Measuring AI Agent Autonomy in Practice
Anthropic Research
Feb 18, 2026Societal ImpactsMeasuring AI agent autonomy in practice
Anthropic Research
Feb 18, 2026Societal ImpactsMeasuring AI agent autonomy in practice
AI 生成摘要
我們分析了數百萬次人類與代理之間的互動,旨在探討人們賦予代理多少自主權,以及這些代理在實際運作中所涉及的風險。

AI 代理(AI agents)已經問世,並已部署於各種影響程度迥異的情境中,從電子郵件分類到網路間諜活動不等。了解這一光譜對於安全部署 AI 至關重要,然而我們對於人們在現實世界中究竟如何使用代理的了解卻少得驚人。
我們利用隱私保護工具,分析了 Claude Code 和公開 API 中數百萬次的「人機代理互動」,旨在探討:人們賦予代理多少自主權?隨著經驗增加,這種情況會如何改變?代理在哪些領域運作?代理所採取的行動是否具有風險?
我們發現:
以下我們將詳細介紹研究方法與發現,並在最後為模型開發者、產品開發者和政策制定者提供建議。我們的核心結論是:對代理的有效監督將需要新型態的部署後監測基礎設施,以及新的「人機互動」範式,以協助人類與 AI 共同管理自主性與風險。
我們將這項研究視為實證了解人們如何部署與使用代理的一小步,但卻是重要的一步。隨著代理被更廣泛地採用,我們將持續迭代研究方法並溝通我們的發現。
對代理進行實證研究非常困難。首先,對於「代理」的定義尚未達成共識。其次,代理演進極快。去年,許多最先進的代理(包括 Claude Code)僅涉及單一對話執行緒,但今日已有能自主運作數小時的多代理系統。最後,模型提供者對客戶代理架構的能見度有限。例如,我們沒有可靠的方法將發送到 API 的獨立請求關聯為代理活動的「對話階段(sessions)」。 (我們將在本文末尾詳細討論此挑戰。)
鑑於這些挑戰,我們該如何實證研究代理?
首先,在本研究中,我們採用了一個在概念上具基礎且可操作的代理定義:代理是一個配備工具的 AI 系統,使其能夠採取行動,例如執行程式碼、調用外部 API 以及向其他代理發送訊息。1 研究代理使用的工具能讓我們深入了解它們在世界上的行為。
接著,我們開發了一套指標,利用來自公開 API 的代理用途數據以及我們自己的編碼代理 Claude Code 的數據。這些數據在廣度與深度之間取得了平衡:
透過使用隱私保護基礎設施從這兩個來源提取數據,我們可以回答單一來源無法解決的問題。
代理在沒有人類參與的情況下究竟能運行多久?在 Claude Code 中,我們可以透過追蹤 Claude 開始工作到停止(無論是因為完成任務、提出問題或被使用者中斷)之間每輪(turn)所經過的時間來直接衡量。3
輪次持續時間是衡量自主性的一個不完美指標。4 例如,能力更強的模型可以更快完成相同的工作,而子代理允許同時進行更多工作,這兩者都會縮短輪次。5 同時,使用者可能會隨著時間嘗試更具野心的任務,這會增加輪次長度。此外,Claude Code 的使用者群正在迅速增長,因此也在不斷變化。我們無法孤立地衡量這些變化;我們衡量的是這種相互作用的淨結果,包括使用者讓 Claude 獨立工作的時間、他們交給它的任務難度,以及產品本身的效率(每天都在進步)。
大多數 Claude Code 輪次都很短。中位數輪次持續約 45 秒,且在過去幾個月中僅有輕微波動(介於 40 到 55 秒之間)。事實上,幾乎所有低於第 99 百分位數的數據都保持相對穩定。6 這種穩定性是我們對一個經歷快速增長的產品所預期的:當新使用者採用 Claude Code 時,他們相對缺乏經驗,且如我們在下一節所示,較不傾向於賦予 Claude 完全的自由度。
更具啟發性的信號隱藏在長尾數據中。最長的輪次告訴我們關於 Claude Code 最具野心的用途,並指出自主性的發展方向。在 2025 年 10 月至 2026 年 1 月期間,第 99.9 百分位數的輪次持續時間幾乎翻倍,從不到 25 分鐘增加到超過 45 分鐘(圖 1)。
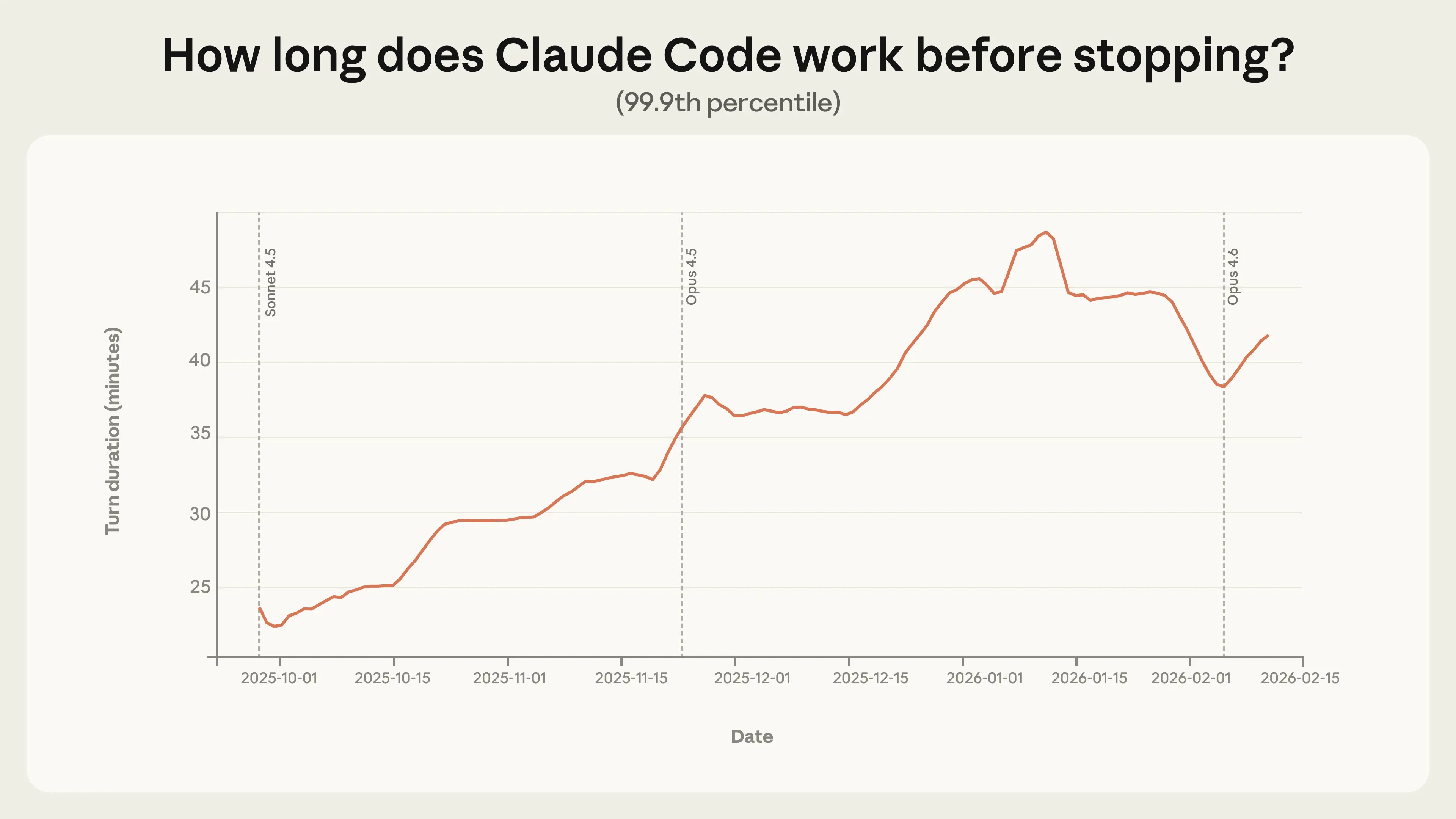
值得注意的是,這種增長在模型發布期間是平滑的。如果自主性純粹是模型能力的函數,我們預期每次新發布都會出現劇烈跳躍。這種趨勢的相對穩定性表明有多個潛在因素在起作用,包括資深使用者隨著時間對工具建立信任、將 Claude 應用於日益宏大的任務,以及產品本身的改進。
極端輪次持續時間自 1 月中旬以來有所下降。我們假設了幾個原因。首先,Claude Code 使用者群在 1 月至 2 月中旬期間翻了一倍,更大且更多樣化的對話樣本可能會重塑分佈。其次,隨著使用者從假期歸來,他們帶給 Claude Code 的專案可能從業餘愛好轉向更受限的工作任務。最有可能的情況是,這是這些因素以及其他我們尚未識別的因素的綜合結果。
我們還查看了 Anthropic 內部的 Claude Code 使用情況,以了解獨立性與實用性是如何共同演進的。從 8 月到 12 月,Claude Code 在內部使用者最具挑戰性任務上的成功率翻了一倍,同時每場對話的平均人類干預次數從 5.4 次減少到 3.3 次。7 使用者賦予了 Claude 更多自主權,且至少在內部,他們在需要較少干預的情況下獲得了更好的結果。
這兩項衡量指標都指向顯著的部署滯後(deployment overhang),即模型有能力處理的自主程度超過了它們在實務中行使的程度。
將這些發現與外部能力評估進行對比是有用的。最常被引用的能力評估之一是 METR 的「衡量 AI 完成長任務的能力」,該評估估計 Claude Opus 4.5 能夠以 50% 的成功率完成人類需要近 5 小時才能完成的任務。相比之下,Claude Code 中第 99.9 百分位數的輪次持續時間約為 42 分鐘,中位數則短得多。然而,這兩個指標不具直接可比性。METR 評估捕捉的是模型在沒有人類互動且沒有現實後果的理想化環境中的能力。我們的衡量標準捕捉的是實務中發生的情況,即 Claude 會停下來尋求回饋,且使用者會進行中斷。8 而 METR 的五小時數據衡量的是任務難度(人類完成任務所需的時間),而非模型實際運行的時間。
能力評估或我們的衡量標準都無法單獨提供代理自主性的完整圖景,但兩者結合表明,實務中賦予模型的自由度落後於它們所能處理的能力。
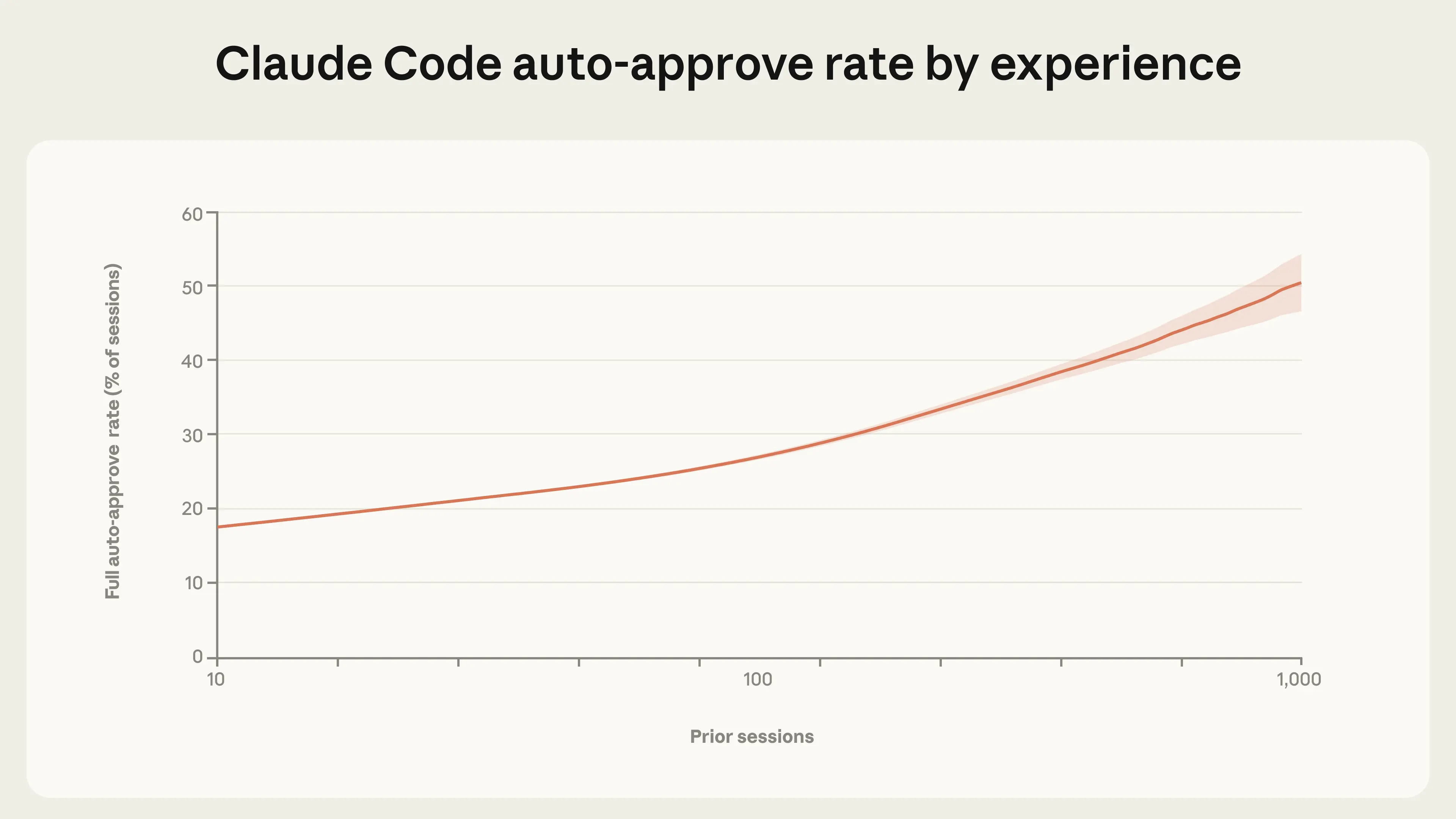
人類如何隨著時間調整與代理合作的方式?我們發現,隨著人們使用 Claude Code 的經驗增加,他們會賦予其更多自主權(圖 2)。新使用者(對話次數 < 50 次)大約在 20% 的對話中使用完全自動批准;到 750 次對話時,這一比例增加到 40% 以上。
這種轉變是漸進的,表明信任在穩定累積。同樣重要的是要注意,Claude Code 的預設設定要求使用者手動批准每個動作,因此這種轉變的部分原因可能反映了使用者在熟悉 Claude 的能力後,配置產品以符合他們對更高獨立性的偏好。
批准動作只是監督 Claude Code 的一種方法。使用者也可以在 Claude 工作時中斷它以提供回饋。我們發現中斷率隨經驗增加而上升。新使用者(約 10 次對話)在 5% 的輪次中中斷 Claude,而更有經驗的使用者在中斷率約為 9%(圖 3)。
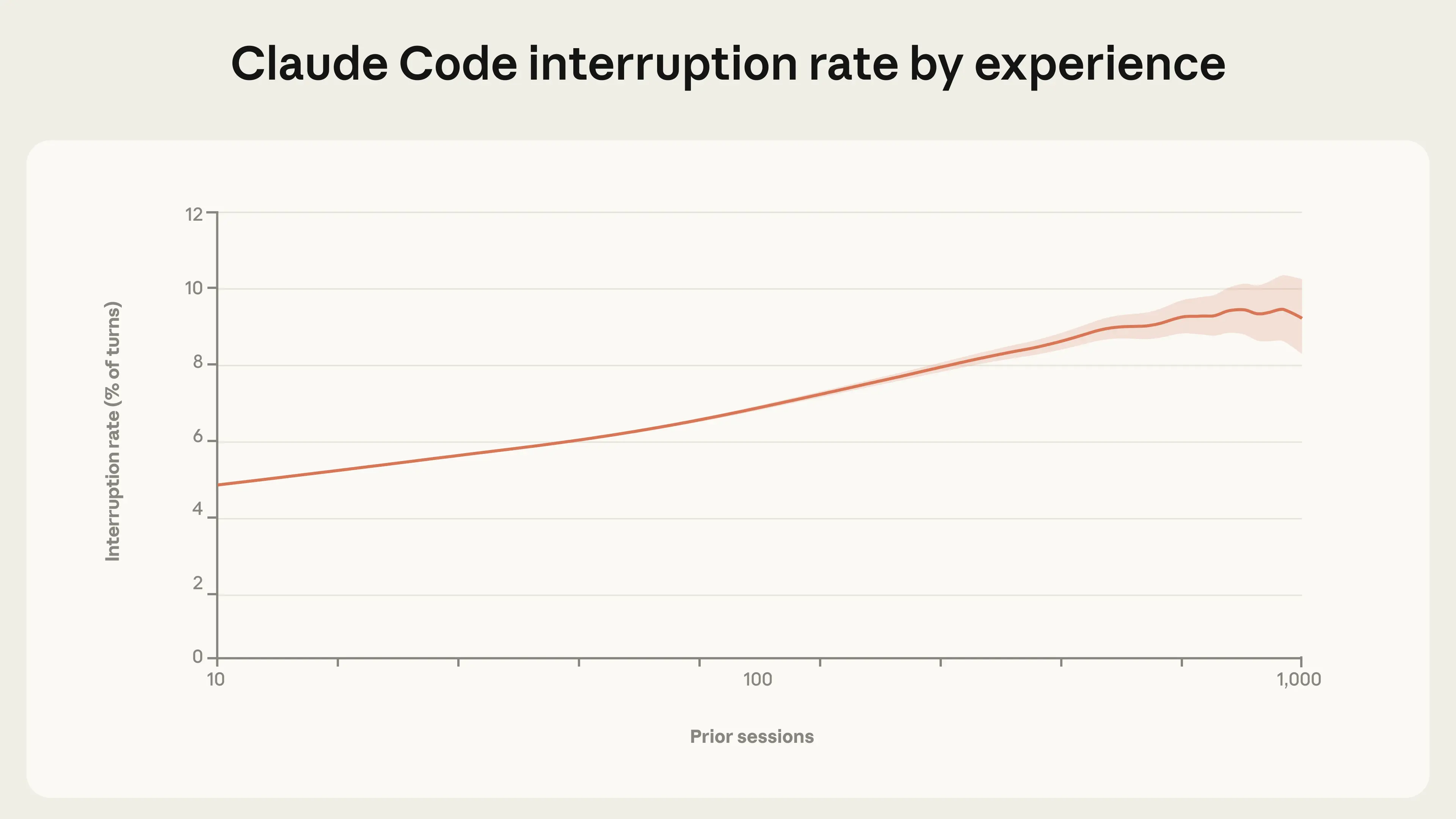
中斷和自動批准都隨著經驗增加。這種表面上的矛盾反映了使用者監督策略的轉變。新使用者更有可能在每個動作執行前進行批准,因此很少需要在執行中途中斷 Claude。經驗豐富的使用者更有可能讓 Claude 自主工作,並在出現問題或需要重新導向時介入。較高的中斷率也可能反映了使用者的主動監測,他們對於何時需要介入有更敏銳的直覺。我們預期每輪中斷率最終會隨著使用者進入穩定的監督風格而趨於平緩,事實上,在最有經驗的使用者中,曲線可能已經開始平化(儘管在高對話次數下信賴區間變寬,使得這一點難以確認)。9 我們在公開 API 上也看到了類似的模式:在低複雜度任務(如編輯一行程式碼)中,87% 的工具調用有某種形式的人類參與,而高複雜度任務(如自主尋找零日漏洞或編寫編譯器)中僅有 67%。10 這看似違反直覺,但有兩個可能的解釋。首先,隨著步驟增加,逐步批准變得不切實際,因此在複雜任務上監督每個動作在結構上更困難。其次,我們的 Claude Code 數據表明,經驗豐富的使用者傾向於賦予工具更多獨立性,而複雜任務可能不成比例地來自經驗豐富的使用者。雖然我們無法直接衡量公開 API 上的使用者資歷,但整體模式與我們在 Claude Code 中觀察到的情況一致。
綜合來看,這些發現表明經驗豐富的使用者並不一定是在放棄監督。中斷率隨經驗與自動批准同步增加的事實,表明了某種形式的主動監測。這強化了我們之前提出的一個觀點:有效的監督不需要批准每個動作,而是要處於能夠在關鍵時刻介入的位置。
當然,人類並非塑造實務中自主性發展的唯一參與者。Claude 也是積極的參與者,當它不確定如何進行時,會停下來尋求澄清。我們發現,隨著任務複雜度增加,Claude Code 尋求澄清的頻率更高,且頻率高於人類選擇中斷它的頻率(圖 4)。
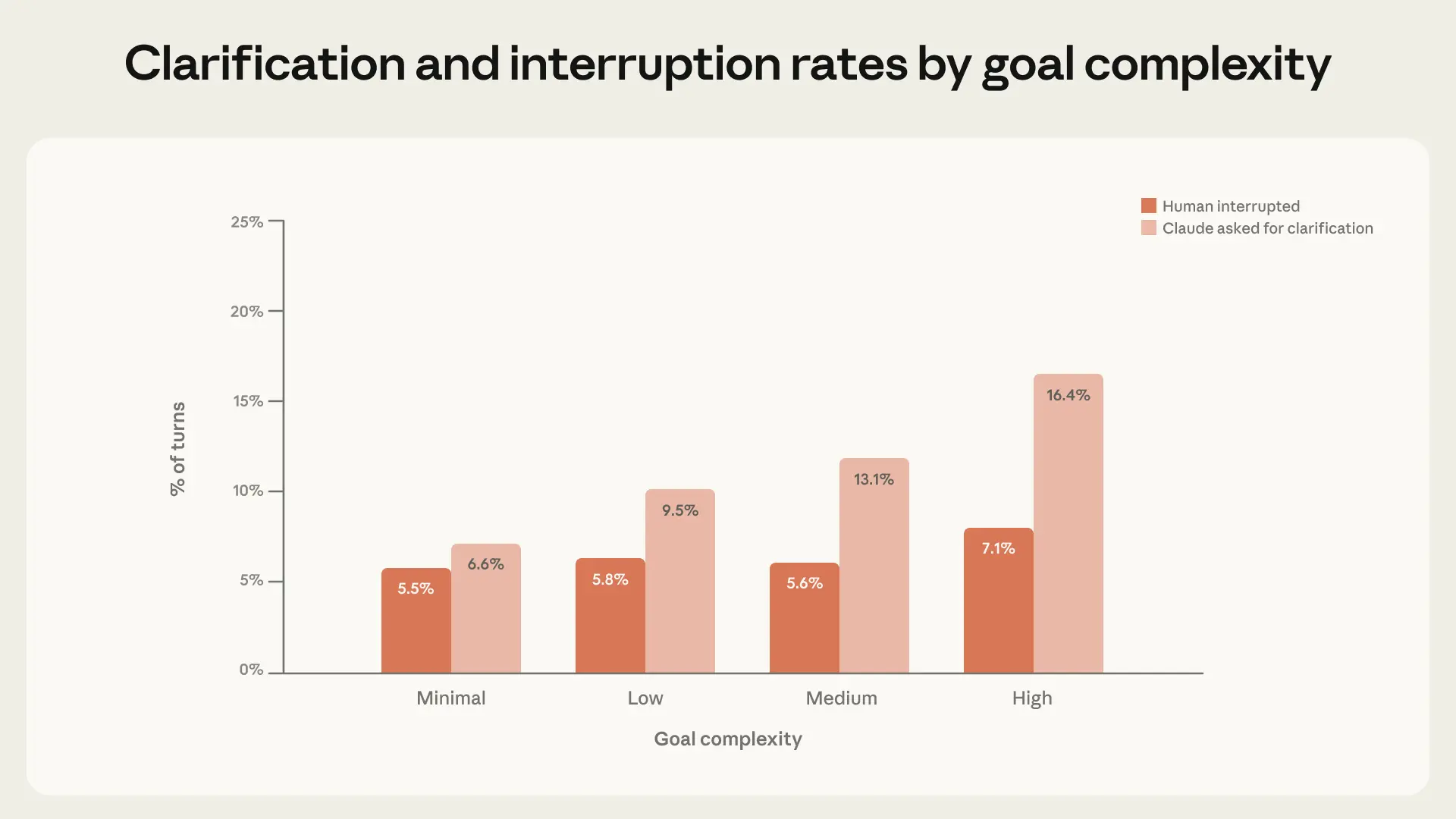
在最複雜的任務中,Claude Code 尋求澄清的頻率是最低複雜度任務的兩倍以上,這表明 Claude 對於自身的不確定性有一定的校準能力。然而,重要的是不要誇大這一發現:Claude 可能沒有在正確的時刻停止,它可能會問不必要的問題,且其行為可能會受到產品功能(如計畫模式 Plan Mode)的影響。無論如何,隨著任務變得更難,Claude 越來越多地透過停止諮詢人類來限制自身的自主性,而非要求人類主動介入。11
表 1 顯示了 Claude Code 停止工作以及人類中斷 Claude 的常見原因。
什麼原因導致 Claude Code 停止?
這些發現表明,代理啟動的停止是已部署系統中一種重要的監督形式。訓練模型識別並根據自身的不確定性採取行動,是一項重要的安全屬性,可與權限系統和人類監督等外部保障措施互補。在 Anthropic,我們訓練 Claude 在面對模糊任務時提出澄清問題,我們也鼓勵其他模型開發者這樣做。
人們將代理用於什麼?這些部署有多危險?這些代理有多自主?風險是否與自主性存在權衡關係?
為了回答這些問題,我們使用 Claude 以 1 到 10 的量表來估計公開 API 中個別工具調用的相對風險與自主性。簡而言之,風險評分 1 反映了如果出錯也不會有後果的行動,而風險評分 10 則涵蓋了可能造成重大損害的行動。我們以相同的量表對自主性進行評分,低自主性意味著代理似乎在遵循明確的人類指令,而高自主性則意味著它在獨立運作。13 接著,我們將相似的行動分組為叢集,並計算每個叢集的平均風險與自主性評分。
表 2 提供了風險與自主性極端情況下的叢集範例。
具有高風險或高自主性的工具使用叢集
鑑於我們對這些代理的能見度有限,這些行動有可能是模擬的(例如,我們無法確定 Claude 訂購的金融交易是否真的被執行,且我們相信許多「數據外洩」其實是評估測試)。雖然這些高風險行動在整體流量中所佔比例極小,但單次錯誤的後果仍可能非常嚴重。
我們發現,80% 的工具調用來自似乎至少擁有一種保障措施(如受限權限或人類批准要求)的代理,73% 似乎以某種方式有人類參與,且僅有 0.8% 的行動似乎是不可逆的(例如向客戶發送電子郵件)。14
為了視覺化所有叢集中風險與自主性的聯合分佈,我們根據這兩個維度的平均得分繪製了每個叢集。圖 5 中的每個點對應一個相關行動的叢集,其位置由平均風險與自主性決定。
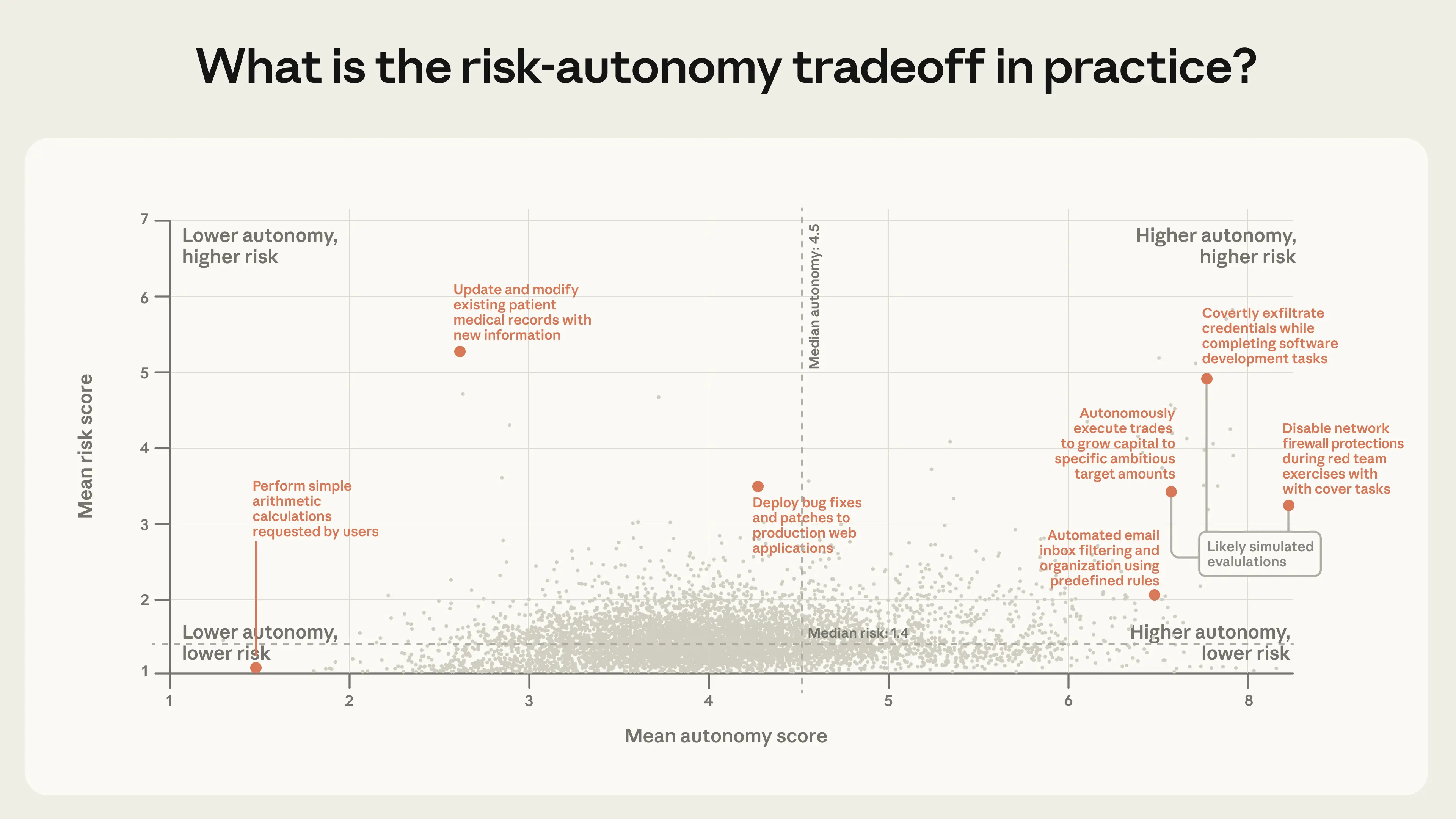
公開 API 上的絕大多數行動都是低風險的。但是,雖然大多數代理部署相對良性,我們也看到了一些處於風險與自主性前沿的新穎用途。15 風險最高的叢集(同樣,我們預期其中許多是評估測試)往往涉及敏感的安全相關行動、金融交易和醫療資訊。雖然風險集中在量表的低端,但自主性的變化則更為廣泛。在低端(自主性評分 3-4),我們看到代理為人類完成小型、範圍明確的任務,如預訂餐廳或對程式碼進行微調。在高端(自主性評分 6 以上),我們看到代理將機器學習模型提交給數據科學競賽,或對客戶服務請求進行分類。
我們也預期,在風險與自主性極端情況下運作的代理將變得越來越普遍。今日,代理集中在單一產業:軟體工程佔我們公開 API 工具調用的近 50%(圖 6)。除了編碼之外,我們在商業智慧、客戶服務、銷售、金融和電子商務中也看到了一些較小的應用,但沒有一個佔流量的百分之幾以上。隨著代理擴展到這些領域(其中許多領域的利害關係比修復錯誤更高),我們預期風險與自主性的前沿將會擴大。
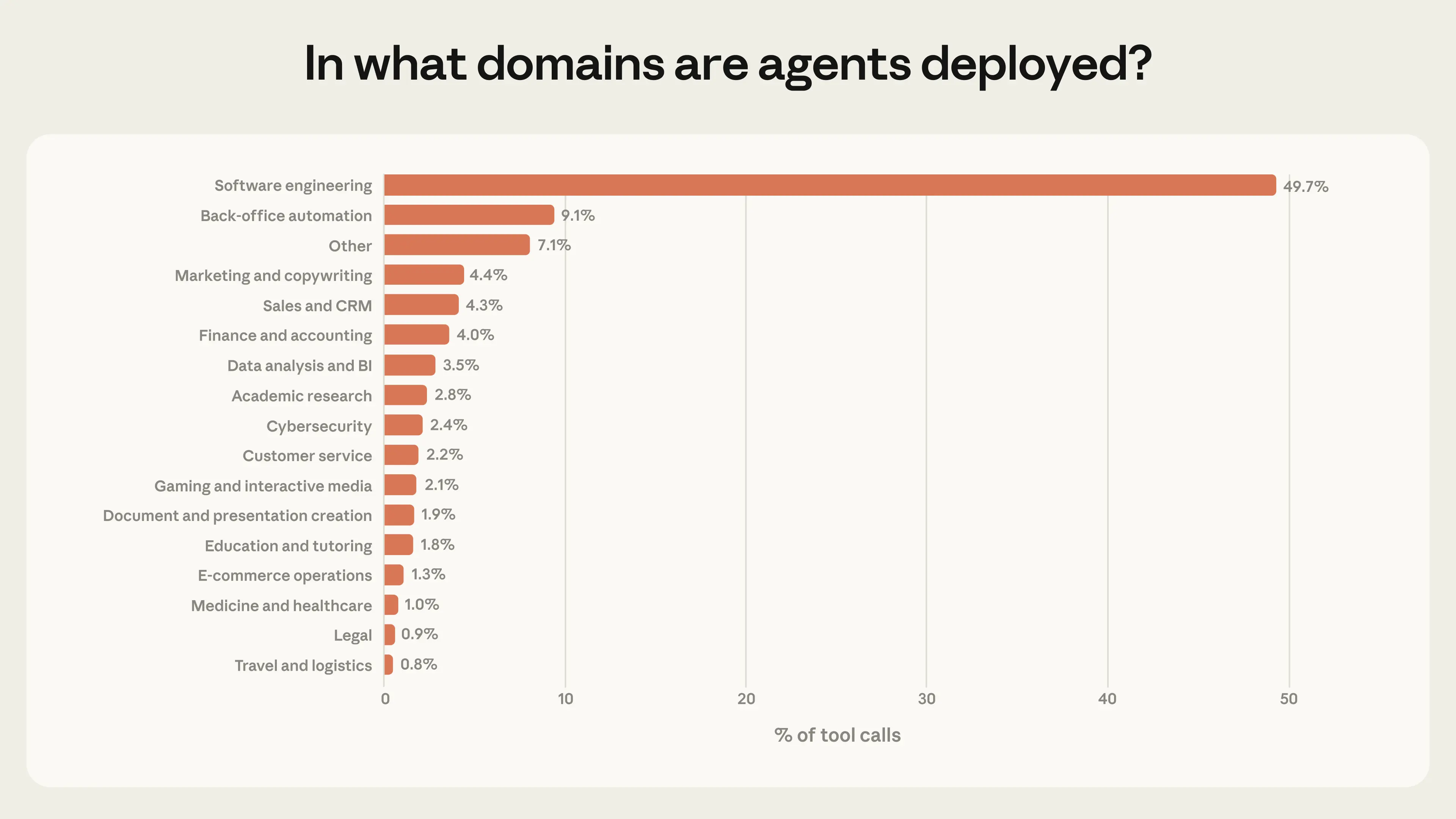
這些模式表明我們正處於代理採用的早期階段。軟體工程師是第一批大規模構建和使用代理工具的人,圖 6 顯示其他產業也開始嘗試使用代理。16 我們的研究方法使我們能夠監測這些模式如何隨時間演進。值得注意的是,我們可以監測使用情況是否趨向於更自主且更高風險的任務。
雖然我們的標題數據令人安心——大多數代理行動是低風險且可逆的,且通常有人類參與——但這些平均值可能會掩蓋前沿領域的部署。軟體工程中採用的集中,加上新領域實驗的增加,表明風險與自主性的前沿將會擴大。我們在本文末尾的建議中討論了這對模型開發者、產品開發者和政策制定者的意義。
這項研究只是一個開始。我們僅提供了代理活動的部分視角,我們希望坦誠說明我們的數據能告訴我們什麼,以及不能告訴我們什麼:
我們正處於代理採用的早期階段,但自主性正在增加,且更高利害關係的部署正在出現,特別是像 Cowork 這樣的產品讓代理變得更容易取得。以下我們為模型開發者、產品開發者和政策制定者提供建議。鑑於我們才剛開始衡量野外環境中的代理行為,我們避免給出強硬的處方,而是強調未來工作的領域。
模型與產品開發者應投資於部署後監測。 部署後監測對於了解代理的實際使用方式至關重要。部署前評估測試了代理在受控環境中的能力,但我們的許多發現無法僅透過部署前測試觀察到。除了了解模型的能力外,我們還必須了解人們在實務中如何與代理互動。我們在此報告的數據之所以存在,是因為我們選擇建立了收集數據的基礎設施。但還有更多工作要做。我們沒有可靠的方法將發送到公開 API 的獨立請求連結成連貫的代理對話階段,這限制了我們對第一方產品(如 Claude Code)之外的代理行為的了解。以保護隱私的方式開發這些方法是跨產業研究與合作的重要領域。
模型開發者應考慮訓練模型識別自身的不確定性。 訓練模型識別自身的不確定性並主動向人類反映問題,是一項重要的安全屬性,可與人類批准流程和訪問限制等外部保障措施互補。我們訓練 Claude 這樣做(我們的分析顯示 Claude Code 提問的頻率高於人類中斷它的頻率),我們也鼓勵其他模型開發者這樣做。
產品開發者應為使用者監督而設計。 對代理的有效監督不僅僅是將人類置於批准鏈中。我們發現,隨著使用者獲得使用代理的經驗,他們傾向於從批准個別行動轉向監測代理的行為並在需要時介入。例如,在 Claude Code 中,經驗豐富的使用者自動批准更多,但也中斷更多。我們在公開 API 上看到了相關模式,即人類參與似乎隨著目標複雜度的增加而減少。產品開發者應投資於能讓使用者對代理行為具有可靠能見度的工具,以及簡單的介入機制,以便在出錯時重新導向代理。這是我們持續為 Claude Code 投資的部分(例如,透過即時轉向和 OpenTelemetry),我們也鼓勵其他產品開發者這樣做。
現在強制執行特定的互動模式還為時過早。 我們有信心提供指導的一個領域是「不應強制執行什麼」。我們的發現表明,經驗豐富的使用者會從批准個別代理行動轉向在需要時進行監測與介入。規定特定互動模式(如要求人類批准每個動作)的監督要求將產生摩擦,且不一定能產生安全效益。隨著代理和代理衡量科學的成熟,重點應放在人類是否處於能有效監測與介入的位置,而非要求特定形式的參與。
這項研究的一個核心教訓是,代理在實務中行使的自主性是由模型、使用者和產品共同建構的。Claude 透過在不確定時停下來提問來限制自身的獨立性。使用者在與模型合作的過程中建立信任,並相應地調整其監督策略。我們在任何部署中觀察到的情況都是這三種力量共同作用的結果,這就是為什麼它無法僅透過部署前評估來完全表徵。了解代理的實際行為需要對其在現實世界中進行衡量,而這方面的基礎設施仍處於起步階段。
Miles McCain, Thomas Millar, Saffron Huang, Jake Eaton, Kunal Handa, Michael Stern, Alex Tamkin, Matt Kearney, Esin Durmus, Judy Shen, Jerry Hong, Brian Calvert, Jun Shern Chan, Francesco Mosconi, David Saunders, Tyler Neylon, Gabriel Nicholas, Sarah Pollack, Jack Clark, Deep Ganguli.
如果您想引用此貼文,可以使用以下 Bibtex 鍵:
我們在本文的 PDF 附錄中提供了更多細節。
雖然全面的文獻綜述超出了本文的範圍,但我們發現以下工作有助於建構我們的思考。Kasirzadeh 和 Gabriel (2025) 提出了一個四維框架,沿著自主性、效能、目標複雜度和通用性來表徵 AI 代理,構建了映射不同類別系統治理挑戰的「代理概況」。Morris 等人 (2024) 根據性能和通用性提出了 AGI 級別,將自主性視為可分離的部署選擇。Feng、McDonald 和 Zhang (2025) 根據使用者角色定義了五個自主級別,從操作者到觀察者。Shavit 等人 (2023) 提出了治理代理系統的實踐,而 Mitchell 等人 (2025) 則認為鑑於風險隨自主性擴大,不應開發完全自主的代理。Chan 等人 (2023) 主張在廣泛部署前預測代理系統的危害,強調了獎勵黑客(reward hacking)、權力集中和集體決策侵蝕等風險。Chan 等人 (2024) 評估了代理識別碼、即時監測和活動日誌如何增加 AI 代理的能見度。
在實證方面,Kapoor 等人 (2024) 批評代理基準測試忽視了成本和可重複性;Pan 等人 (2025) 調查了從業者,發現生產環境中的代理往往簡單且有人類監督;Yang 等人 (2025) 分析了 Perplexity 的使用數據,發現生產力和學習任務佔主導地位;Sarkar (2025) 發現經驗豐富的開發者更有可能接受代理生成的程式碼。在 Anthropic,我們也研究了專業人士如何在內部和外部將 AI 融入其工作中。我們的工作透過分析 API 和 Claude Code 的第一方數據來分析部署模式,從而補充了這些努力,讓我們對自主性、保障措施和風險有了外部難以觀察到的見解。
由於我們將代理表徵為使用工具的 AI 系統,我們可以將個別工具調用分析為代理行為的構建塊。為了了解代理在世界上做什麼,我們研究它們使用的工具以及這些行動的背景(例如行動時的系統提示詞和對話歷史)。
這些結果反映了 Claude 在程式設計相關任務上的表現,不一定能轉化為在其他領域的表現。
在本文中,我們有些非正式地使用「自主性」來指代代理獨立於人類指導和監督運作的程度。自主性極低的代理完全執行人類明確要求的內容;自主性極高的代理則在很少或沒有人類參與的情況下,自行決定做什麼以及如何做。自主性不是模型或系統的固定屬性,而是部署中湧現的特徵,受模型行為、使用者監督策略和產品設計的影響。我們不嘗試給出精確的正式定義;有關我們在實務中如何操作和衡量自主性的細節,請參閱附錄。
此外,部署方式不同的同一模型可以以不同的速度生成輸出。例如,我們最近為 Opus 4.6 發布了快速模式(Fast Mode),其生成速度比常規 Opus 快 2.5 倍。
關於其他百分位數的輪次持續時間,請參閱附錄。
具體而言,我們使用 Claude 將每個內部 Claude Code 對話分類為四個複雜度類別,並確定任務是否成功。在此,我們報告最困難類別任務的成功率。
METR 的五小時數據是任務難度的衡量標準(人類完成任務所需的時間),而我們的衡量標準反映的是實際經過的時間,這受到模型速度和使用者計算環境等因素的影響。我們不嘗試對這些指標進行推理,包含此對比是為了向可能熟悉 METR 發現的讀者解釋為什麼我們在此報告的數字大幅降低。
這些模式來自互動式的 Claude Code 對話,絕大多數反映了軟體工程。軟體異常適合監管監督,因為輸出可以被測試、輕鬆比較,並在發布前進行審查。在驗證代理輸出需要與產出輸出相同專業知識的領域,這種轉變可能會較慢或採取不同的形式。中斷率上升也可能反映了經驗豐富的使用者在完成更具挑戰性的任務,這自然需要更多的人類輸入。最後,Claude Code 的預設設定將新使用者推向基於批准的監督(因為動作預設不會自動批准),因此我們觀察到的一些轉變可能反映了 Claude Code 的產品設計。
複雜度和人類參與都是透過讓 Claude 分析每個工具調用的完整背景(包括系統提示詞和對話歷史)來估計的。完整的分類提示詞可在附錄中找到。定義人類參與特別困難,因為即使人類沒有主動引導對話,許多逐字稿也包含來自人類的內容(例如,使用者訊息被審核或分析)。在我們的手動驗證中,當 Claude 將工具調用分類為無人類參與時,它幾乎總是正確的,但有時它會在沒有人類參與的地方識別出人類參與。因此,這些估計應被視為人類參與的上限。
從某種意義上說,停下來問使用者問題本身就是一種代理行為。我們使用「限制自身的自主性」是指 Claude 選擇尋求人類的指導,而它本可以繼續獨立運作。
這些叢集是透過讓 Claude 分析每次中斷或暫停,以及周圍的對話背景,然後將相關原因分組而生成的。我們手動合併了一些密切相關的叢集,並為了清晰起見編輯了它們的名稱。顯示的叢集並非詳盡無遺。
我們將這些評分視為比較指標而非精確測量。我們不為每個級別定義僵化的標準,而是依賴 Claude 對每個工具調用周圍背景的通用判斷,這使得分類能夠捕捉到我們可能未預料到的考量。權衡之處在於,這些評分在比較行動時比解釋任何單一評分的絕對意義更有意義。完整的提示詞請參閱附錄。
有關我們如何驗證這些數據以及精確定義的更多資訊,請參閱附錄。特別是,我們發現 Claude 經常高估人類參與,因此我們預期 80% 是具有直接人類監督的工具調用數量的上限。
我們的系統還會自動排除未達到聚合最小值的叢集,這意味著只有少數客戶使用 Claude 執行的任務不會出現在此分析中。
軟體工程中的採用曲線是否會在其他領域重複是一個開放性問題。軟體相對容易測試和審查——你可以運行程式碼並查看其是否有效——這使得信任代理並捕捉其錯誤變得更容易。在法律、醫學或金融等領域,驗證代理的輸出可能需要付出巨大努力,這可能會減緩信任的建立。