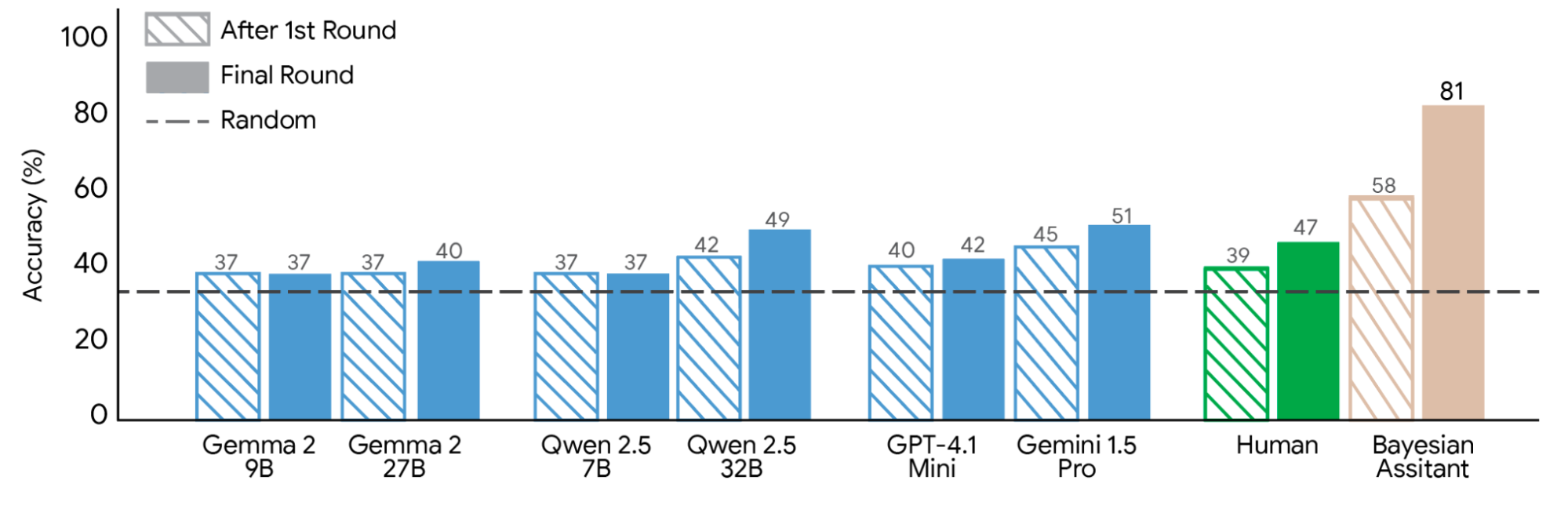
我們評估了一系列 LLM,發現它們的表現都明顯遜於最佳貝氏助手。最重要的是,與貝氏助手在收到有關用戶選擇的額外資訊後逐漸改進其推薦不同,LLM 的表現通常在單次互動後就陷入瓶頸,這表明其適應新資訊的能力有限,並且在與用戶的多次互動中表現出極少或沒有改進。
我們將來自不同模型系列的現成 LLM 與人類參與者及貝氏助手進行了比較。LLM 的表現明顯遜於貝氏助手。人類參與者在獲得更多資訊後表現出比大多數 LLM 更大的進步,但仍未達到最佳貝氏策略所具備的準確度。
我們比較了貝氏助手與人類及各種現成 LLM 在與 624 名用戶進行三組互動的第一輪和最後一輪後的推薦準確度。
貝氏教學框架
在貝氏框架中,代理人維持對世界狀態的先驗信念(Prior belief)。對於 LLM 而言,這種「世界狀態」是其對事實、關係和概念的內部表徵。當模型遇到新資訊(證據)時,它需要將其先驗信念(或稱「先驗」,即在看到新證據之前對某事物的初始猜測或機率)轉換為「後驗信念」(Posterior belief,即納入新數據後更新的機率),後者將作為下一條證據的全新先驗。這種循環過程使代理人能夠不斷完善其對世界的理解。
挑戰在於教導模型如何執行這些機率更新。我們透過監督式微調(Supervised fine-tuning)來實現這一點,讓模型根據其觀察到的大量與用戶互動的案例來更新其參數。
我們探索了兩種策略來創建監督式微調數據。在第一種策略中,我們稱之為「先知教學」(Oracle teaching),我們向 LLM 提供模擬用戶與「先知」助手之間的互動,該助手對用戶偏好擁有完美知識,因此始終推薦與用戶選擇完全相同的選項。
第二種策略,我們稱之為「貝氏教學」(Bayesian teaching),向 LLM 提供貝氏助手與用戶之間的互動。在這種情況下,助手經常會選擇與用戶偏好不符的航班,特別是在對用戶偏好存在很大不確定性的早期輪次中。我們假設,模仿貝氏助手的最佳猜測將教導 LLM 維持不確定性並比先知教學更有效地更新其信念,因為在先知教學中,LLM 是基於正確選擇進行訓練的。這種方法可以被視為一種蒸餾(Distillation)形式,即透過學習模仿另一個系統來訓練模型。
結果
監督式微調教導 LLM 逼近機率推論。我們檢查了不同助手在第一輪和最後(第五)輪後的準確度。我們比較了原始 LLM、在貝氏助手與用戶互動數據上微調的 LLM,以及在先知(始終提供正確答案)與用戶互動數據上微調的 LLM。兩種類型的微調都顯著提高了 LLM 的表現,且貝氏教學始終比先知教學更有效。
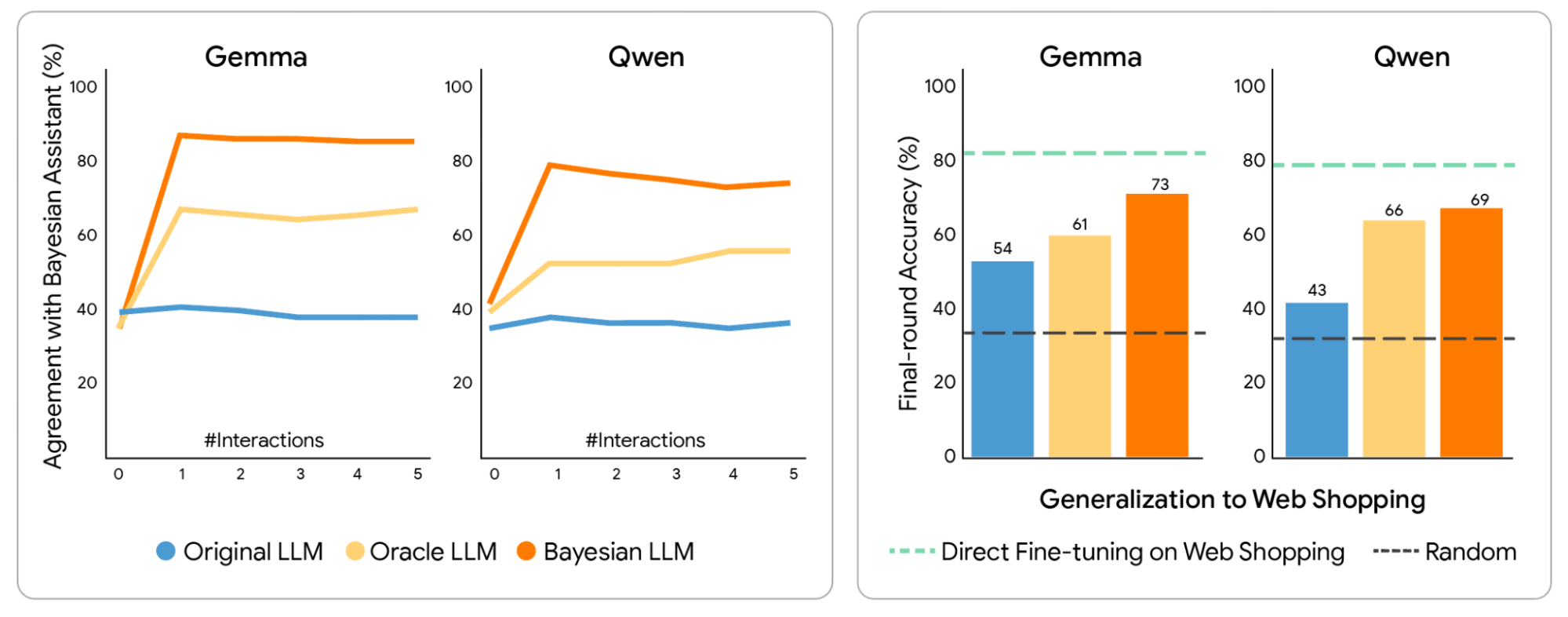
使用貝氏教學微調的 LLM 與貝氏助手的一致性更高,並能推廣到微調任務之外。我們展示了 LLM 與貝氏助手之間的一致性,這是透過 LLM 做出與貝氏助手相同預測的試驗比例來衡量的。在貝氏助手的預測上進行微調使 LLM 變得更具貝氏色彩,每個 LLM 的貝氏版本都與貝氏助手達成最高的一致性。我們還查看了 LLM 在網路購物領域的最終輪準確度,該領域在微調期間是未見過的。下圖中的綠色虛線表示 LLM 直接在網路購物數據上微調時的表現(此時不需要領域遷移,但此類數據可能更難獲得)。
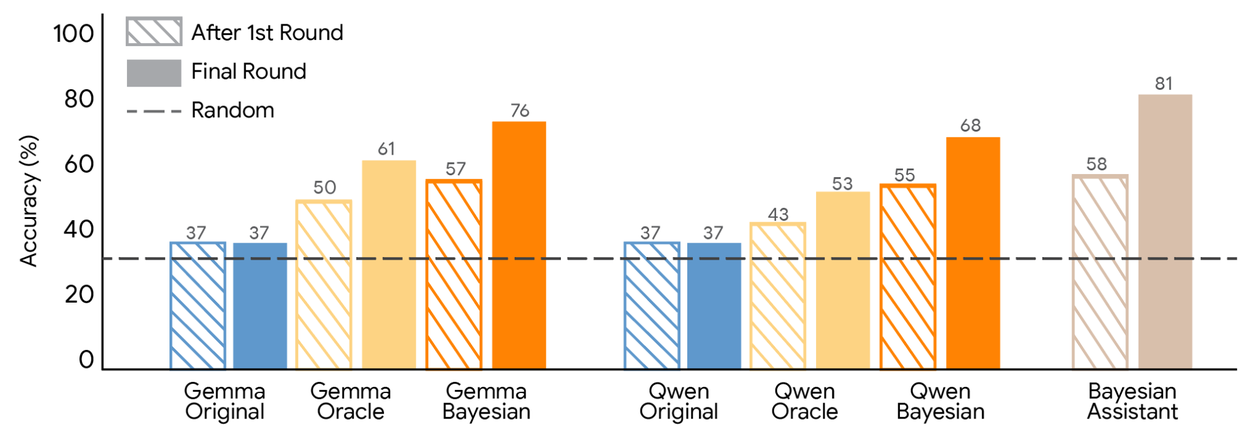
Gemma 和 Qwen 在貝氏助手或先知互動數據上微調後的推薦準確度。
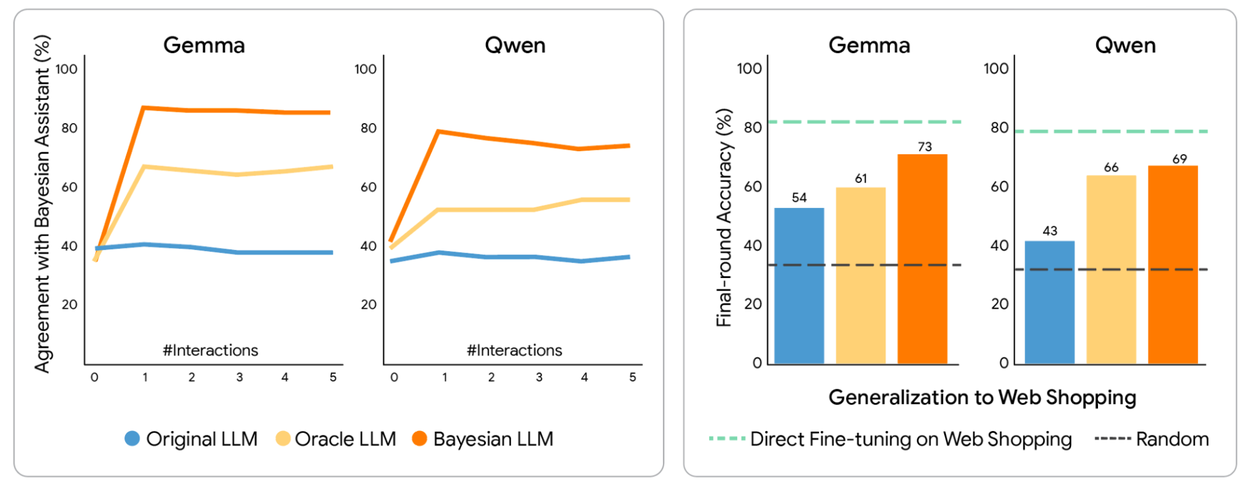
LLM 與貝氏助手做出相同預測的試驗比例(左),以及在訓練中未見過的網路購物領域的推薦準確度(右)。
貝氏教學顯著優於先知教學,使模型在 80% 的時間內能與數學理想值保持一致。這些經過微調的模型對資訊產生了現實的敏感性,學會在特定用戶選擇揭示出更清晰的偏好時,賦予這些選擇更大的權重。
至關重要的是,這些新獲得的技能並非特定於任務。在合成航班數據上訓練的模型成功地將其「機率邏輯」轉移到完全不同的領域,如酒店推薦和真實世界的網路購物。這表明 LLM 可以內化貝氏推論的核心原則,從靜態的模式匹配器轉變為具備跨領域推理能力的自適應代理人。
貝氏教學的下一步是什麼?
我們測試了一系列 LLM,發現它們難以形成和更新機率信念。我們進一步發現,透過讓 LLM 接觸用戶與貝氏助手(一個實施最佳機率信念更新策略的模型)之間的互動來持續訓練,可以顯著提高 LLM 逼近機率推理的能力。
雖然我們第一個實驗的發現指出了特定 LLM 的局限性,但隨後微調實驗的積極結果可以被視為對更廣泛的 LLM「後訓練」(Post-training)範式實力的證明。透過在執行任務的最佳策略演示上訓練 LLM,我們能夠顯著提高其表現,這表明它們學會了逼近演示中所展示的機率推理策略。LLM 能夠將這種策略推廣到難以在符號模型中明確編碼的領域,展示了將經典符號模型蒸餾到神經網路中的強大力量。
快速連結
其他感興趣的貼文

2026 年 2 月 10 日

2026 年 2 月 5 日

2026 年 2 月 3 日